파이썬을 활용한 웹 크롤링 #3
네이버 영화 감상평 수집하기
✔ 크롤링 전 웹사이트 분석
- 목표 : 네이버 영화 접속 -> 평점 데이터 가져오기
-
겨울 왕국 2 검색
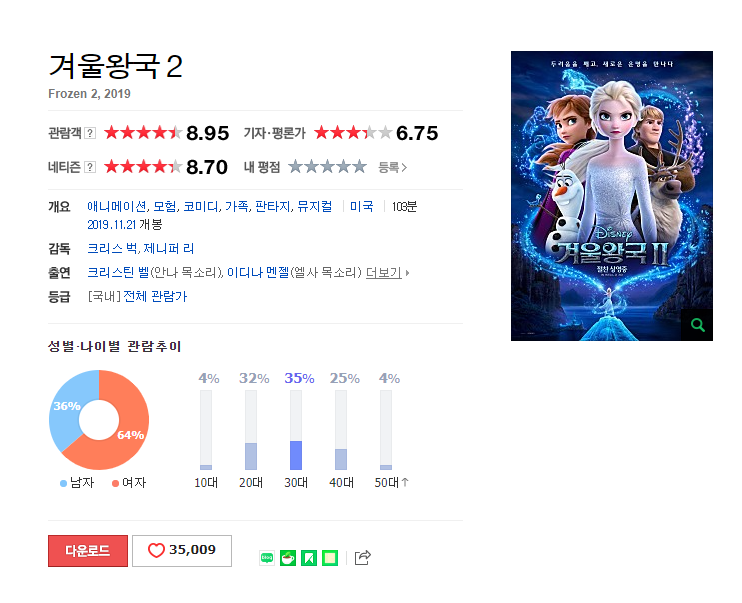
-
평점 -> 더보기
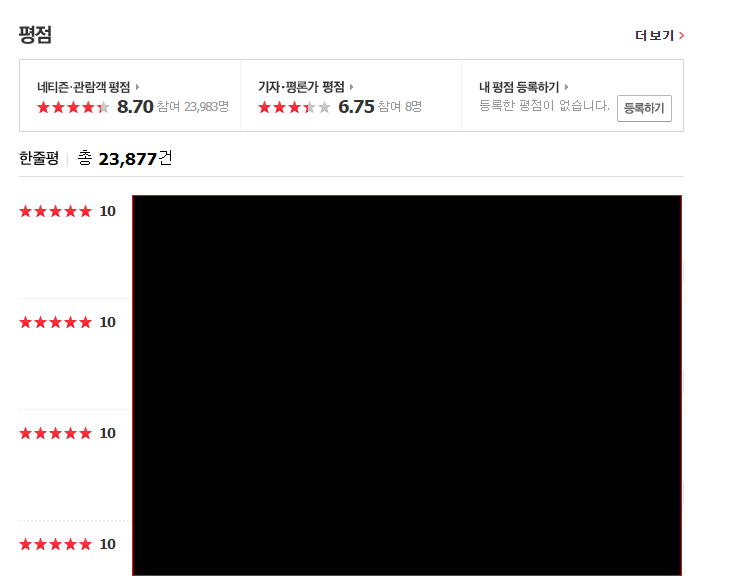
-
shift + click 다른 형식의 창이 뜸
-
F12
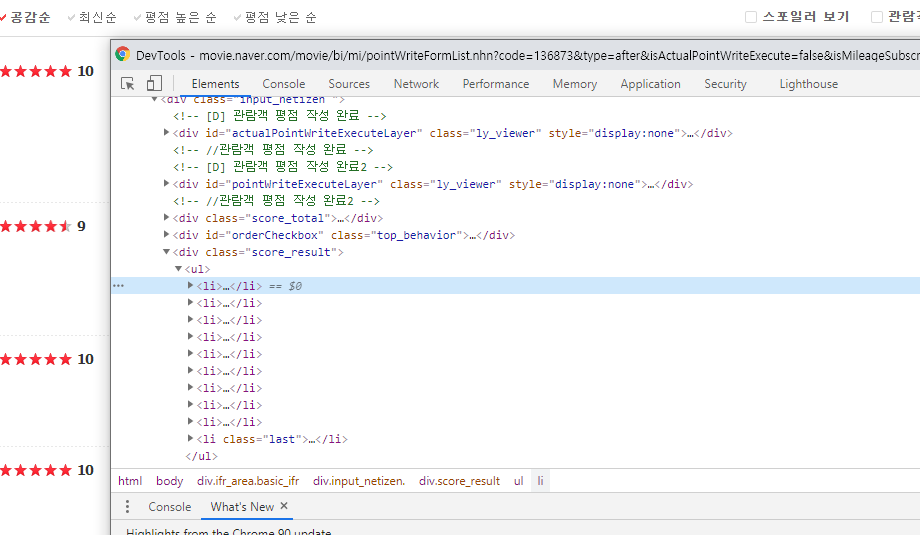
-
span 태그의 filtered_ment[1] id 값 => 대괄호 값은 순서대로 바뀜 ex 1,2,3,4 ...


