강의소개
3강에서는 생성기반 기계독해에 대해 배워보겠습니다. 생성기반으로 기계독해를 푼다는 것의 의미를 이해하고, 어떻게 생성기반 기계독해를 풀 수 있을지 알아보겠습니다. 2강에서와 마찬가지로 모델 학습에 필요한 전처리 단계, 생성기반 모델 학습 단계, 그리고 최종적으로 답을 얻어내는 세 단계로 나눠 생성기반 기계독해를 푸는 방법에 대해 배워볼 예정입니다.
Further Reading
- Introducing BART
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (T5)
Generation-based MRC
Generation-based MRC 문제 정의
- MRC 문제를 푸는 방법
- 1) Extraction-based MRC(2강 내용)
- 지문(context) 내 답의 위치를 예측 : 분류 문제(classification)
- 2) Generation-based MRC(이번 강의 내용)
- 주어진 지문과 질의(question)를 보고, 답변을 생성 : 생성 문제(Generation)
- 모든 extraction-based MRC도 generation-based MRC 문제로 변형이 가능함, 단 반대는 성립하기 힘듦(정답이 문장 내에 없는 경우가 있기 때문)
- 1) Extraction-based MRC(2강 내용)
Generation-based MRC 평가 방법
- 동일한 extractive answer datasets => Extraction-based MRC와 동일한 평가 방법을 적용 : EM, F1
- 단, 조금 더 생성문제와 비슷하게 접근하고자 하면, RUDGE나 BLEU를 사용
Generation-based MRC Oveview
- input은 동일하지만 extraction-based MRC와 동일하게 진행
- 반면, extraction-based MRC에서는 output에 해당하는 encoder embedding을 score로 바꿔서 start와 end를 예측했다면
- generation-based MRC에선 Model에서 정답까지 생성해서 출력을 해줌
- 따라서, 일종의 seq2seq Model로 볼 수 있음. 그렇기에 decoder가 없는 BERT는 사용이 불가함(RoBERTa, Albert도 사용이 불가하겠네요..)
Generation-based vs Extraction-based
- MRC 모델 구조
- Seq2Seq PLM 구조(generation) vs PLM + Classifier 구조(extraction)
- Loss 계산을 위한 답 형태 / Prediction 형태
- Free-form text 형태(generation) vs 지문 내 답 위치(Extraction)
- Extraction-based MRC : F1 계산을 위해 text로의 별도 변환 과정이 필요
- generation : text를 decoding할 때 teacher-forcing과 같은 방식으로 학습을 진행!!
- Free-form text 형태(generation) vs 지문 내 답 위치(Extraction)
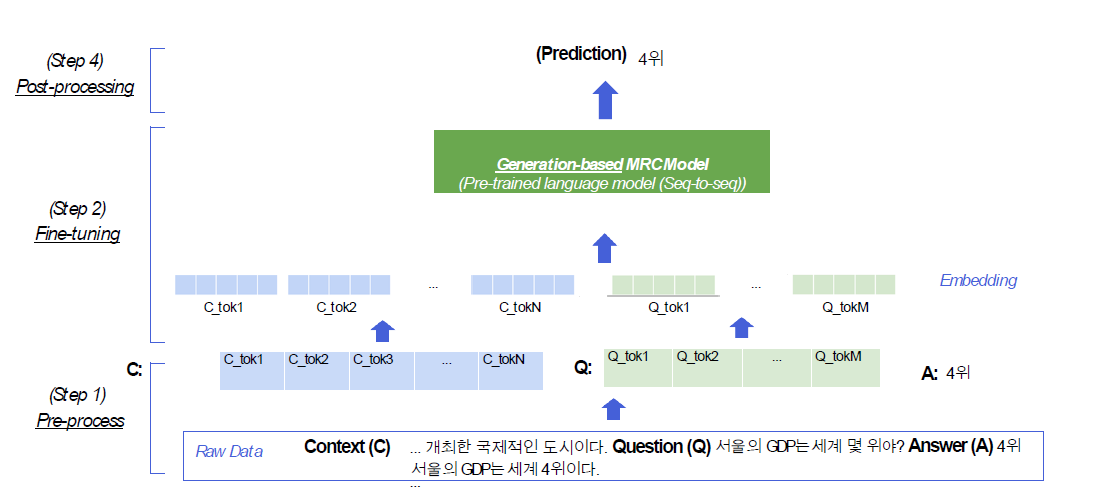
Pre-processing
- extraction-based보다 심플함 => 정답의 위치는 제외하고 정답만 넘겨주면 됨
- wordpiece tokenizer를 사용하여 tokenizing
- input 형태가 다름
