[BoostCamp AI Tech / Day 8, DL basic] computer vision Applications
[boostcampAI U stage] week2
Semantic Segmentation
- Dense classification, per pixel classification과 같이도 불림
- 이미지의 모든 픽셀이 어떤 label에 속하는지 분류하는 문제
- 사용 예시) 자율 주행, 운전보조장치, 라이다와 같은 센서를 활용하지 않고 이미지만 가지고 하는 여러 문제에 대해서 semantic segmantation이 매우 중요
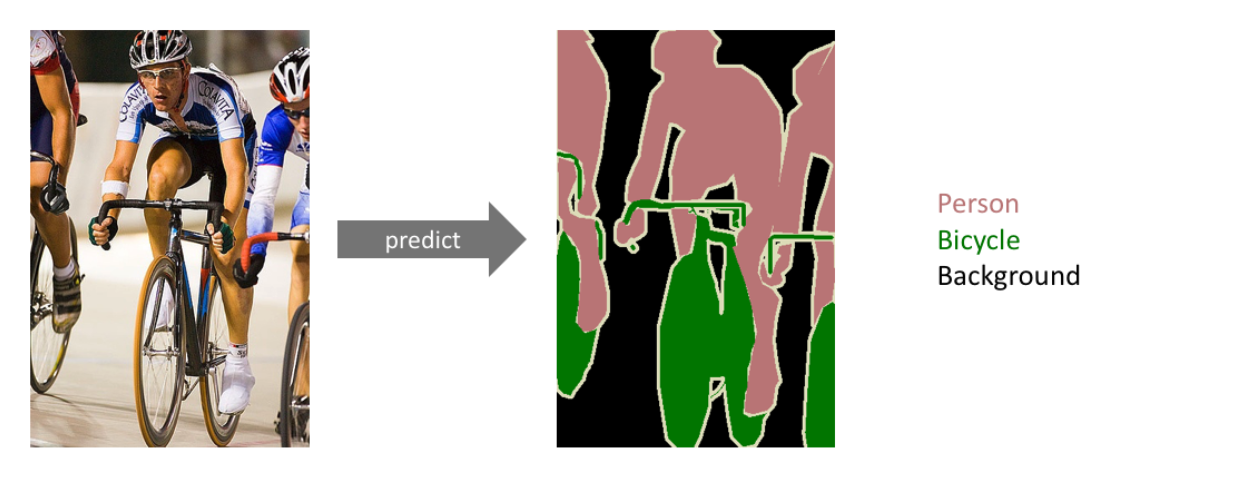
Semantic Sementation의 가장 기본적인 technic : Fully Convolutional Network
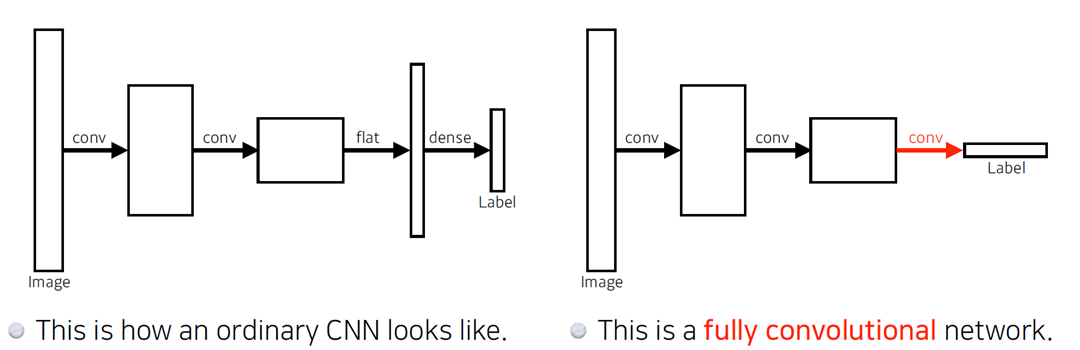
Fully Convolutional Network
- CNN vs FCN
- CNN에서 Dense Layer를 없앤 network로, 이 없애는 과정을 Convolutionalization
- FCN의 이점은 Dense Layer가 없다는 것인데, 결과적으로 봤을 땐 동일
이 network의 장점은 Dense Layer가 없다는 것인데, 결과적으로 봤을 땐 input과 output의 출력은 동일하다.
