[BoostCamp AI Tech / Day 9, DL basic] Sequential Models -Transformer
[boostcampAI U stage] week2
Sequential Model
- What makes sequential modeling a hard problem to handle?
어떤 문장이 있는데 문장의 길이가 잘렸거나(trimmed), 중간 단어가 몇 개 빠졌거나(omiited), 중간에 단어가 섞인 경우(permuted), sequential 하게 입력이 들어가게 되면 상기와 같은 문제가 있는 경우 모델링하기가 매우 어렵다. 이런 문제를 해결하고자 transformer가 등장했고, transformer는 self attention이란 구조를 사용하고 있다.

transformer
- Transformer is the first sequence transduction model based entirely on attention.
RNN은 입력이 순차적으로 들어갈 때 이전 cell state가 다음 cell state에 들어가며 반복하는 재귀적 구조이고,
transformer는 attention을 구조를 활용한 sequence model이다.
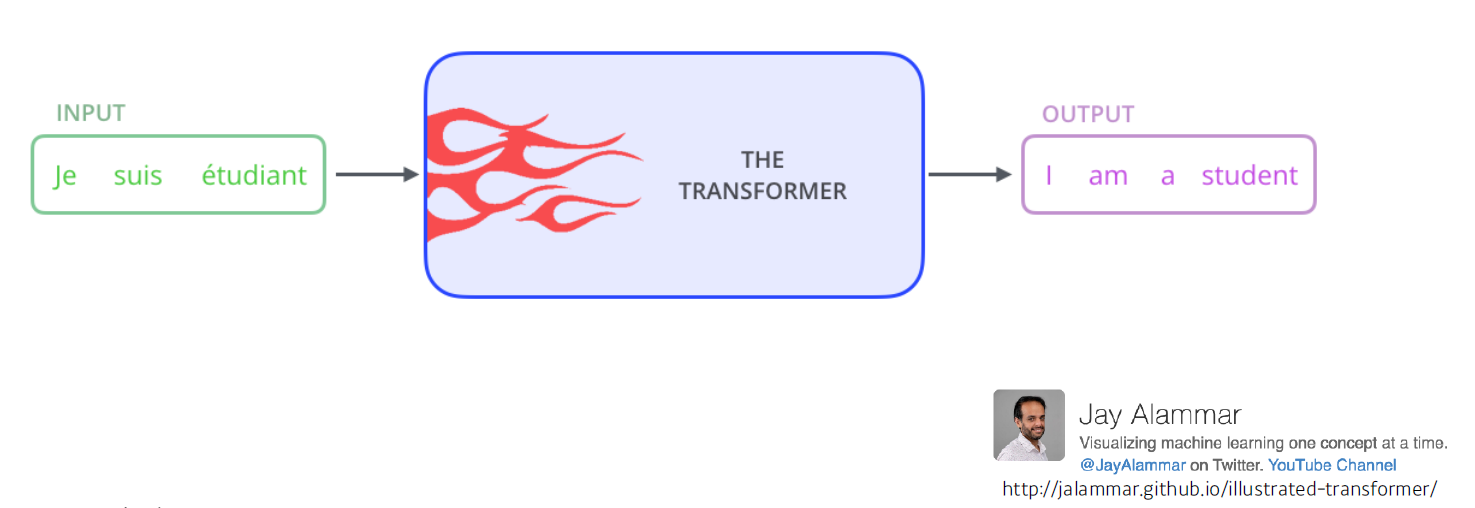
- From a bird's-eye view, this is what the Transformer does for machine translation tasks.
이 방법론은 sequential한 데이터를 처리하고 encoding하는 방법이기에 nmt 문제에만 적용되진 않는다.
- image classification, image detection, visual transformer, DALL-E 등등
신경망 기계 번역(Neural machine translation, NMT)은 일련의 단어의 가능성을 예측하기 위해 인공 신경망을 사용하는 기계 번역 접근 방법
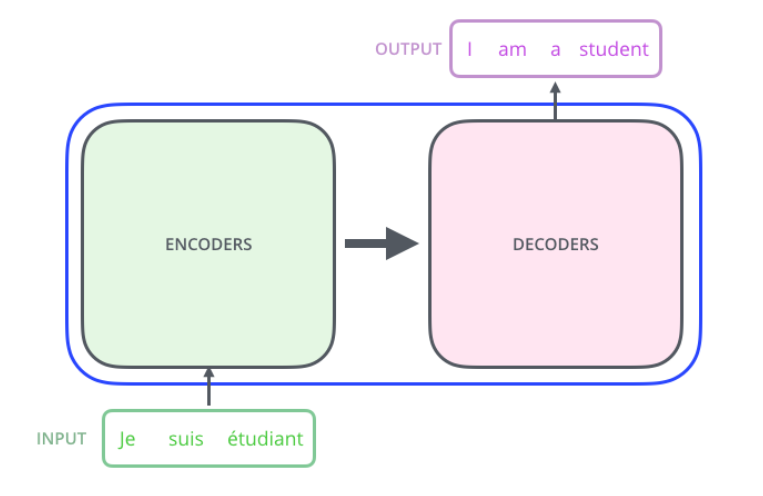
- If we glide down a little bit, this is what the Transformer does
Transformer가 하고자 하는 것은, 어떤 문장(seq)이 주어지면 그것을 다른 문장(seq)으로 바꾸는 바꾸는 것(seq-to-seq)
- e.g., 영어 문장을 한국어 문장으로 번역 등...