✔ 실제 구현 해보기
pip install urllib3 pip install bs4 ----------------------------------- # bs4 install 에러의 경우 You should consider upgrading via the 'c:\users\lg\appdata\local\programs\python\python39\python.exe -m pip install --upgrade pip' command. # 간단히 pip install --upgrade pip 만 하면 된다
from urllib.request import urlopen from bs4 import BeautifulSoup url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page=1' html = urlopen(url) soup = BeautifulSoup(html,'html.parser') ------------------------------------------------------------------ # urlopen 에러가 나는 경우! > urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed # 다음과 같이 한다. import ssl context = ssl._create_unverified_context() url = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page=1' html = urlopen(url, context=context) soup = BeautifulSoup(html,'html.parser')
- 아래의 태그안 속성 값들을 활용한다.

review = soup.find('span',{'id':'_filtered_ment_0'}) review.get_text().strip() > '스포 때문에 메인 넘버를 into the unknown으로 정한 느낌... 진짜 하이라이트는 show yourself 엄마와 함께 부르는 듀엣씬입니다. 이 장면만으로도 충분히 영화관에서 볼 가치가 있어요. 보고 난 ...'
- for 문을 활용해서 10개의 리뷰를 가져오기
for i in range(10): review = soup.find('span',{'id':f'_filtered_ment_{i}'}) print(f'{i+1} 번째 리뷰') print(review.get_text().strip()) print('--------------------') > 1 번째 리뷰 스포 때문에 메인 넘버를 into the unknown으로 정한 느낌... 진짜 하이라이트는 show yourself 엄마와 함께 부르는 듀엣씬입니다. 이 장면만으로도 충분히 영화관에서 볼 가치가 있어요. 보고 난 ... -------------------- 2 번째 리뷰 디즈니가 얼마나 팬을 생각하는지 알수있는 영화...1편 아동용 영화에서 1편을 보고 자란 성인들까지 보는데 재미를 느낄수 있게 만드는 2편 -------------------- 3 번째 리뷰 올라프가 다한 영화입니다 -------------------- 4 번째 리뷰 겨울왕국 2 역시 디즈니 입니다.영상미 하나만 가지고도 정말 인생 애니작을 본거에요 와 1편에서 렛잇고 열풍 이었다면 2편은 노래 영상 감동 스토리 모두를 갖추었네요 1편보다 더 훌륭합니다.꼭보세요 정말 최고네요. -------------------- 5 번째 리뷰 렛잇고가 대박쳐서 그런지 이번에 노래가 과하게 많다. -------------------- 6 번째 리뷰 이토록 완벽한 속편이라니. 여전히 아름답고 황홀한 스케일과 OST. '역시 믿고 보는 디즈니' 라는 말이 절로 나온다. 그렇게 부모와 어른이들의 통장은 또 한번 굿즈로 탈탈탈... -------------------- 7 번째 리뷰 역시 겨울왕국..기대한만큼 만족스러웠음ㅜㅜ엘사 미모에 치이고 OST에 한번 더 치이고..한번 더 볼 생각임!! -------------------- 8 번째 리뷰 스토리는 나쁘지 않았는데 소재가 어둡다보니, 겨울왕국1같은 밝고 신나는 ost가 적은듯... 그리고 ost가 귀에 남을만한게 없다는 아쉬움 -------------------- 9 번째 리뷰 엘사가 성장한 모습으로 행복한 길을선택한것 같아 너무 감동이었음ㅠㅠ진짜 너무 재밌다 -------------------- 10 번째 리뷰 크리스토프의 뮤직비디오 인상깊었어요 --------------------
