[BoostCamp AI Tech / Day 8, DL basic] Modern CNN(1x1 convolution의 중요성)
[boostcampAI U stage] week2
해당 강의에서 언급하는 Modern Convolutional Neural Networks는 2018년도 기준으로 설명하는 것이므로 이점을 유의하기 바란다.
ILSVRC 대회에서 나왔던 network에 대해 다뤄볼 건데, AlexNet부터 시작하여 해마다 우승했던 Network 위주로 정리할 예정이다. 각 network 볼 때 중점적으로 볼 부분은 각 network의 parameter 개수와 network depth이며, depth가 깊어질수록 성능이 개선되는 점이다.
ILSVRC
- ImageNet Large-Scale Visual Recognition Challenge
- classification, detection, localication, segmentation
- 1000 different categories
- over 1 milion images
- training set : 456,567+a images
- error ratedms, image classification을 학습한 사람의 경우 about 5.1% 정도인데 2010년도에 28.2%부터 2015년 3.5%로 줄어들었으며, 2015년도부터 사람보다 error가 줄어들었다.
AlexNet(2012년 ILSVRC 우승)
- ILSVRC 대회에서 처음으로 DL을 통해 우승하여 CNN이 대두시작된 시점
- 5-convolution layers + 3-dense layers
- 특징으로는 Network가 2개
- 당시 GPU 성능이 부족하여 이를 최대한 활용하기 위해, network를 구분하여 2장의 GPU에 따로 training
- input에 11 x 11의 filter을 사용하는데 좋은 선택은 아니다.
- VGG에서 설명

AlexNet Key ideas
- ReLU activation
- Preserves properties of linear models
- Easy to optimize with gradient descent
- Good generalization
- Overcome the banising gradient problem
- GPU imlementation(2 GPUs)
- Local response normalization, Overlapping Pooling
- Data augmentation
- Dropout
VGGNet(2014년 ILSVRC 준우승)
- increasing depth with 3x3 convolution filters(with stride 1)
- 이 당시 1x1 conv는 파라미터 개수를 줄이고자 한 부분이 아니기에 크게 중요하진 않음
- Dropout(p=0.5)
- VGG16, VGG19(layer 개수에 따라 VGGXX)
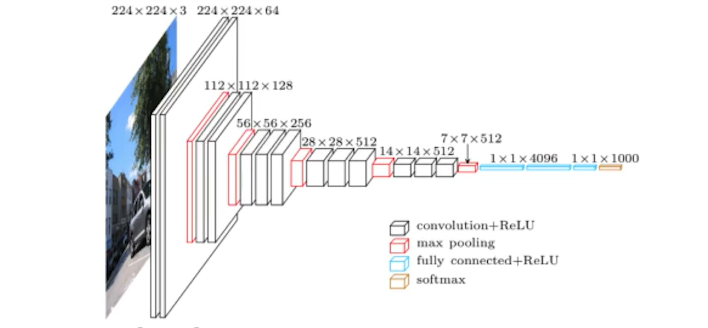
왜 3x3 convolution을 했을까?
결론적으론 큰 special dimension의 filter 하나를 사용한 경우에 비해 작은 special dimension filter를 여러개 사용하는 것이 parameter 개수가 줄어든다.
convolution feature map의 한 값을 얻기 위해 convolution filter가 찍었을 때 고려되는 input의 speical dimension을 receptive field라고 한다.
input이 7x7이고, 5x5 convolution과 2-layer로 된 3x3 convolution이 있다고 생각해보자. 이때 feature map의 한 개의 값을 얻기 위해선 5x5 conv에선 receptive field가 5x5이며, parameter 개수도 5x5로 25개이며 output은 3x3 feature map이다. 반면, 2-layer conv에선 3x3 kernel이 2개 사용됐으므로 parameter의 개수는 총 3x3x2로 18개이며, 7x7이 3x3 kernel을 통과하여 5x5, 다시 3x3을 통과하여 3x3이 됐으며, 결과적으로 3x3 feature map이 나오기 위한 receptive field는 전자와 같은 5x5같다.