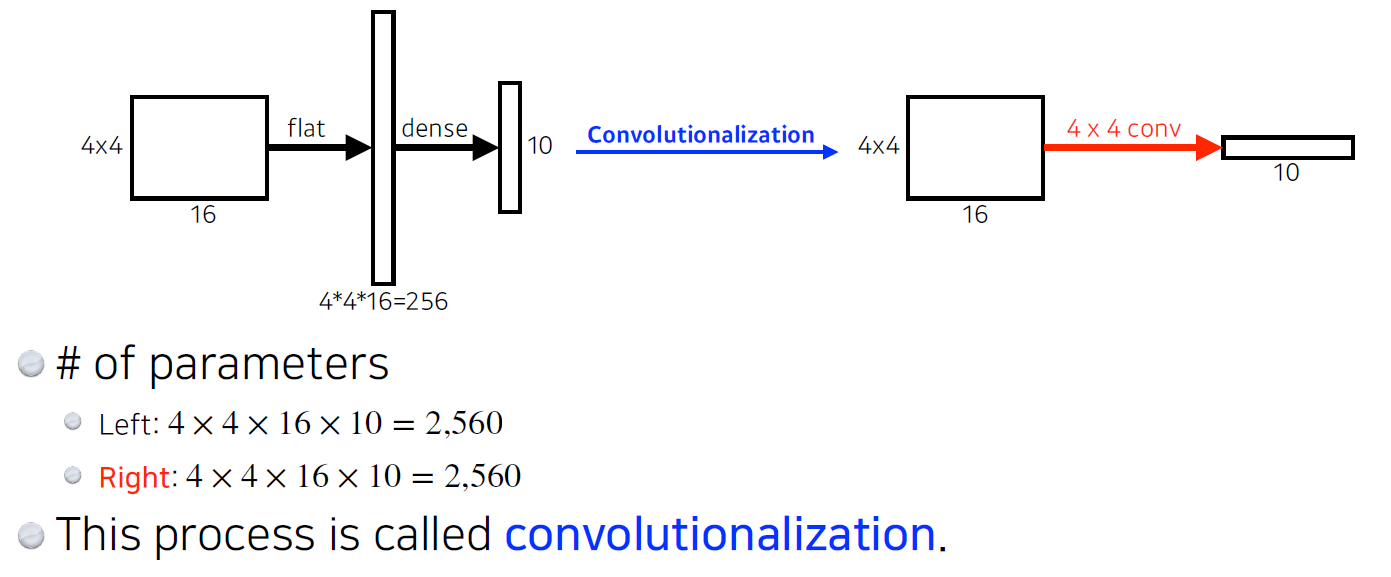
아래와 같이 결과적으로는 같은 parameter를 가지고, output vector 형태만 다른데 왜 Convolutionalization을 할까?
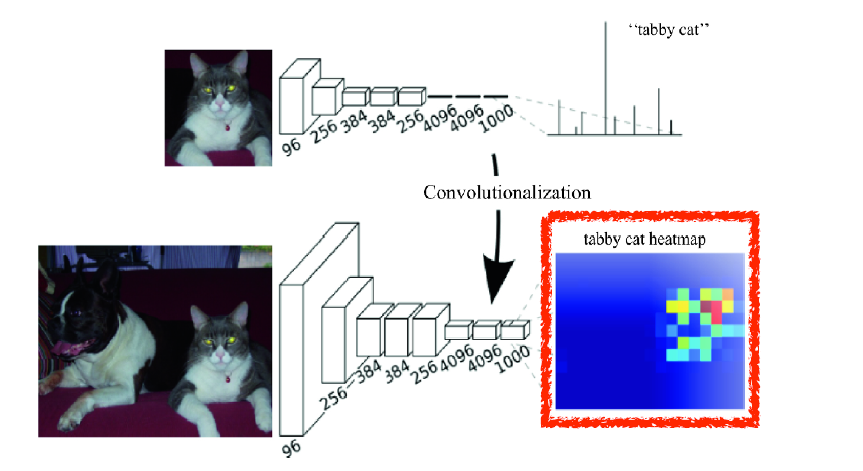
Benefit of FCN
- Transforming fully connected layers into colvolution layers enables a classification net to output a heat map
- intput의 speicial dimension에 independent
기존 network의 경우 reshape으로 인해 input이 다르면 동작을 안하지만, FCN은 input image의 special dimension에 상관없이 kernel이 동작하기에, input size가 커지면 output feature map은 heatmap 과 같이 출력될 수 있다.
결과적으로 FCN를 통해 classification만 할 수 있던 network가 semantic segmentation과 같은 작업도 수행할 수 있다.
딘. FCN는 input size와 무관하게 동작하지만 network를 지나며 feature map의 special dimension이 줄어드는데(coarse output), 더 복잡한 작업(classification, segmantic segmantation 등등)을 위해 늘리는 작업이 필요하다.