- 페이지를 순환하며 리뷰 크롤링 하기(1 page ~ 10 page)
review_list = [] for page in range(1,11): url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={page}' html = urlopen(url) soup = BeautifulSoup(html,'html.parser') for i in range(10): review = soup.find('span',{'id':f'_filtered_ment_{i}'}) review = review.get_text().strip() review_list.append(review) review_list >['올라프의 1편요약이 기가맥힙니다', '크리스토퍼 뮤비에서 좀 흠칫함', '미래가 보이지 않을 때는 지금 해야할 일을 해야 해', '나는 개인적으로 2편이 더 좋았음. 더 깊어진 스토리에 아름다워진 영상미. 한번 더 볼 의향 있음.', '엘사옷 보고 어머니들 긴장하는 영화', '애기들 울고 떠들고 하는거 보고 엘사 마법으로 얼릴뻔 했네요', '크리스토퍼 혹시 과거에 뮤비찍어본적 있니?왜 이렇게 잘해??...순간 당황했잖아', '백마탄 엘사님 Show yourself 장면 진짜 개오집니다 단언컨데 제2의 렛잇고는 into the unknown 아니고 Show yourself 입니다', '엘사 물 속에서 말타고 나올 때 대박ㅋㅋㅋㅋ', '겨울왕국 역시는 역시였다. OST도 1편만큼이나 중독성있다고 생각함ㅋㅋㅋ1편만큼 존잼임', '스포 때문에 메인 넘버를 into the unknown으로 정한 느낌... 진짜 하이라이트는 show yourself 엄마와 함께 부르는 듀엣씬입니다. 이 장면만으로도 충분히 영화관에서 볼 가치가 있어요. 보고 난 ...', '디즈니가 얼마나 팬을 생각하는지 알수있는 영화...1편 아동용 영화에서 1편을 보고 자란 성인들까지 보는데 재미를 느낄수 있게 만드는 2편', '올라프가 다한 영화입니다', '겨울왕국 2 역시 디즈니 입니다.영상미 하나만 가지고도 정말 인생 애니작을 본거에요 와 1편에서 렛잇고 열풍 이었다면 2편은 노래 영상 감동 스토리 모두를 갖추었네요 1편보다 더 훌륭합니다.꼭보세요 정말 최고네요.', '렛잇고가 대박쳐서 그런지 이번에 노래가 과하게 많다.', "이토록 완벽한 속편이라니. 여전히 아름답고 황홀한 스케일과 OST. '역시 믿고 보는 디즈니' 라는 말이 절로 나온다. 그렇게 부모와 어른이들의 통장은 또 한번 굿즈로 탈탈탈...", '역시 겨울왕국..기대한만큼 만족스러웠음ㅜㅜ엘사 미모에 치이고 OST에 한번 더 치이고..한번 더 볼 생각임!!', '스토리는 나쁘지 않았는데 소재가 어둡다보니, 겨울왕국1같은 밝고 신나는 ost가 적은듯... 그리고 ost가 귀에 남을만한게 없다는 아쉬움', '엘사가 성장한 모습으로 행복한 길을선택한것 같아 너무 감동이었음ㅠㅠ진짜 너무 재밌다', '크리스토프의 뮤직비디오 인상깊었어요', '올라프는 흡사 광해의 이병헌급 연기자.', '요정이었구나 어쩐지 너무 예뻤어', '거북이는 엉덩이로 숨을 쉴 수 있다.', "아토할란의 4원소 결정=엘사가 중심 밟으면서 눈결정 모양이됨=자세히보면 다섯번째 정령형상=다섯번째 정령이 엘사를 부르는 소리'워어어~'=어린엘사엄마가 어린엘사아빠 구하려고 정령을 부르는 소리=쇼유어셀프...", "보고 나오는데 나뭇잎이 날리길래 '..게일..?'", '이번건 진짜 양상미가 미쳣음', '1편도 엄청 봤는데 , 2편은 더 많이 볼것 같아요 ㅜ 저만 울었나요? ^^;; 음악도 좋고 영상미는 말할것도 없고 전 너무 감동적으로 보았어요', '와... 감상포인트는 영화 자체가 바로 감상포인트 라고 생각합니다 노래도 겨울왕국2에선 더 섬세한 부분까지 다룬 것 같아 몰입도 최강이었습니다! 1번째로 영화를 본 보람이 있네요!!!', '니들 영화보고 평점 남기니?', ... ... ...