따라서 동일한 receptive field지만 kernel filter의 special dimension이 작을수록 parameter 개수가 감소한다
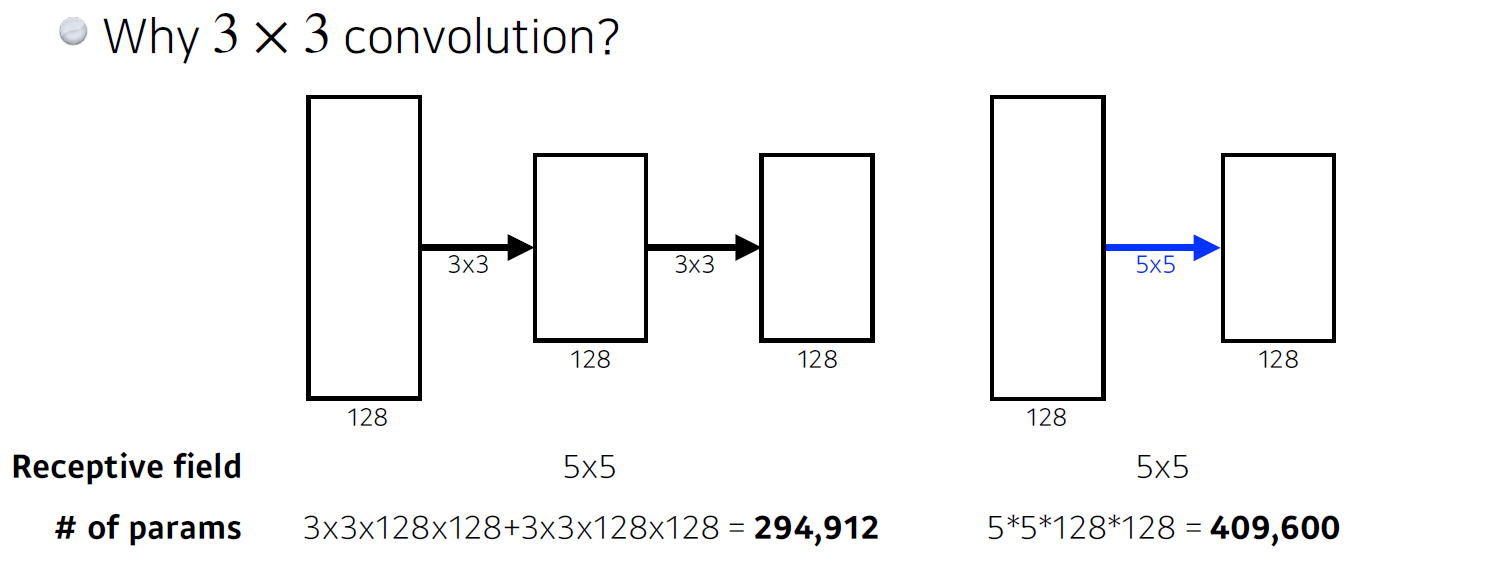
GoogLeNet(2014년 ILSVRC 우승)
- 22-layers
- network in network(NiN) with inception blocks
- Inception blocks(with BottleNeck architecture(1x1 convoltuion filter))

Inception Block
- Benefits of the inception block
- Reduce the number of parameter
- How
- 1x1 convolution can be seen as channel-wise dimension reduction
inception 블럭은 다음과 같이 여러 개의 filter size를 적용한 것이다. 이를 동일한 level의 layer에 적용하면 여러 개의 receptive Field를 얻는 동시에 네크워크가 깊어짐으로서 생기는 문제점을 보완할 수 있다.(각각 filter -> pooling)
그러나 한 가지 문제는, pooling은 width와 height를 가 변화하고 depth는 변화하지 않으며, 각 출력을 합치면 depth가 매우 두꺼워진다.
따라서 이 문제를 해결한 방법으로는 bottleck architecture(1x1 convolution)을 추가하여 depth를 줄였다.
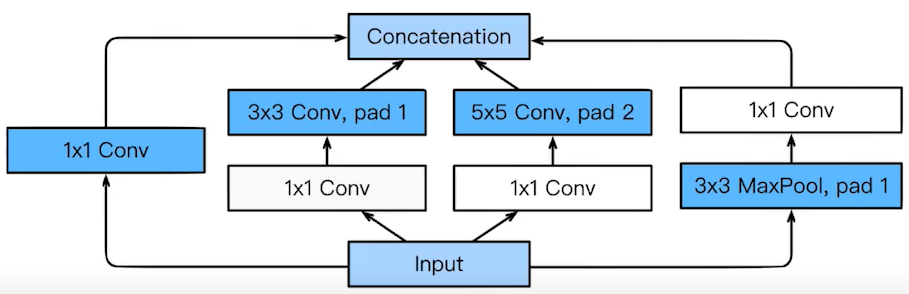
bottleck architecture(1x1 convolution)
convolution filter을 통해 동일한 depth를 가진 feature map이 출력되도록 하는데, 그 과정에서 1x1 convolution filter를 사용하면 channel 방향으로 정보 압축을 통해 depth를 줄이게 되면, 같은 input으로 구한 feature map이라도 1x1 convolution filter 여부에 따라 parameter 개수가 달라진다.