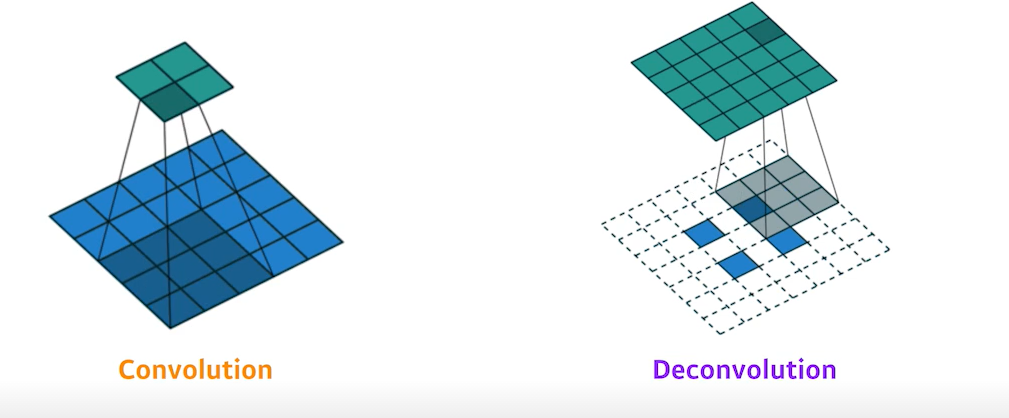
Deconvolution(Upsampling)
시간되면 내가 읽어보려고 남겨놓은 링크, Deconvolution and Checkerboard Artifacts
- Deconvolution은 두 가지 방법이 존재
- 1) pooling layer를 복원
- 2) Cov layer의 stride에 의한 축소를 복원
Pooling layer 복원
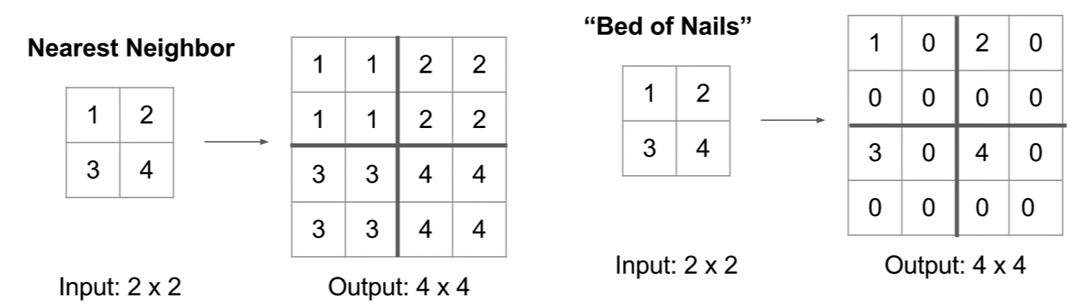
1) Nearest Neighbor Unpooling : 같은 값으로 복원
2) Bed of Nails Unpooling : 특정 위치만 값을 저장하고, 나머지는 0으로 만드는 방법 baddddddd
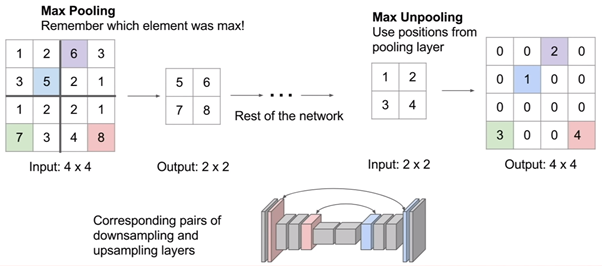
3) Max Unpooling : max pooling 된 위치를 기억하고, 그 위치에 값을 복원하는 방법
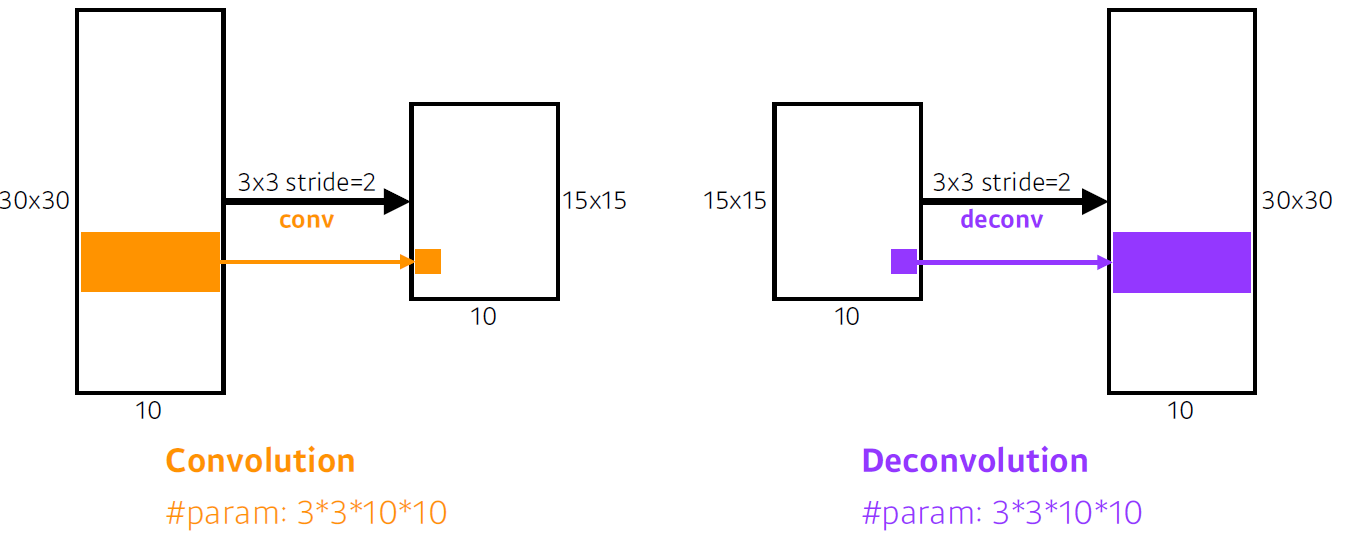
convolution transpose(강의에서 소개해준 방법)
-
직관적으로는 convolution의 역 연산
-
엄밀히 보면 convolution의 역 연산은 불가능한 작업
