sequential data을 다루는데 가장 큰 어려움은? 받아들이는 입력의 차원을 모름..
Sequential Model
sequential data를 다루는데 가장 큰 문제는 무엇일까?
- 바로 입력의 길이가 제한되어 있지가 않다는 점이다. 따라서 input length가 어떻든지 동작을 sequential model은 동작할 수 있어야 한다.
Naive sequence Model
- 여러 개의 입력이 들어왔을 떄 다음 번 입력을 예측(e.g., language model)
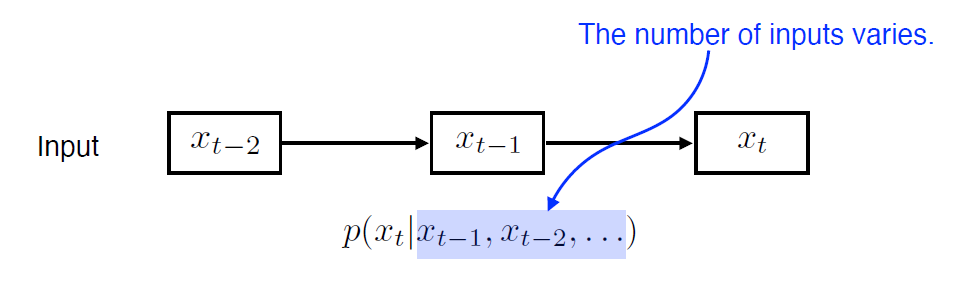
Autoregreesive model
- 자기회귀모델로, 과거 특정 시점까지의 데이터를 통해 현재를 예측
- AR(1) 과거 1개만, AR(2)과거 2개, AR(n) 과거 n개만 고려
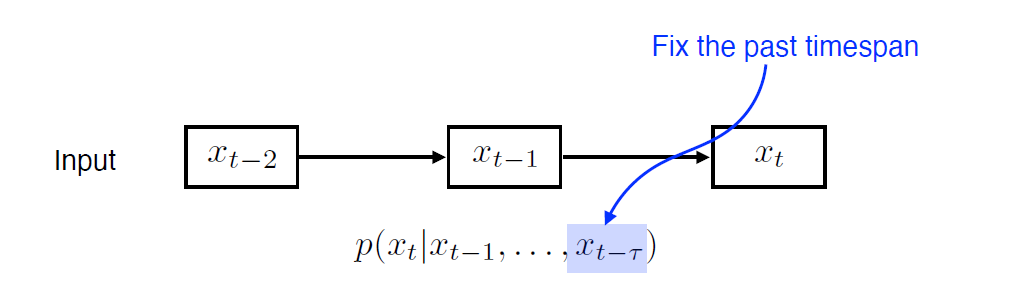
Markov model(first-order autoregressive model)
- 마르코프 가정 : 현재 t시점의 state 는 바로 전 과거인 t-1 시점의 state 에만 dependent
- 따라서 많은 데이터가 버려짐
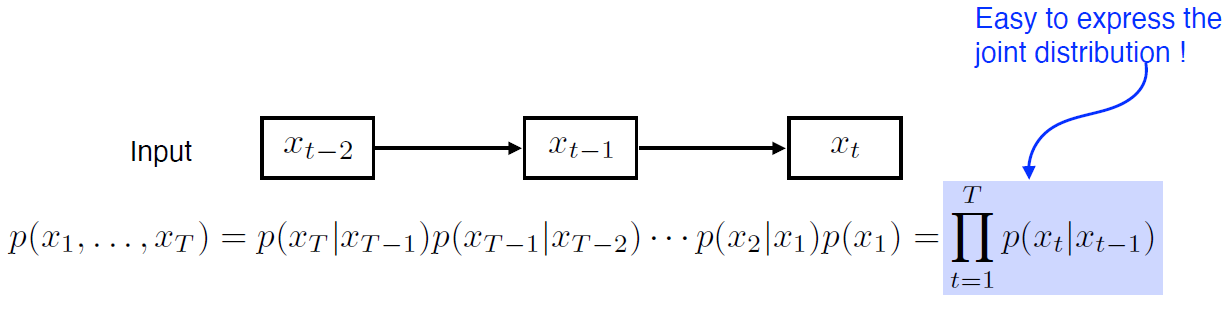
- Karkov model(first-order model)의 가장 큰 장점은 joint distribution으로 표현하기에 매우 쉬움
Latent autoregressive model
-
Markov model, AR(1) model의 단점은 과거의 많은 시점의 데이터를 고려할 수 없는 것