parameter 개수
AlexNet(8-layers) : 60M
VGGNet(19-layers) : 110M
GoogLeNet(22-layers) : 4M
ResNet(2015년 ILSVRC 우승)
일반적으로 parameter 숫자가 늘어나게 되면 overfitting(training error와 test error gap 증가)이 발생한다.
그런 측면에서 generalization performance를 높이기 위해 parameter의 개수는 줄이고 layer를 깊게 쌓음으로써 이러한 문제를 해결했었다.
다만 이로 인해 또 다른 문제가 야기됐다.
deeper neural networks ard hard to train. 즉, 네트워크가 깊어질수록 train error과 test error가 같은 양상인데도 학습이 잘 되지 않아서 train error가 작음에도 test error 큰, 두 error간 간극이 발생한다는 점이다.
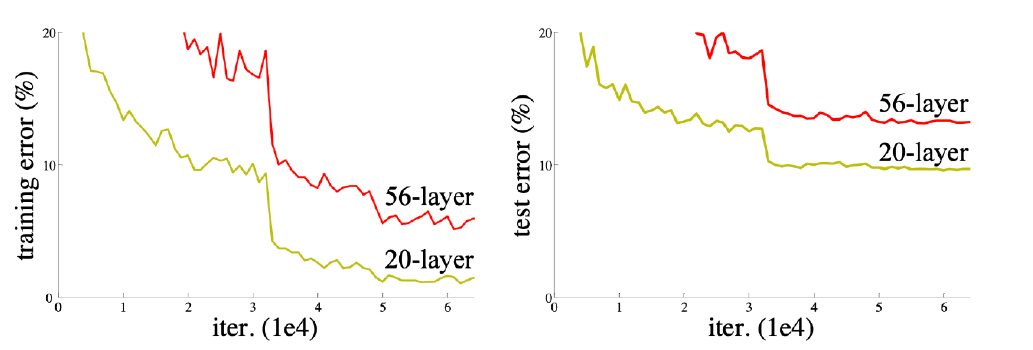
ResNet 다른 방법으로 이 문제를 다른 방법으로 해결했다.
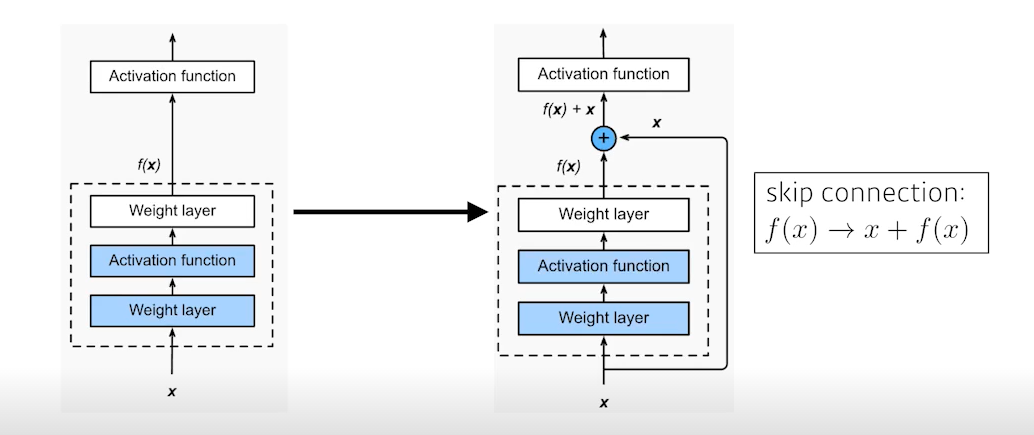
Add as identity map(skip connection)
이 방법은 input을 1단짜리 convolution layer의 출력 값에 더해주는 것이다. 여기서 원하는 건, convolution layer가 학습하고자 하는 것은 loss에 대해서만이다.