- 합쳐진 정보를 나눌 때 기존에 어떤 형태로 있었는지에 대한 정보가 없기 때문 ex) 1+5 =6 -> 6 =>1+5,2+4,3+3,7-1,...
-
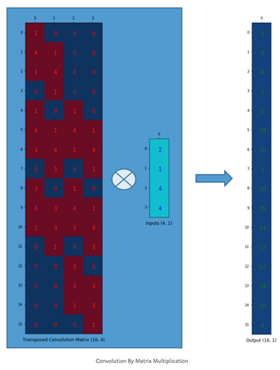
Transpose Convolution 은 행렬을 이용한 방법
- conv : padding = 0, stride = 1, 3x3 kernel, 4x4 input feature map
- 행렬 : 3x3 kernel을 4x16 matrix (output featuremap element 개수, input feature map element 개수) 로 만들고, input feature map은 flatten하여 행렬곱 연산을 하면 그림의 우측과 같이 output feature map이 생성됨
- conv : padding = 0, stride = 1, 3x3 kernel, 4x4 input feature map
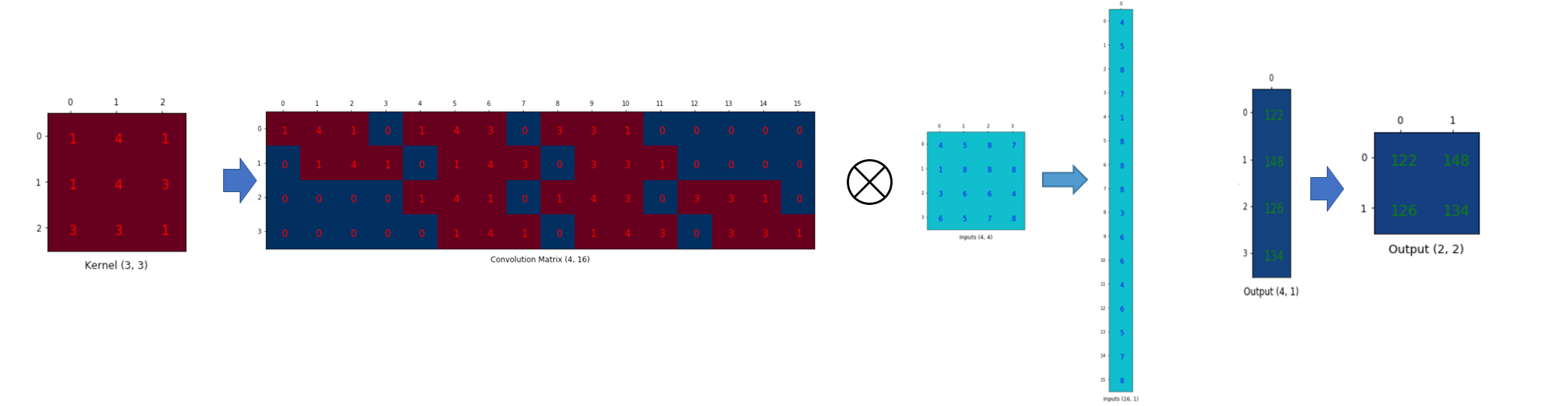
- Cov trans : 반대로 동일한 조건에서, 3x3 kernel로 만든 matrix shape을 Transpose 해주고, intput feature map을 flatten 해준 뒤 행렬곱을 하면 원하는 형태의 output feature map을 얻을 수 있음
result
F
Detection
