강의소개
앞선 4강에서는 sparse embedding 기반 문서 검색에 대해 배워보았습니다. 이번 5강에서는 앞서 배운 sparse embedding이 가지는 한계점들에 대해 알아보고, 이를 해결할 수 있는 dense embedding에 대해 배워보겠습니다. Dense embedding의 개념을 알아보고, 어떻게 dense embedding을 학습하고 문서 검색을 수행할 수 있을지에 대해 실습과 함께 자세히 알아보겠습니다.
Further Reading
Introduction to Dense Embedding
- Sparse Embedding 단점을 극복한 Dense Embedding에 대해서 알아보자
Passage Embedding
- 구절(Passage)을 벡터로 변환하는 것
Sparse Embedding
- TF-IDF 벡터는 BoW 방법론을 사용하기에 Sparse함
Limitations of Sparse Embedding
- 차원의 수가 매우 큼 => compressed format으로 극복 가능
- 유사성을 고려 못함 : 유사하지만 다른 형태의 단어는 vector space에서 다른 단어로 인식(가장 큰 단점!!)
Dense Embedding이란?
- Complementary to sparse representations by design
- 더 작은 차원의 고밀도 벡터(length : 보통 50~1000 사이)
- 각 차원이 특정 term에 대응되지 않음
- 대부분의 요소가 non-zero값(not sparse)
Retrieval: Sparse vs Dense
- Sparse의 경우
- 단어 존재 유무 등 retrieval 할 땐 유용하지만 의미를 해석하는데 제한적, 또한 차원이 매우 큼
- 중요한 term들이 정확히 일치하는 경우 성능이 뛰어남!!
- 임베딩이 구축되고 나서는 추가적인 학습이 불가
- Dense의 경우
- 단어의 유사성 혹은 맥락 해석이 가능하고, 차원이 상대적으로 작아서 다양한 방법론 적용 가능
- 학습을 통해 임베딩을 만들며 추가적으로 학습 가능
- 일반적으론 Sparse Embedding + Dense Embedding, 혹은 Dense Embedding 만으로 Retrieval을 구축하는 것을 권장
- PLM 등장 이후, Dense Embedding이 활발히 이용
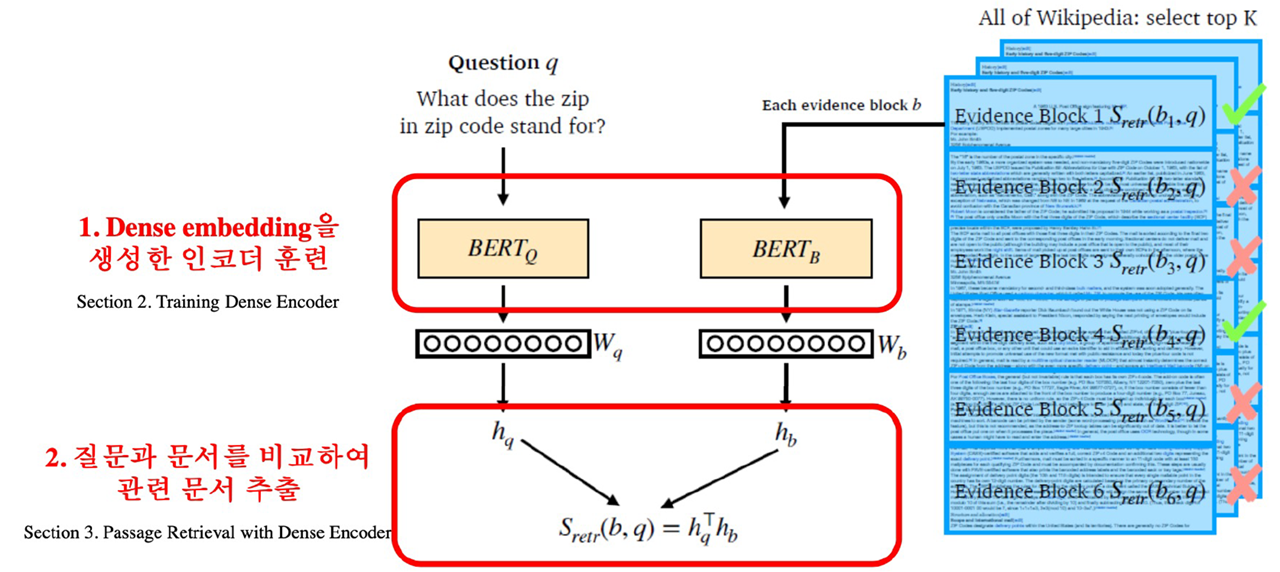
Overview of Passage Retrieval with Dense Embedding
- 일반적으로 Question을 위한 Encoder(1)와 Passage을 위한 Encoder(2)가 따로 존재(하나의 모델로 사용하는 경우도 있음, design choice)
- Encoder(1)에서는 질문이 들어오고, 출력으로는 cls token에 해당하는 가 최종 output으로 반환됨
- Encoder(2)도 동일한 과정을 통해 가 출력되는데, 만약 모든 Passage에 대해서 구할 경우 Passage를 하나씩 확인 후 Top k개만 선택하여 MRC 모델에 적용
- 두 output의 유사도는 기본적으로 dot-product를 사용해볼 수 있음
Training Dense Encoder
What can be Dense Encoder?