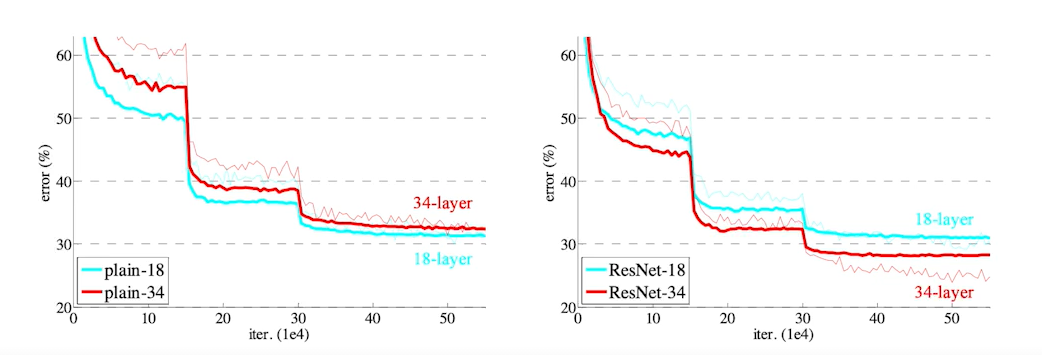
그 결과 아래와 같이 학습이 잘 되어, 결과적으로 두 error 사이의 간극을 줄임으로써 generelization performance 향상시켰다.
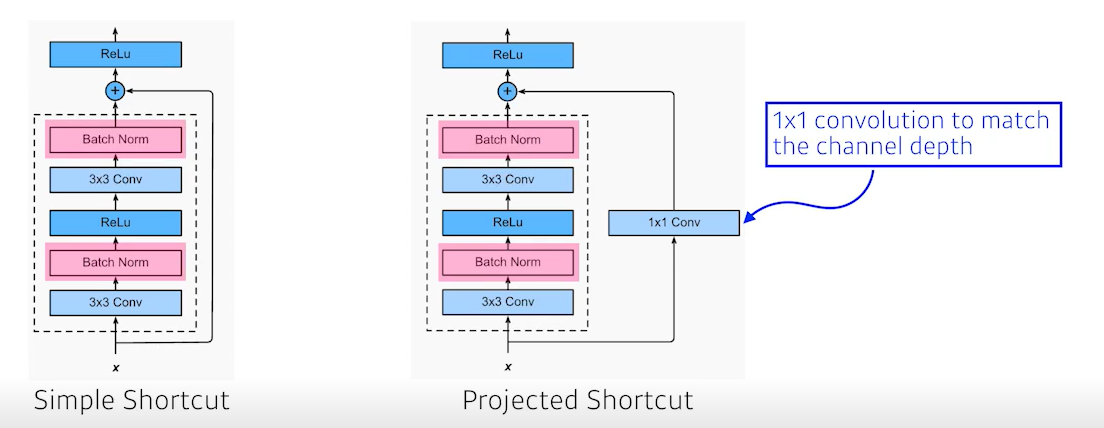
단, 이 방법을 사용하려면 convolution layer를 거친 output과 입력 차원이 같아야 한다. 그래서 1x1 conv로 차원수를 맞춰준다. 하지만 보통 simple shortcut을 많이 사용한다.
또한 여기서 볼 부분은 batch-norm이 conv 이후(relu 전)에 있는 것인데, batch-norm이 relu 전/후 어디서 위치해야 더 성능이 잘나온다는 것에 논란이 있다.
하지만 논문 상에선 conv 다음에 위치한다.
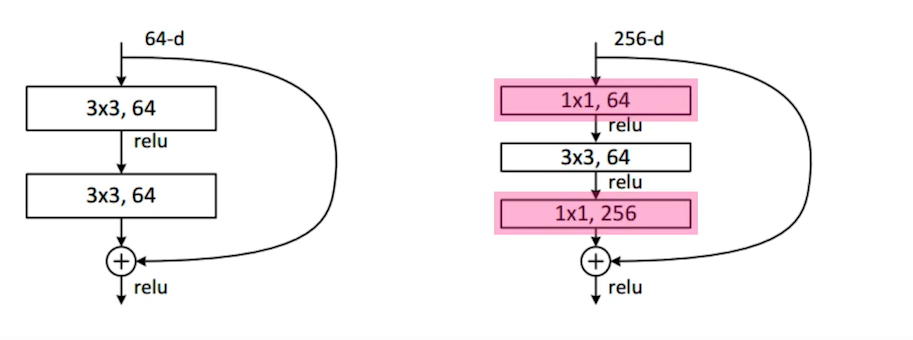
또한 여기서도 Bottlenck arcitecture(GooGleNet, inception block)를 사용했다. 3x3 전 depth를 줄이고, input과 depth를 늘려주었다.