- Detection 역시 이미지 내에서 어떤 물체가 어딨는지를 찾고자 하는 것으로 segmenttation과 비슷하지만 per pixel이 아닌 bounding box를 찾는 것으로 접근
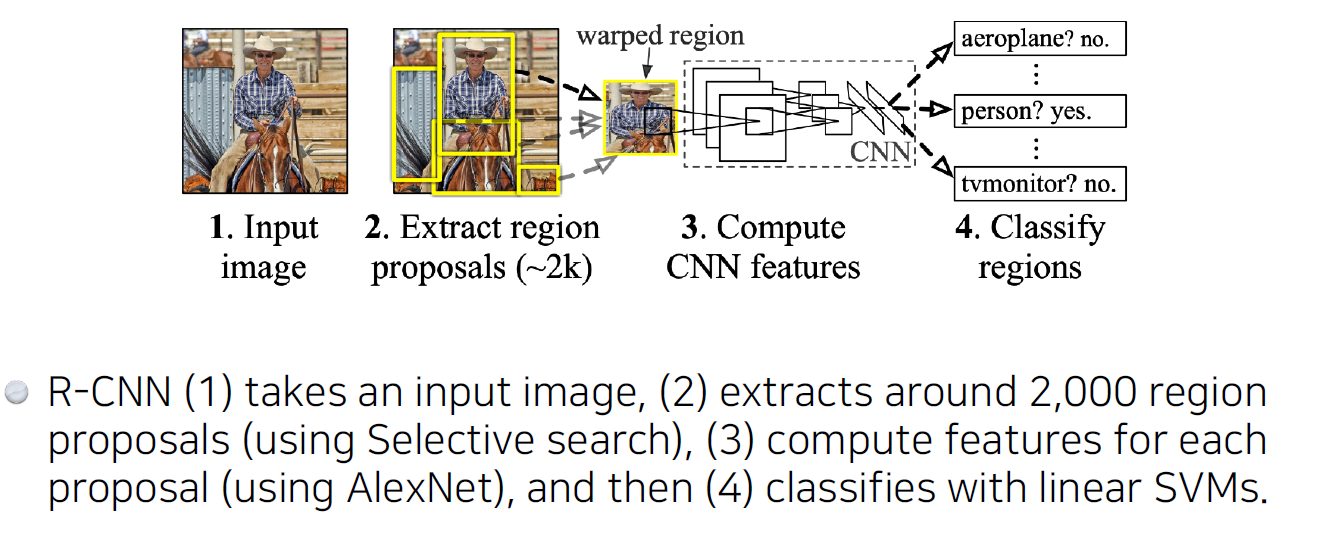
R-CNN
1) 이미지를 넣으면
2) 거의 2000개의 영역(patch, region, bounding box(bounding box regression))을 추출하고
3) 다양한 bounding box로 인해 다른 크기로 출력된 region들의 크기를 통일시키고, feature를 뽑고
4) SVC으로 분류
- brute force 느낌이며, 추출한 region들을 모두 alexnet으로 학습하여 2천개의 convolution feature map를 추출한 다음 각각을 classification하므로 오랜 시간이 걸림
결과적으로 cat을 dog과 같이 detect하는 것을 보면 완벽하진 않지만 detection 문제를 풀고자 했던 시도가 있었다.

SPPNet
- In R-CNN, the number of crop/warp is usually over 2,000 meaning that CNN must run more than 2,000 times(59s / image on CPU)
- However, in SPPNet, CNN runs once.