- BERT와 같이 PLM이 자주 사용되며, 그 외에 다양한 neural network 구조도 가능
- BERT를 Dense encoder로 사용할 경우 : [CLS] token의 output으로 Passage를 Embedding
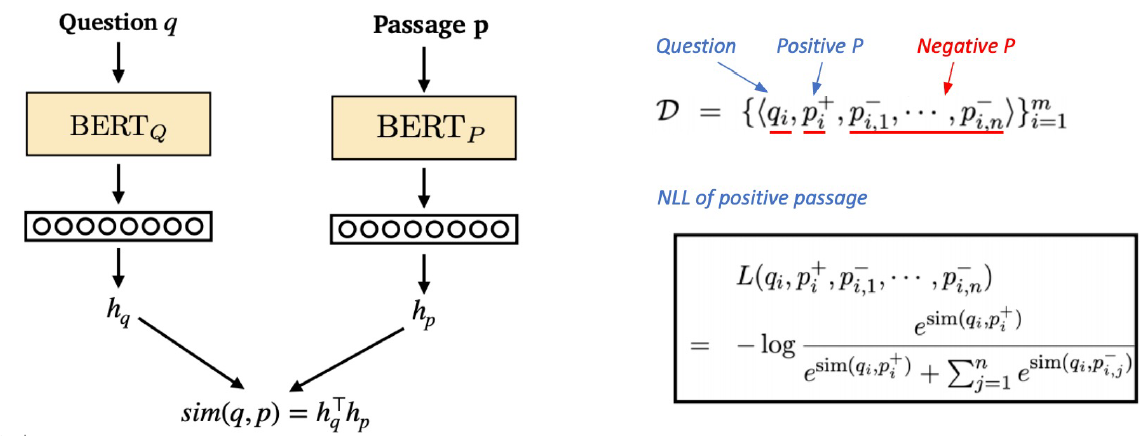
Dense Encoder의 학습 목표와 학습 데이터
- 학습 목표 : 연관된 question과 passage dense embedding 간 거리를 좁히는 것(또는 inner product를 높이는 것)
- Challenge : 연관된 question과 passage를 어떻게 찾을 것인지
=> 기존 MRC 데이터셋을 활용
Negative Sampling
- 연관된 question과 passage 간의 Dense embedding 거리를 좁히는 것 : positve
- 연관된 question과 passage 간의 Dense embedding 거리를 멀어지게 하는 것 : Negative
- 관련이 없는 passage 샘플링 : 랜덤 샘플링 // 관련이 있는 passage : 해당 question의 passage를 사용
- 관련이 있는 passage는 거리를 좁히고, 관련이 없는 passage는 거리를 늘리는 방식으로 학습이 진행
Choosing negative examples
1. Corpus 내에서 랜덤하게 추출
2. 좀 더 헷갈리는 negative 샘플 추출(ex. 높은 TF-IDF 스코어를 가지지만 담을 포함하지 않은 샘플 등)
Object function
- Positive passage에 대한 negative log likehood(NLL) loss 사용
- 즉 query와 passage 사이에서 구한 유사도를 softmax 후 NLL에 적용하여 학습!!
Passage Retrieval with Dense Encoder
- From dense encoding to retrieval
- inference : Passage와 query를 각각 embedding 후, query와 유사도가 높은 순서대로 passage 순위를 매김
- From retrieval to ODQA
- Pretriever를 통해 찾아낸 Passage를 활용하여 MRC 모델로 답을 찾음
How to make better dense encoding
- 학습 방법 개선(e.g. DPR)
- 인코더 모델 개선(BERT보다 크고 정확한 PLM)
- 데이터 개선(더 많은 데이터, 전처리 등)
실습코드
batch 기준으로 Dense Encoder를 이용한 Passage Retrieval에 대해서 직접 코드로 다뤄봤다. 다만 제공해주신 ipynb가 colab 기준으로 작성했다고 하셨지만, colab pro+ 기준이었던 거 같다...(난 일반인데 ㅠㅠ)
대회 기준으로 볼 때, query와 passage가 pair로 주어지므로 어쩌면 retrieval이 필요로 할까라는 생각도 해본다. 하지만 앞으로 ODQA 같은 task를 다뤄보고자 하는데 이 때 retrieval에 대한 개념은 반드시 필요할 것으로 보인다.
그러니깐 꼼수 부리지말고 그냥 열심히 더 공부해보겠다.. 복습도 하고, 복복습도 하고 계속 하겠다..

DL, NLP Engineer to be....