-
반면, Latent autoregressive model는 hidden state가 들어가서 과거의 정보를 summarize하고, t+1은 과거 t 시점의 hidden state 하나에 의존
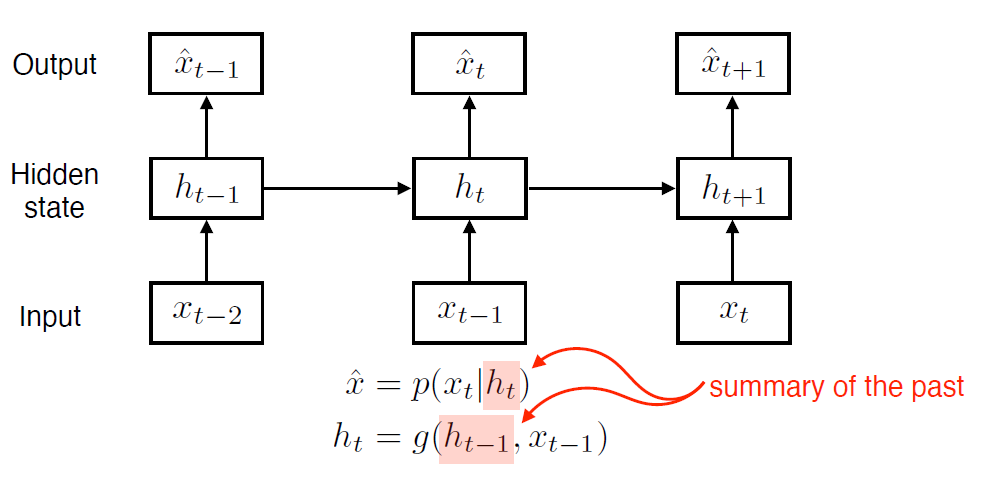
RNN
-
이러한 sequential data를 다루기 위한 concept을 가장 잘 표현한 게 Recurrent Neural Network(RNN) model
-
MLP와 동일하나, 자기 자신으로 돌아오는 구조가 하나 존재함
-
즉, 시점의 hidden state는 input 뿐만 아니라 시점의 hidden state에도 dependent함.
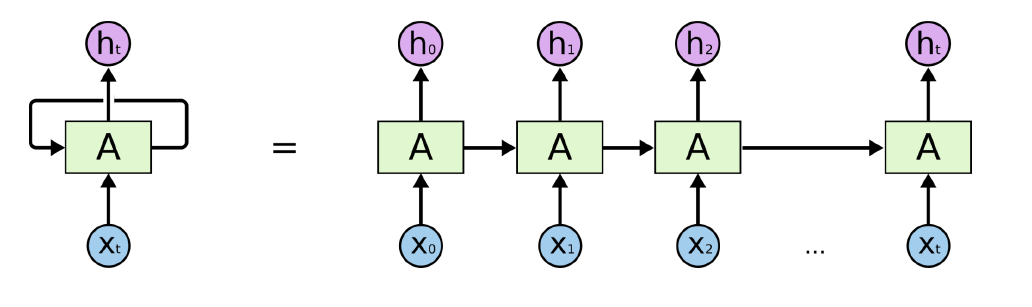
-
RNN은 이전 시점들의 정보를 다음 시점에 이용할 수 있는 장점이 있지만, 반대로 이전 시점과 멀어질수록 정보를 소실하는, 장기의존성 문제가 있음
-
따라서 이 문제를 개선한 모델로 LSTM(Long short-term model)가 있으며, 이와 유사한 GRU(Gated Recurrent Units)이 있음
-
RNN 학습이 어려운 이유를 다시 보면, 아래 네트워크를 풀어놓은 구조 및 수식을 보면, t 시점이 진행될수록 이전 시점의 hidden state들이 중첩되는 구조를 볼 수 있음
-
따라서, 을 기준으로 보면 를 계산할 때 4번의 활성함수 및 가중치 행렬과 곱해져서 다음과 같은 결과가 문제가 발생한다.