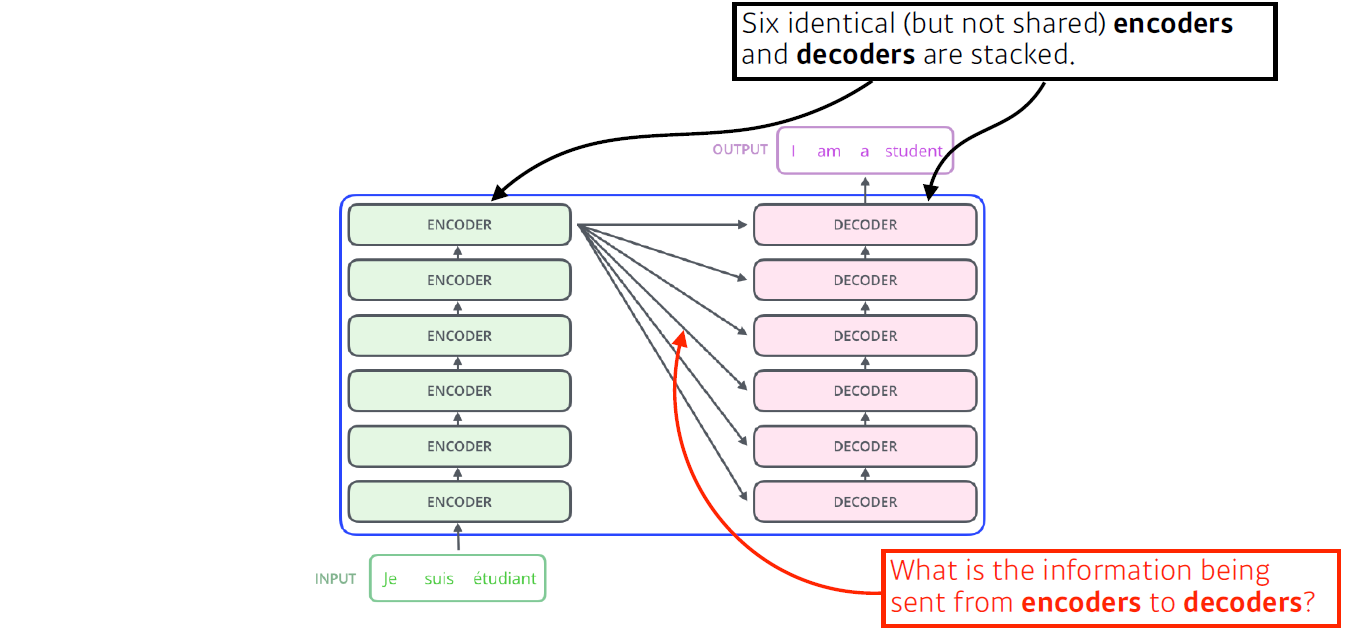
예를 들어, 입력이 3개 단어의 불어로 되어 있고, 출력이 4개의 영어 단어로 되어 있다. 이것을 봤을 때, 입력 seq와 출력 seq의 1)개수 및 2)도메인 이 다를 수 있다는 것을 알 수 있다. 하지만 model은 하나다
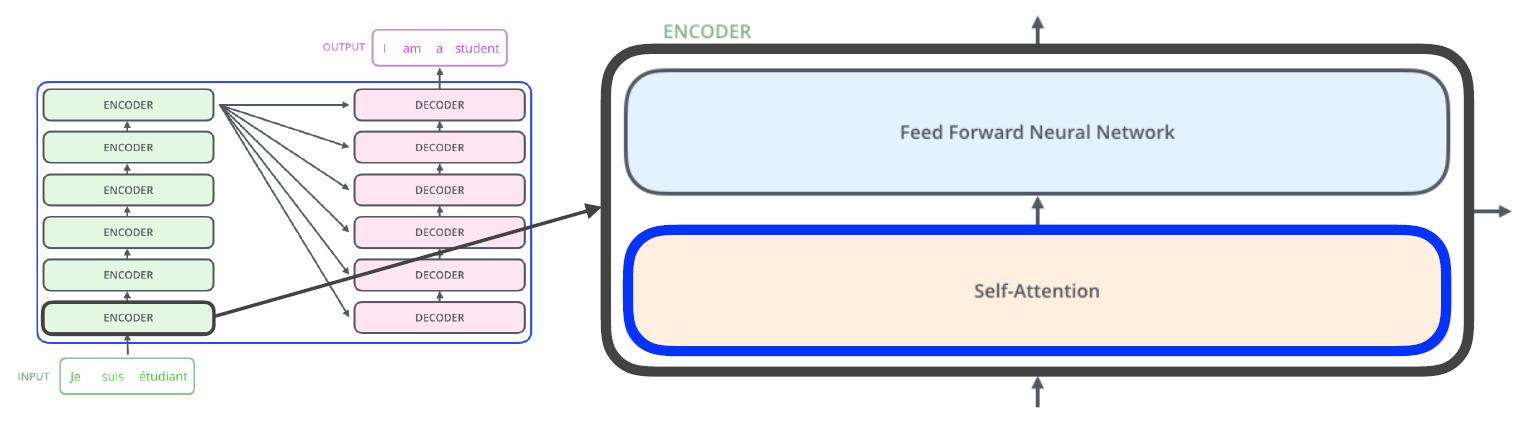
RNN의 경우 3개의 단어가 들어가면 3번의 network가 동작해야 하는데, Transformer의 encoder(self는 몇 개의 단어가 입력되던 한 번에 수행한다.(물론 generation 할 때는 autoregressive하게 한 단어씩 만든다.)
한 마디로 정리해보면, encoder 부분, 혹은 self attention 구조는 n개의 단어를 한 번에 처리할 수 있다.
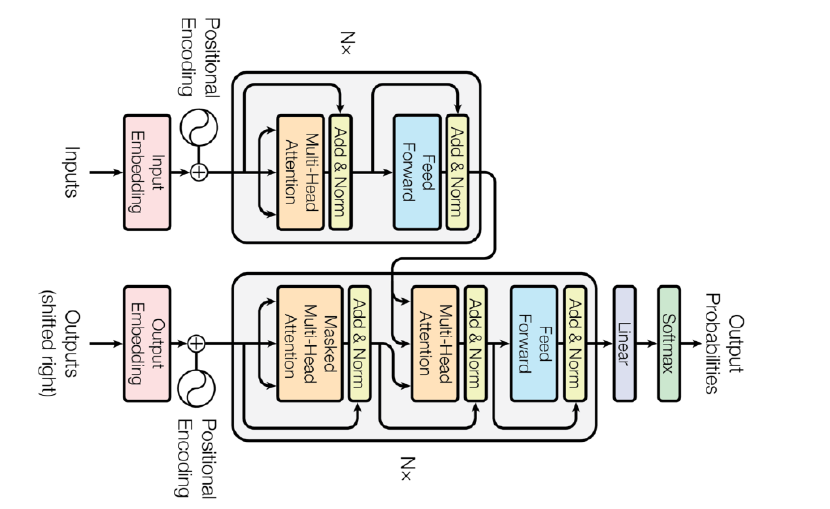
Trnasformer는 encoder와 decoder 구조로 되어있고, 동일한 구조를 갖지만 network paramter가 다르게 학습되는 encoder와 decoder가 stack되어 있는 형태이다.
여기서 중요하게 다뤄 볼 3가지 사항이 있다.
1. n개의 단어가 어떻게 encoder에서 한 번에 처리되는지에 대한 이해
2. encoder-decoder, decoder-encoder 사이에 어떤 정보를 주고받는지
3. decoder가 어떻게 generation 할 수 있는지(다른 두 가지 대비 이부분은 조금 덜 다룰 예정이기에 따로 찾아보자..)
1. encoder에서 어떻게 n개의 단어를 한 번에 처리할까?
하나의 encoder는 self-attention과 FFNN으로 되어 있으며, 거기서 나오는 n개의 출력값이 다시 두 번쨰 encoder의 input이 되며, 이게 반복되며 stack이 된다.
- The Self-Attention in both encoder and decoder is the cornerstone of Transformer.
결과적으로, FFNN은 일반적인 구조이므로, self-attention가 Transformer의 근간이 된다.
특정 nmt 문제를 푼다고 했을 가정했을 때, 3개의 단어가 있다면?
- First, we represent each word with some embedding vectors.
기계가 번역을 해야 하기에, 주어진 단어를 embedding vector로 변환한다. 즉, 현재 3개의 단어에 대한 vectors가 있다.

이 때, Transformer의 self-attention은 어떤 역할을 수행할까?
