강의소개
앞선 4, 5강에서 sparse / dense embedding을 활용해 문서 검색을 하는 방법에 대해 실습해보았습니다. 실습에서는 수만개 단위의 데이터였지만, 실제 문서 검색이 이루어지길 원하는 실제 상황에서는 그 문서의 수가 기하급수적으로 늘어나게 됩니다. 위키피디아 문서에서 검색하는 상황을 가정하더라도 5백만개 이상의 문서에서 검색을 수행해야 하고, 실제로는 수천만 ~ 억개의 문서가 존재할 수 있습니다. 이런 상황에서는 앞선 강의에서 배운 모든 문서들에 대해 검색을 수행하는 방법이 굉장히 오랜 시간과 많은 자원을 요구하게 됩니다.
이번 6강에서는 이렇게 scale이 커진 상황에서 어떻게 효율적으로 검색을 수행할 수 있을지에 대해 배워볼 예정입니다. 먼저 similarity search의 개념에 대해 간략하게 복습해본 후, 보다 효율적인 approximate search가 무엇인지 알아보겠습니다. 그리고 approximate search를 편리하게 사용할 수 있도록 도와주는 FAISS를 활용하는 방법에 대해 알아보고 실습해보겠습니다.
Further Reading
Passage Retrieval and Similarity Search
- similarity search 기본 개념 복습
복습: Retrieval with dense embedding
- question encoder - question의 representation vector 생성
- passage encoder - 각 passage에 대한 representation vector 생성
- 이후 question과 passage의 representation vector의 similiarity를 계산하여 score가 높은 top k개의 passage 선택
문제는, passage 개수가 많아질수록 연산량이 증가하게 된다. 따라서 어떻게하면 real time으로 원하는 passage를 찾을 수 있을까?**
MIPS(Maximum Inner Product Search)
- 주어진 질문(query) 벡터 q에 대해 Passage 벡터 v들 중 가장 질문과 관련된 벡터를 찾아야 함
- 여기서 관련성은 내적(inner Product)이 가장 큰 것
- 4,5강에서 사용한 방법 : brute-force(exhautive) search
- 저장해둔 모든 Sparse/Dense 임베딩에 대해 일일이 내적값을 계산하여 가장 큰 값의 passage 출력
- Passage가 많아질수록 비효율적
MIPS & Challenges
- 실제로 검색해야 할 데이터는 방대함
- 5백만 개(위키피디아)
- 수식억, 조 단위까지 커질 수 있음
- 따라서 모든 문서 임베딩을 일일이 비교 불가
Tradeoffs of similarity search
- 1) Search Speed(ms per vector)
- query마다 유사한 벡터를 K개 찾는데 얼마나 오래 걸릴지
- 가지고 있는 벡터량이 클수록 오래 걸림
- Pruning을 고려
- query마다 유사한 벡터를 K개 찾는데 얼마나 오래 걸릴지
- 2) Memory(RAM) Usage, bytes per vector
- 벡터를 사용할 때, 어디에서 가져올 수 있을지
- RAM에 모두 올려둘 수 있으면 빠르지만, 많은 RAM용량을 요구함
- 디스크에서 계속 불러와야한다면 속도가 느려짐
- Compression 방법론 고려
- 벡터를 사용할 때, 어디에서 가져올 수 있을지
- 3) Accuracy( % of actual nearest neighbors found at rank 1)
- brute-force 검색 결과와 얼마나 비슷한지
- 속도를 증가시키려면 정확도를 희생해야 하는 경우가 많음
- Exhaustive search 방법론 고려(검색 효율을 향상시켜야 함)
- brute-force 검색 결과와 얼마나 비슷한지
Approximating Similarity Search
- 검색 방법론 approximation 및 속도 개선 및 문서 탐색방법 학습
Compression - Scalar Quantization(SQ)
- compression: vector를 압축하여, 하나의 vector가 적은 용량을 차지 => 압축량 증가 시 메모리 감소 및 정보 손실 증가
- e.g.) 4-byte floating point를 1 byte unsigned interger로 압축
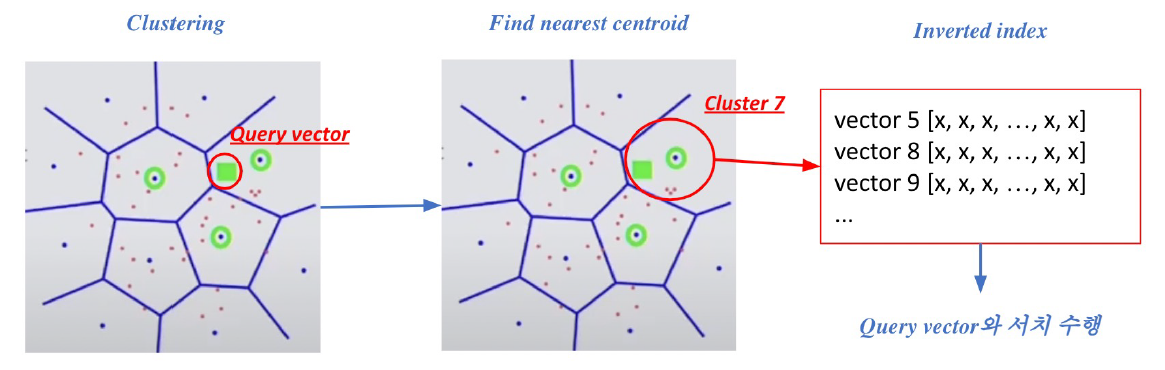
Pruning - Inverted File(IVF)
- Pruning: search space를 줄여 search 속도 개선(dataset의 subset만 방문)
- clustering + inverted file을 활용한 search
- clustering : 전체 vector space를 k개의 cluster로 나눔
- e.g.) k-means clustering
- inverted file(IVF) : vector의 index = inverted list structure
- '각 cluster의 centroid id'와 '해당 cluster의 vector들'이 연결되어있는 형태
- clustering : 전체 vector space를 k개의 cluster로 나눔
- clustering + inverted file을 활용한 search
Introduction to FAISS
- FAISS 라이브러리를 활용한 scail up 학습
What is FAISS
- facebook에서 만든, fast approximation을 위한 open-source library
- large scale의 passage를 다루는데 매우 효율적임
- backone은 C++이지만, wrapping은 python으로 되어 있기에 쉽게 사용 활용 가능