- 활성함수가 sigmoid면 0으로 수렴하여 vanising gradient
- 활성함수가 relu면서 가 양수면, 원상태에 가 무한히 곱해져서 exploding gradient
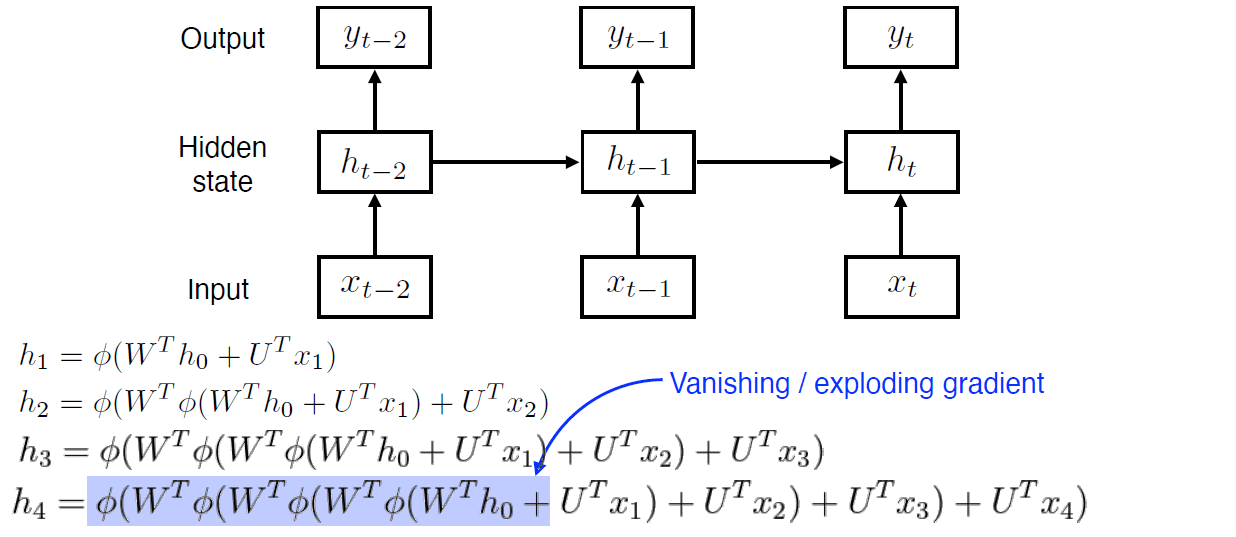

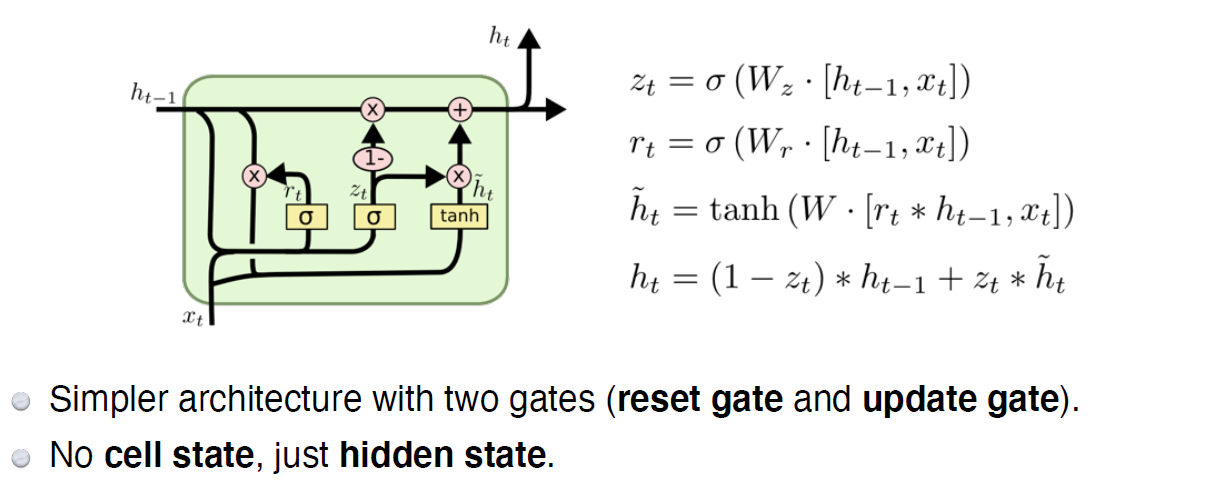
LSTM(Long Short Term Memory)
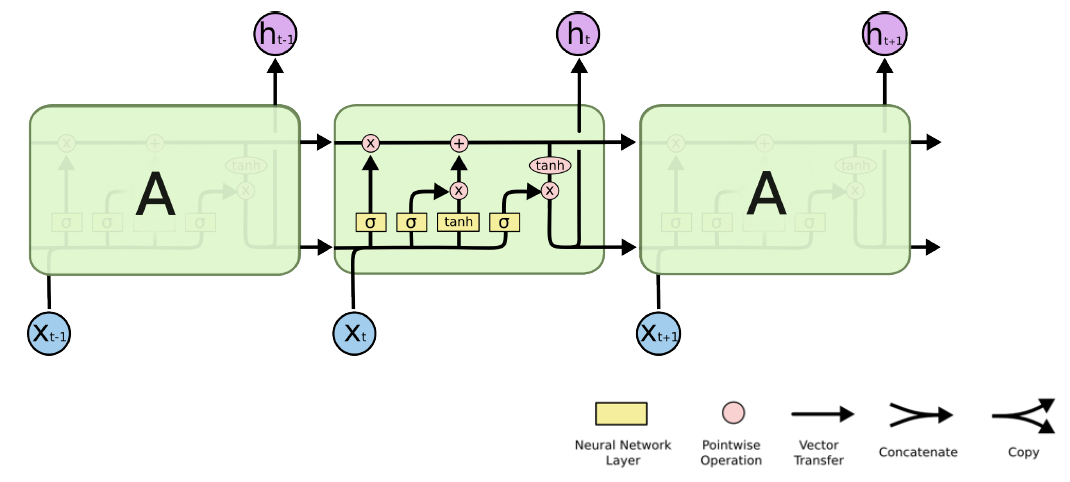
- : Input(단어, embedding vector 값,...)
- : Output(Hidden state)

LSTM Core idea
- core idea첫 번째는 중간에 흘러가는 cell state(time step 까지 들어온 정보를 summarize하여 저장)
- 컨베이어 벨트와 같이, 어떤 정보가 유용한지/ 혹은 유용하지 않은지를 가지고 이 정보들을 조작하여 다음으로 넘기는 역할을 수행
- 여기서, 어떻게 조작할 지에 대한 정보가 gate에 해당하며, 되어 있는 것들이 gate

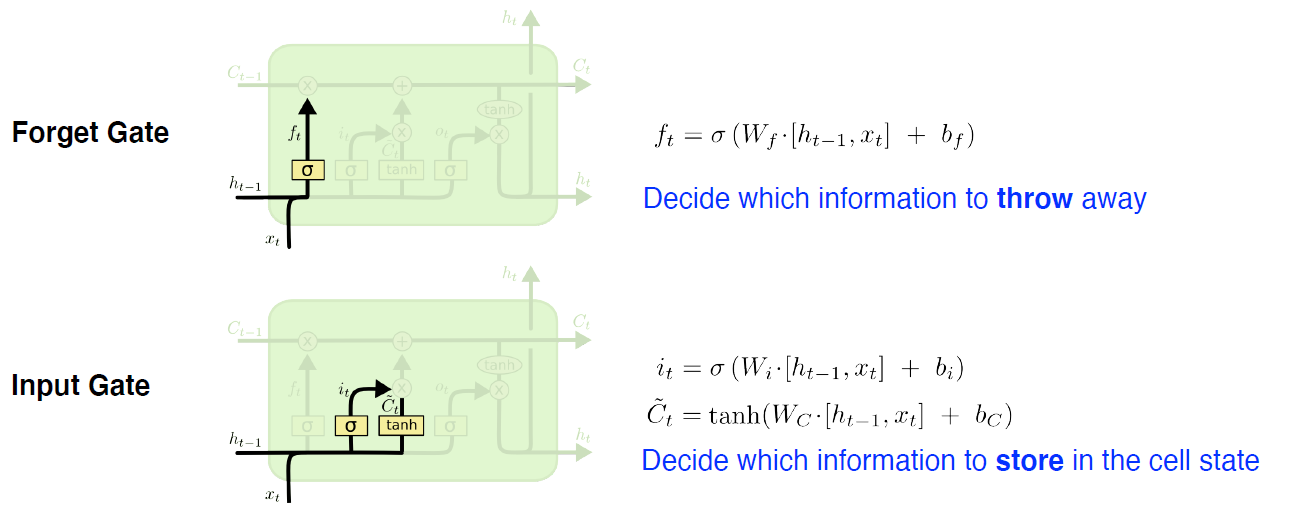
Forget gate
-
