강의소개
2강에서는 추출기반으로 기계독해를 푸는 방법에 대해 알아보겠습니다. 추출기반으로 기계독해 문제에 접근한다는 것의 의미를 이해하고, 실제 추출기반 기계독해를 어떻게 풀 수 있을지에 대해 배워볼 예정입니다. 학습 전 준비해야할 단계와 모델 학습 단계, 그리고 추출기반으로 얻어낸 답을 원하는 텍스트의 형태로 변형하는 방법에 대해 이번 강의에서 자세히 알아보겠습니다.
Further Reading
- SQuAD 데이터셋 둘러보기
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- Huggingface datasets
Extraction-based MRC
Extraction-based MRC의 정의(자세한 내용은 1강 참고)
- 질문(query or question)의 답변(answer)이 항상 주어지는 지문(context) 내에 span으로 존재
- e.g.) SQuAD, KorQuAD, NewsQA, Natural Qeustions
- Huggingface datasets을 호출하여 사용하면 매우 편리함
Extraction-based MRC 평가 방법
Extraction-based MRC Overview(자세한 내용은 1강 참고)
- Exact Match : 정답이 완전히 똑같은 경우 1점, 조금이라도 다르면 0점 부여
- F1 Score : 예측값과 정답의 overlap을 비율로 계산하여 0~1점 사이의 부분점수를 부여
- ground truth는 하나 이상일 수 있으며, 이 경우 가장 높은 score를 출력
- 학습 방법은 다음과 같음
- input : [CLS] + question_seq_tokens + [SEP] + contxt_seq_tokens + [seq]
- 이후 각 토큰을 embedding table을 통해 embedding vector로 변환
- output은 정답에 해당하는 위치 span의 시작과 끝 position을 출력
- 이후 변환하여 결과를 반환
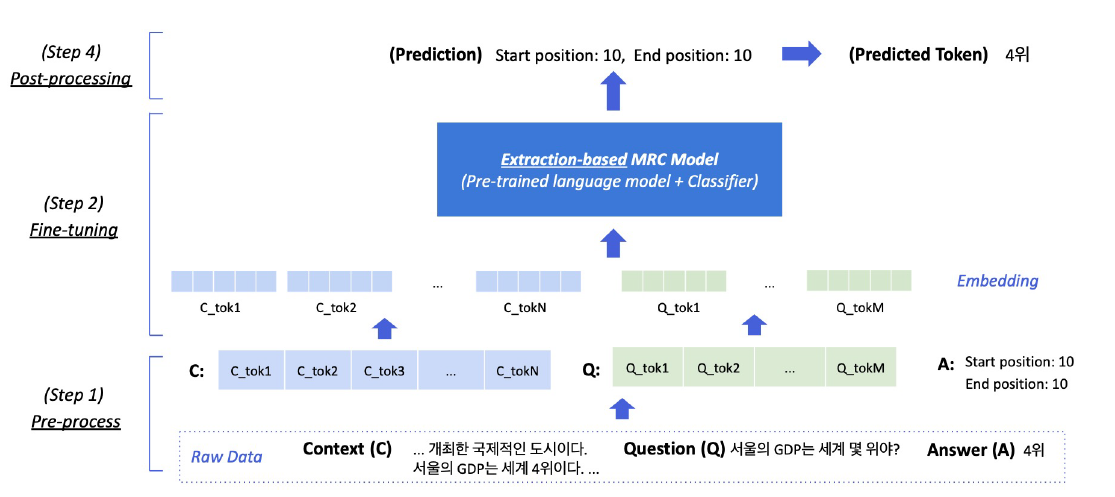
Pre-processing
- Tokenization, 최근엔 OOV 문제를 해결해주고 정보학적으로 이점을 가진 BPE를 주로 사용함
- [CLS] + question_seq_tokens + [SEP] + contxt_seq_tokens + [seq], 필요할 경우 [PAD]도 추가, 이 형태로 하여 질문과 지문을 분리
- attention mask를 사용하여, attention에 사용할 token은 1로, 제외할 토큰(pad, masking 등)은 0으로 지정
- Token Type IDs, 입력이 2개 이상의 squence이므로 각각에 ID를 부여하여 모델이 구분해서 해석하도록 유도
- 질문에 해당하면 0, 지문에 해당하면 1, 지문 이후 pad에 대해선 0을 부여
- 모델의 출력은 정답에 해당하는 subword token의 시작과 끝 위치인데, 이 경우 초기에 주어진 string 형태에서의 위치와는 다르므로 이 것을 matching해줘야 함
Fine-tuning
- 아래와 같이, pre-processing에서 정의한 입력을 형태를 넣어주면 출력이 나오는데, 여기서 출력을 softmax 후 NLL loss로 학습
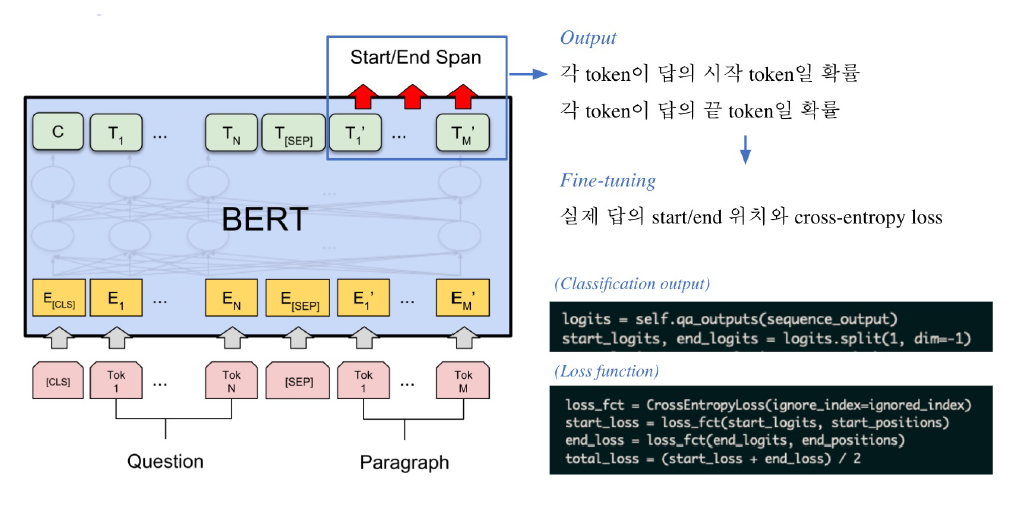
Post-processing
- 크게 두 가지로 나눔
- 1) 불가능한 답 제거하기
- End position이 start position보다 앞에 있는 경우
- 예측한 위치가 context를 벗어나는 경우(question 위치에 답이 나온 경우)
- 미리 설정한 max_answer_length보다 길이가 더 긴 경우
- 2) 최적의 답안 찾기
- Start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾음
- 여기서, start/end 각각 n개이므로 n^2개의 조합이 생성됨
- 불가능한 start/end 조합 제거
- 가능한 조합들을 socre의 합이 큰 순서대로 정렬
- Score가 가장 큰 조합을 최종 예측으로 선정
- Top-k가 필요한 경우 차례대로 출력
- 1) 불가능한 답 제거하기
실습코드를 보다가 RE Task와 달리, trainer에 train & eval dataset 뿐만 아니라 post-processing function을 지정해줘야 하는 차이가 있다는 것을 알았다.
그리고 추가로,training_args.fp16 옵션을 사용하면 학습 속도를 개선할 수 있는 부분도 알았으니 이번 대회에서 잘 활용해보자.

DL, NLP Engineer to be....