- image 안에서 2K 개의 bounding box를 뽑고, image 전체에 대해 conv feature map을 만들어서 bounding box에 포함된 feature map의 tensor만 추출하자는 idea 적용
- 결과적으로 R-CNN과 비슷하지만 방법이지만 SPPNet 상대적으로 매우 빠름
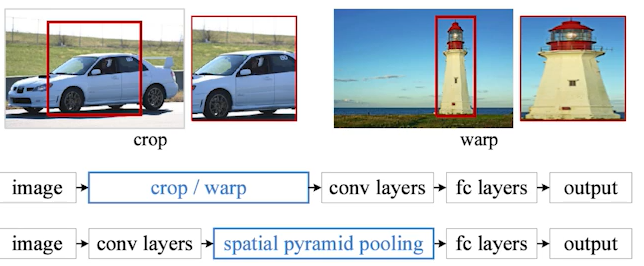
Fast R-CNN
- 하지만 SPPNet 마저도 느릴 수 밖에 없음
- convolution을 한 번만 수행하지만, 2K 개의 bounding box 내의 tensor 추출하여 SPP를 통해 하나의 vector를 만들다음 분류를 해야하기 때문
- Fast R-CNN도 SPPNet에서 가진 것과 동일한 컨셉이지만, 마지막에 Nueral Net을 통해 classification과 bbox(bounding box) regression을 수행한 특징이 있음
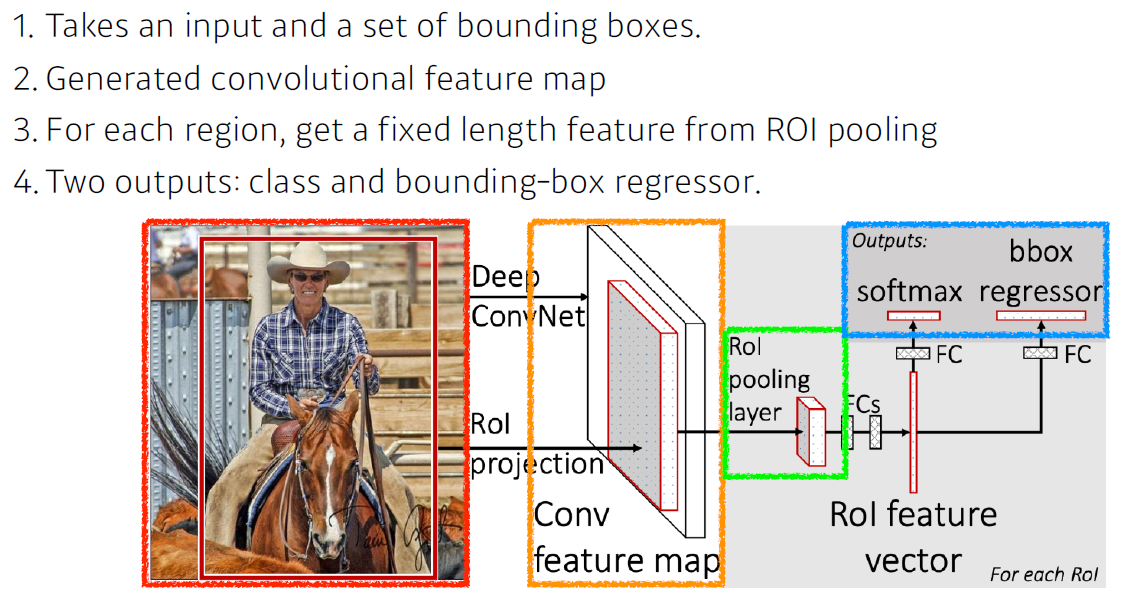
Faster R-CNN
- Fast R-CNN에 image를 통해 bounding box도 뽑아내는 Region Proposal Network도 학습하는 것이 더해짐
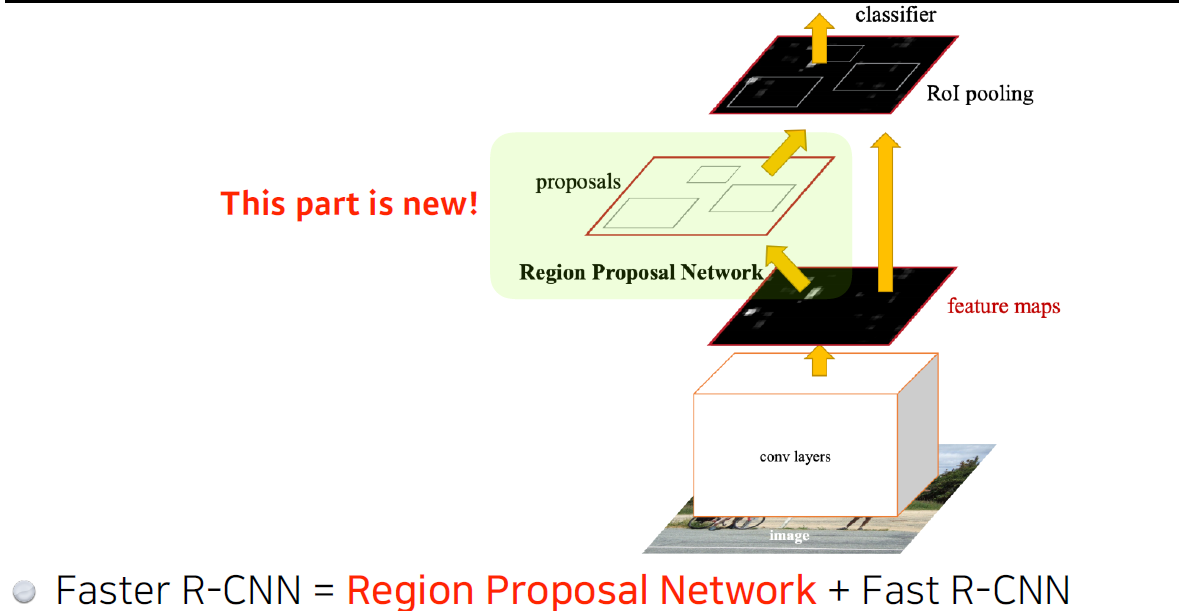