결과적으로 AlexNet부터 Inception-v4까지 performance는 증가하고, parameter 개수는 줄어든다.
(사실 inception보단 resnet의 성능이 더좋다고 한다. 이 그림만 그런 듯..)

DenseNet
RegNet의 shortcut과 유사하지만, 더하지 말고 concatenation
(더하게 되면 두 값이 섞이므로 따로 보자는 의미!)
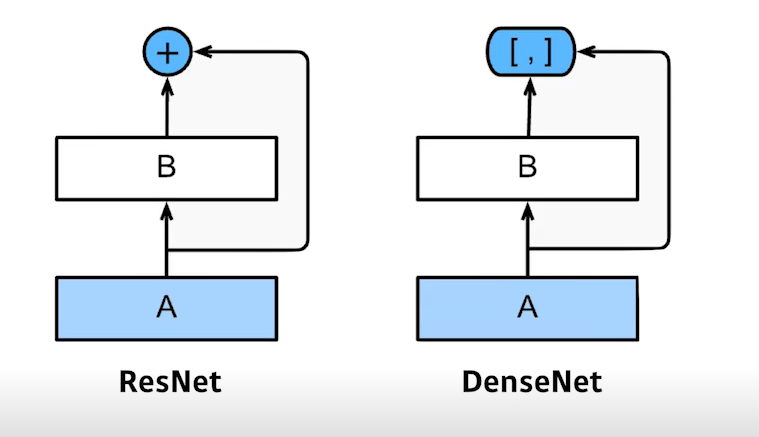
문제는, concat 시 channel이 점점 커지게 됨(뒤에 있는 건 앞의 출력을 다 concat 하기에...)
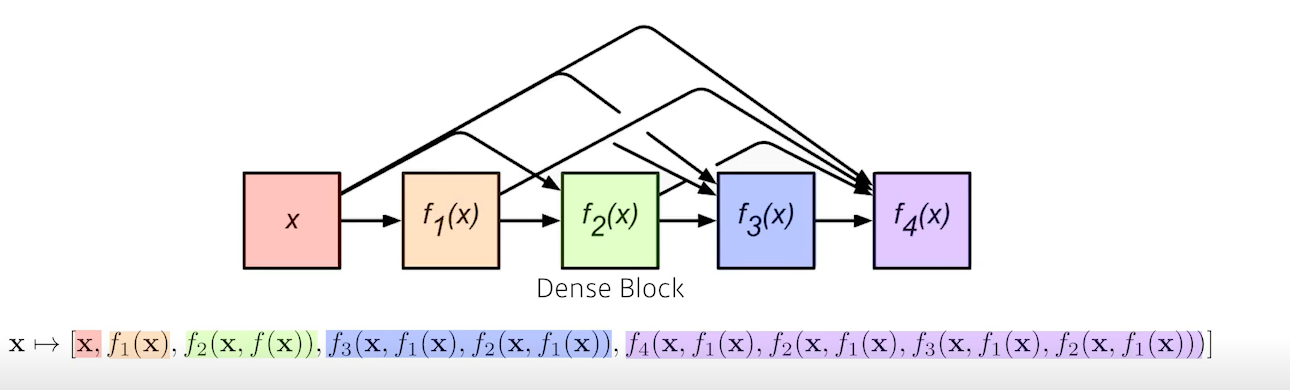
따라서 다음과 같이 전략을 세웠다.
- Dense Block
- Each layer concatenates the feature maps of all preceding layers
- The number of channels increases geometrically
- Transition Block
- BatchNorm -> 1x1 Conv -> 2x2 AvgPooling
- Dimension reduction
Dense block => concat을 통해 feature 맵을 키우고
transition block => batchnorm 후 1x1 conv로 channel을 줄임

summary
- Key takeaways
- VGG : repeated 3x3 blocks
- GooGleNet : 1x1 convolution
- ResNet : skip-connection
- DenseNet : concatenation