- Extraction-based : [CLS] + question_tokens + [SEP] + context_tokens + [SEP]
- Generation-based : [SoS] + 'question:' + question_tokens + 'context:' + context_text + [EoS]
- 단 이 부분은 모델별로 상이하며, Extraction-based와 같이 input을 넣기도 함
- 즉, 모델별로 input 형태를 보고 사용하도록 하자
- input : additional information
- Attention mask 포함
- Token type ids 미포함
- bert와 달리 bart는 입력 시퀀스에 대한 구분이 없어서 token_type_ids가 불필요
- 따라서 Extraction-based MRC와 달리 input_type_ids가 들어가지 않음
- 초창기에는 직접적으로 구분을 해줬지만, 이후에는 불필요하다고 판단하였으며, [SEP]를 통해 어느 정도 seq를 구분할 수 있기에 제외된 모델들이 있음
- output - 정답 출력
- 출력이 정답 시퀀스에 대한 span 범위가 아니라 text이기에 training은 조금 어렵지만 formulation은 상당히 심플해짐
Model
- BERT와 상당히 다른 architecture
- BERT : encoder만 존재하여, 각 단어의 embedding vector가 Encoder를 통과되고 나온 결과를 가지고 answer의 시작과 끝을 출력
- BART : encoder-decoder 구조로, 텍스트를 내보내고, 학습은 BERT와 같이 masking도 하지만 정답을 생성하는 방식!!
- GPT(LM) : 다음 단어를 맞추는 방식으로 학습 진행
- 이런 방식을 일반적으로 noise를 injection하고 원래 sequence를 복원하는 방식으로 학습하기에 de-noising auto-encoder라고도 함.
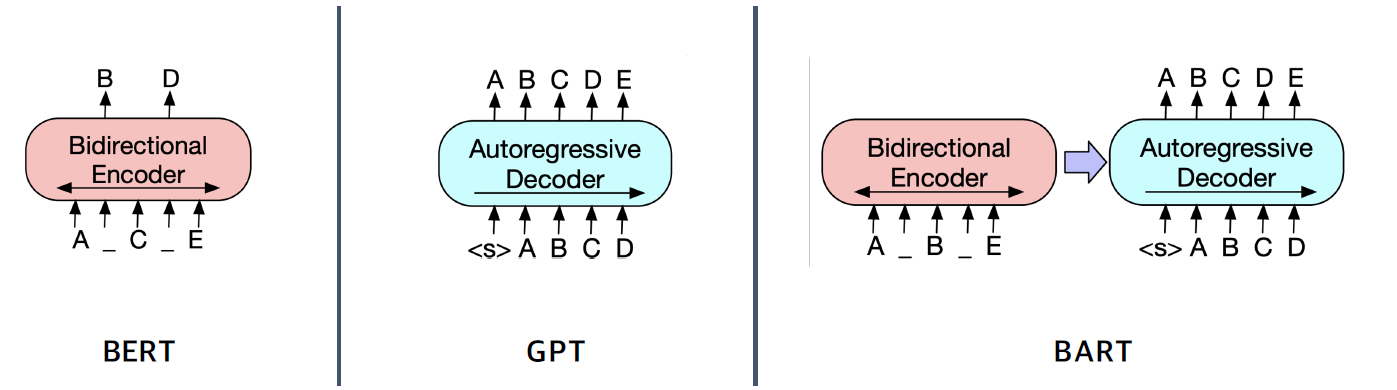
- BART의 Encoder와 Decoder
- Encoder : BERT처럼 bi-directional
- Decoder : GPT처럼 uni-directional(autogressive)
- Pre-training BART
- 텍스트에 노이즈를 주고 원래 텍스트를 복원하는 문제를 푸는 방식으로 pretraining을 하므로 생성쪽으로 용이하게 학습!!
Post-processing
- decoding 방식으로 text르 생성하기에 이전에 step의 출력을 다음 step에 input으로 사용
- decoding의 시작은 token이 들어가고, decoding 방법론은 여러가지가 있음
- searching
- greedy Search : likehood가 가장 높은 단어를 예측
- 효율적이고 빠르지만, 개별 step에 대한 확률만 보기에, 각 step에서는 확률이 높더라도 전체적으로 봤을 때 낮을 수가 있음
- Exhaustive Search : 모든 가능성을 확인, 이 경우 timestep이 진행될 때 경우의 수가 exponential하게 증가하므로 불가
- Beam Search : 각 timestep에 가장 점수가 높은 k개만 유지하는 방식으로 진행
- greedy Search : likehood가 가장 높은 단어를 예측
실습

DL, NLP Engineer to be....