RPN(Region Proposal Network)
- 이미지가 있으면 이 이미지에서 특정 patch가 bounding box로써 의미가 있는지, 이 내부에 어떠한 물체라도 있는지를 찾아줌
- RPN을 해주기 위해 필요한 것이anchor box(미리 정해놓은 bounding box의 크기)
- 이미지 내 특정 크기의 물체가 있을 것이란 것을 알고 있는 상태에서 K개의 고정된 templete의 anchor boxes를 갖는게 RPN의 특징
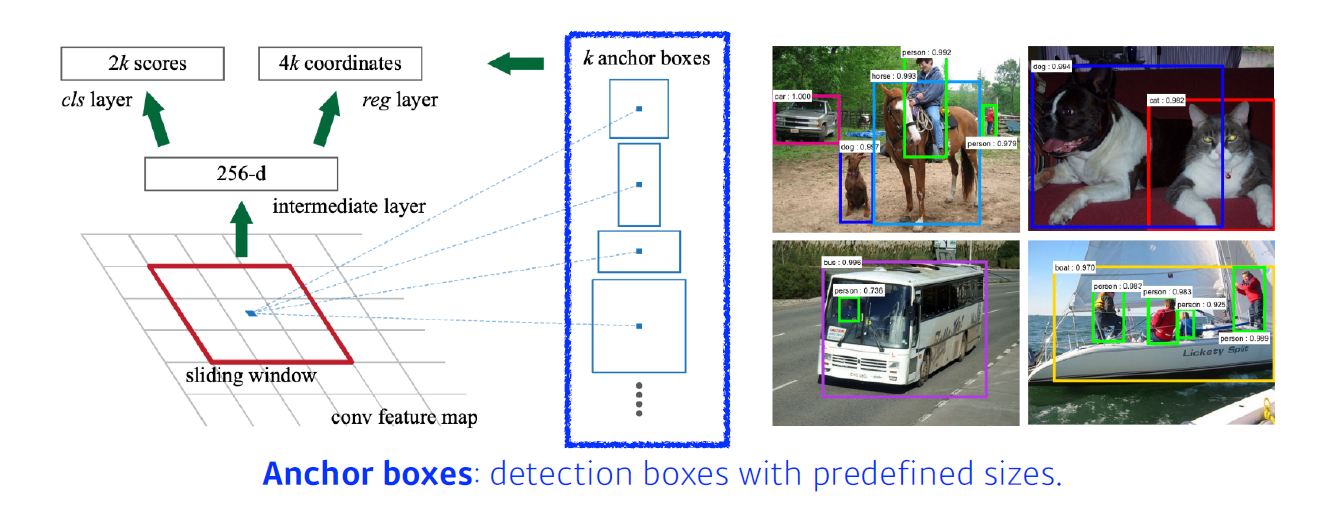
- RPN 역시 FCN을 활용
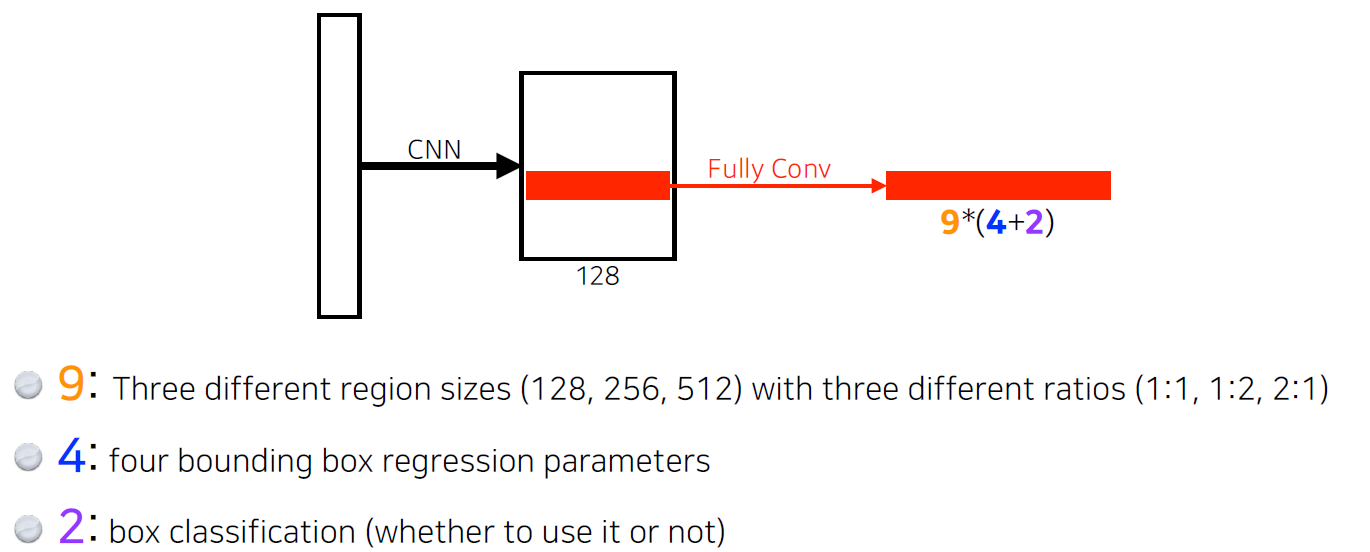
- conv filter가 모든 영역에 대해 찍어보기에 이미지 내의 모든 정보를 갖고 있으며, feature map은 9*(4+2)의 depth를 가지게 됌, 이걸 통해 해당 영역에서 어떤 bounding box를 사용할지, 말지 등을 결정
- 9 : 3개의 region size * 3개의 ratio
- 4 : width, height, x-offset, y-offset 조절로 4가지 형태
- 2 : 해당 bounding box가 쓸모 있을지