Decide which information to throw away
-
여기서 sigmoid를 통과하므로 항상 0~1사이 값을 갖게 됨
-
역할 : 이전 cell state에서 나온 정보 중에 어떤 것을 버리고 어떤 것을 살릴 지 정해줌
Input gate
-
Decide which information to store in the cell state
-
: [, ]이 들어왔을 때 무조건 cell state에 저장하는게 아니라 이 정보 중 어떤 정보, 즉 정보 자체를 올릴지 말지를 정함
-
(올릴 정보, cell state candidate) : [, ]이 들어온 다음 따로 학습되는 NeuralNet을 통해서 나오는데, 를 통과하여 모든 값이 -1 ~ +1로 정규화된다. 이 값을 토대로 나온 와 과 섞어서 현재 시점의 cell state를 update
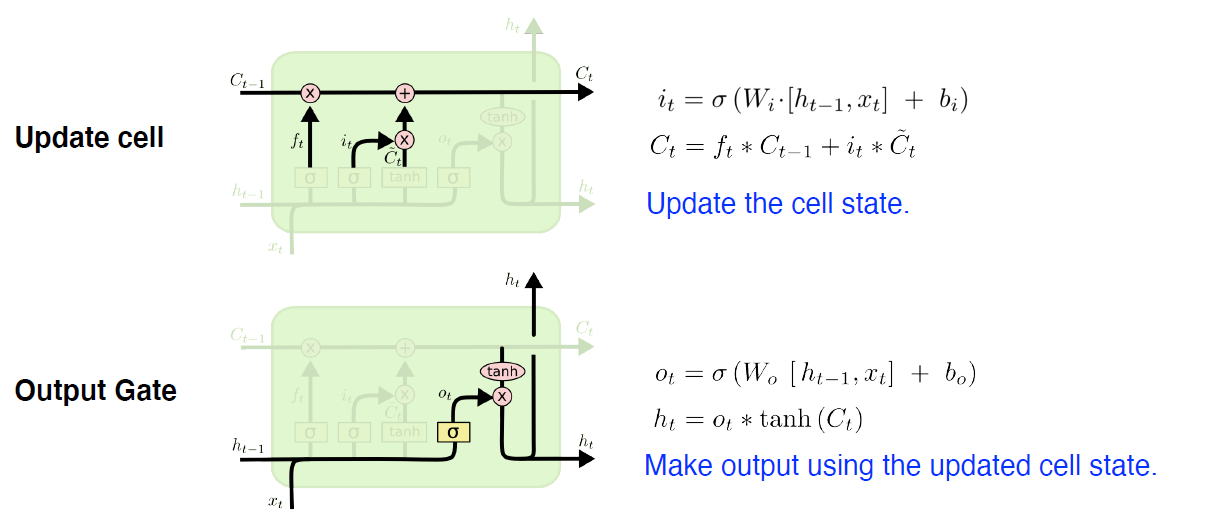
Update
-
Update the cell state
(element-wise product)
-
forget gate 만큼 이전 cell state 정보를 버리고 input gate 만큼 cell state를 update
cell state가 update 되었으니 이것을 그대로 output으로 출력할 수 있는데, 그 경우는 GRU!!, LSTM에선 한 번 더 조작
Output Gate
-
Make output using the updated cell state.
(element-wise product)
-
어떤 값을 출력할 지에 대해, output gate 만큼 에 곱하여 출력
To summarize LSTM
- 입력 : (input), (previous hidden state), (previous cell state) 값들이 neurnet 안으로 들어오면
- 먼저, 어떤 정보를 버릴지(forget gate)를 지나서
- 어떤 정보를 추가할지(input gate) 를 정하고
- forget gate에서 나온 cell state와 cell state candidate를 다시 조작하여 새로운 cell state를 만들고
- 그 정보를 얼만큼 밖으로 빼낼지(output gate)를 정하여 최종값을 출력
GRU
- 뉴욕대 조경현 교수님이 만드신 모델로
- LSTM엔 gate가 3개라 paramter가 많이 필요해서 paramter 및 gate를 줄인게 GRU