- faiss encoding보단 indexing에 도움을 주는 라이브러리
Passage Retrieval with FAISS
- 1) Train index and map vectors
- FAISS를 사용하기 위해선 cluster를 확보해야 함
- 이 때 각 passage의 encoding vector값이 랜덤하게 지정하면 비효율적으로 clustering을 하므로 학습 데이터가 필요
- 그리고 SQ(float32->int)를 해야 하는데, Quantization 시 float의 max, mean값이 몇이며, 이걸 얼마로 scaling할 지를 파악할 필요가 있음
- 즉, train 후 add를 통해 mapping을 위한 준비를 완료함
- 2) search based on FAISS index
- nprobe를 정하고, 가장 가까운 nprobe만큼의 cluster를 방문하여 search
- top-k개를 search result로 출력
Scaling up with FAISS
- 실습
FAISS Basics
# brute-force로 모든 벡터와 쿼리를 비교하는 가장 단순한 인덱스 만들기
#pruning과 SQ을 활용하지 않기에 학습이 불필요함
# 준비
d = 64 # 벡터의 차원
nb = 100000 # DB 크기
nq = 10000 # 쿼리 개수
xb = np.random.random((nb, d)).astype('float32') #DB 예시
xq = np.random.random((nq, d)).astype('float32') #쿼리 예시
# 인덱스 만들기
index = faiss.IndexFlatL2(d) # 인덱스 빌드하기, dimension 정의
index.add(xb) # 인덱스에 벡터 추가하기
# 검색하기
k = 4 # top-k : 4개
D, I = index.search(xq, k) # 검색하기
# D : 쿼리와의 거리
# I : 검색된 passage 벡터의 인덱스IVF with FAISS
# IVF 인덱스 만들기
# 클러스터링을 통해서 가까운 클러스너 내 벡터들만 비교
# 빠른 검색 가능
# 클러스터 내에서는 여전히 전체 벡터와 거리 비교(flat)
# IVF 인덱스
nlist = 100 # 클러스터 개수
quantizer = faiss.IndexFlatL2(d) # 클러스터에서 거리를 재는 방법을 지정(여기선 L2)
index = faiss.IndexIVFFlat(quantizer, d, nlist) # Inverted FIle 만들기
# quantizer를 이용하여 n개의 클러스터를 만들기 위한 사전 준비 작업
index.train(xb) # 클러스터 학습하기
#xb가 매우 큰 경우 일부만 샘플링하여 train 시킴
#단, add 시에는 모든 xb 사용
index.add(xb) # 클러스터에 벡터 추가하기
D,I = index.search(xq, k) # 검색하기
# 검색하기
k = 4 # top-k : 4개
D, I = index.search(xq, k) # 검색하기IVF-PQ with FAISS
# 벡터 압축 기법(PQ) 활용하기
# SQ보다 더 압축이 많이 되지만, 일단은 SQ를 해보고 필요할 경우 PQ를 이용해보아요..
# 전체 벡터를 저장하지 않고 압축된 벡터만을 저장
# 메모리 사용량을 줄일 수 있음
# IVF-PQ 인덱스
nlist = 100 # 클러스터 개수
m = 8 # subquantizer 개수
quantizer = faiss.IndexFlatL2(d) # 클러스터에서 거리를 재는 방법을 지정(여기선 L2)
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) # 각각의 sub-vector가 8bits로 인코딩 됨
# quantizer를 이용하여 n개의 클러스터를 만들기 위한 사전 준비 작업
index.train(xb)
index.add(xb)
D,I = index.search(xq, k) # 검색하기
# 검색하기
k = 4 # top-k : 4개
D, I = index.search(xq, k) # 검색하기Using GPU with FAISS
# GPU의 빠른 연산속도를 활용할 수 있음
# gpu에 모든 vector를 올리는 것이기에, exhaustive search 등 거리 계산을 위해 행렬곱 등에서 유리
# 다만, GPU 메모리 제한이나 메모리 random access 시간이 느린 것이 단점
# 또한 gpu를 사용하므로써 라이브러리를 제한적으로 사용해야 함
# IndexFlatL2만 사용 가능하며, 다른 search 알고리즘을 사용하기 어려움
# 단일 GPU 인덱스
res = faiss.StandardGpuResources() # 단일 GPU 사용하기
index_flat = faiss.IndexFlatL2(d)
#gpu 인덱스로 옮기기
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, index_flat)
gpu_index_flat.add(xb)
D,I = index.search(xq, k) # 검색하기Using Multiple GPUs with FAISS
# 여러 GPU를 활용하여 연산 속도를 한층 더 높일 수 있음
# 대부분의 경우 Multi GPUs까지는 불필요하므로 일단 싱글 GPU 방법부터 적용
cpu_index = faiss.IndexFlatL2(d)
#gpu 인덱스로 옮기기
gpu_index_flat = faiss.index_cpu_to_all_gpus(cpu_index)
gpu_index_flat.add(xb)
D,I = index.search(xq, k) # 검색하기
DL, NLP Engineer to be....