그 결과 기존 Fast R-CNN보다 조금 더 성능이 개선됨

YOLO(최근 YOLOv5까지 나옴)
- faster R-CNN보다 매우 빠름
- 이미지 한 장을 찍으면 바로 output이 나오는 네트워크 구조
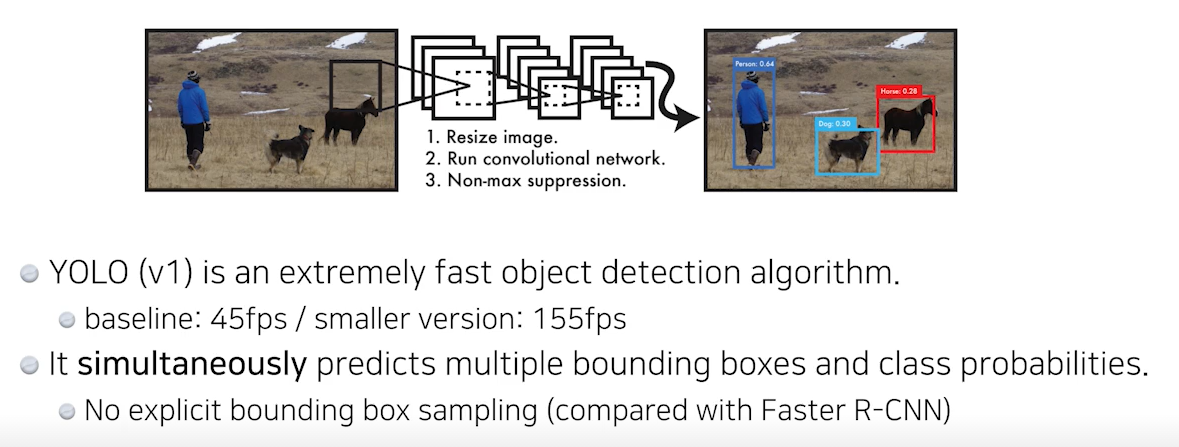
- S x S grid 내에서, 물체의 중심이 grid cell 내에 있을 경우, bounding box와 어떤 class인지 같이 예측

2-1. anchor box처럼 predefined box가 있는게 아니라, 각 cell은 B개의 bounding box의 x,y, w(width), h(height)를 찾아주고, 그 bounding box가 쓸모있는지를 예측

2-2. 동시에 grid cell에 속하는, 중간에 있는 object가 어떤 class에 속하는지 예측

- 마지막에, 두 정보를 취합하면 bounding box와 그 box가 어떤 class인지 출력
- 이 때 tensor의 크기는 (SxS, grid cell 개수) X (Bx5(x,y,w,h,yes/no) X C(class 개수)

그 결과 아래와 같이 detection을 한다!!

이후 YOLO는 거의 real time을 유지한 채 성능이 개선되고 있다!!
참고