- 크롤링한 데이터 파일로 저장 하기
review_list = [] for page in range(1,11): url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={page}' html = urlopen(url) soup = BeautifulSoup(html,'html.parser') for i in range(10): review = soup.find('span',{'id':f'_filtered_ment_{i}'}) review = review.get_text().strip() review_list.append(review) # with open을 활용하여 따로 file을 열고 닫기 하지 않아도 된다. # 'w'는 file write 기능 # encoding='utf-8' => utf-8형식으로 저장 with open('./naver_movie.txt','w',encoding='utf-8') as f: for single_review in review_list: f.write(single_review+'\n') del review_list # 메모리 절약을 위한 리스트 삭제

- request라이브러리와 urllib.request 차이는?
1.urllib.request의 경우에는 내가 크롤링한 기록이 남게 된다.
2.request를 사용하면 header값을 임의로 수정할 수 있어서, 비교적 자유롭게 크롤링 가능
3.가능하면 request를 쓰는 것을 권장
import requests review_list = [] for page in range(1,11): url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={page}' html = requests.get(url) soup = BeautifulSoup(html.content,'html.parser') for i in range(10): review = soup.find('span',{'id':f'_filtered_ment_{i}'}) review = review.get_text().strip() review_list.append(review) with open('./naver_movie_request.txt','w',encoding='utf-8') as f: for single_review in review_list: f.write(single_review+'\n')
- 2000명에 대한 댓글 가져오기
import requests review_list = [] for page in range(1,2001): url = f'https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=136873&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={page}' html = requests.get(url) soup = BeautifulSoup(html.content,'html.parser') for i in range(10): review = soup.find('span',{'id':f'_filtered_ment_{i}'}) review = review.get_text().strip() review_list.append(review) with open('./naver_movie_request_2000.txt','w',encoding='utf-8') as f: for single_review in review_list: f.write(single_review+'\n')
- 영화 제목을 통한 영화 코드 검색 (네이버 무료 api 활용) -> 오픈 API이용 신청
#네이버 검색 Open API 사용 요청시 얻게되는 정보를 입력 client_id = "<네이버 client id>" client_secret = "<네이버 secret>" def cleanhtml(raw_html): cleanr = re.compile('<.*?>') cleantext = re.sub(cleanr, '', raw_html) return cleantext def search_title(title): url = 'https://openapi.naver.com/v1/search/movie.json?display=100&query=' + quote(title) request = urllib.request.Request(url) request.add_header("X-Naver-Client-Id",client_id) request.add_header("X-Naver-Client-Secret",client_secret) response = urllib.request.urlopen(request) rescode = response.getcode() if(rescode==200): response_body = response.read() d = json.loads(response_body.decode('utf-8')) if (len(d['items']) > 0): return d['items'] else: return None else: print("Error Code:" + rescode)

데이터 분석 유튜버 "거친코딩"입니다.