- Then, Trnasformer encodes each word to feature vectors with Self-Attention
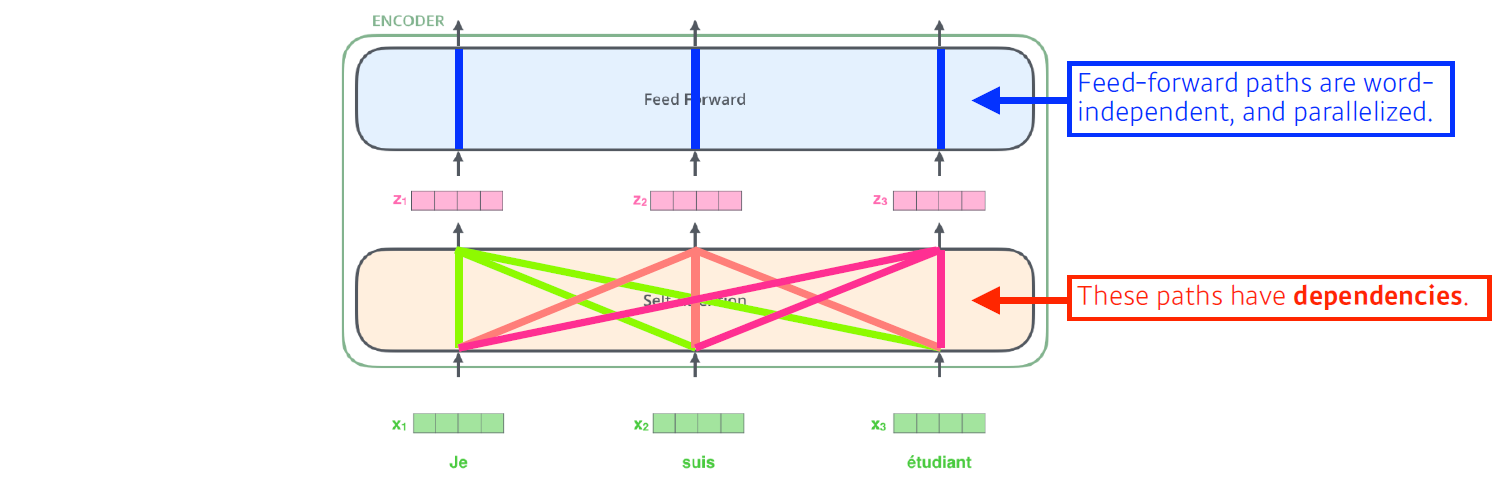
n개의 단어에 대한 vectors가 주어지면 각 단어별로 feature vector를 찾아주는데, 가 로 넘어갈 때 자신뿐만 나머지 개의 vectors들도 같이 고려한다. (이게 바로 self attention.. 두두등장..)
따라서 self-attention은 나머지를 고려하기에 dependent하다.
반면, self-attention으로 출력된 vectors가 개별적으로 동일한 FFNN을 통해 변환되어 출력되므로 FFNN은 independent하다.
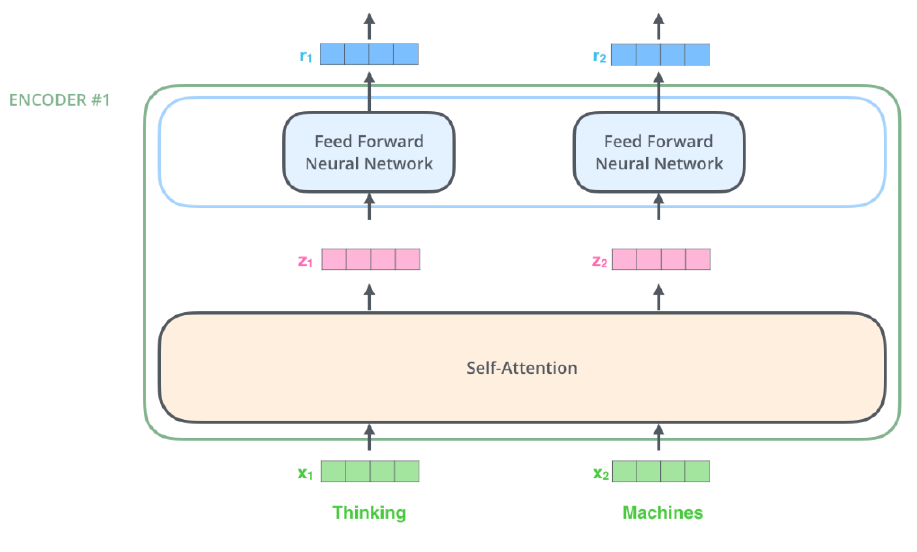
- Suppose we are encoding two words:
- Thinking and Machines
조금 더 단순화하여 두 개의 단어가(Thinking and Machines) 있을 때, 이 단어들이 각각 vector로 표현되었다고 가정해보자.
- self-Attention at a high level
self-Attention이 정확히 어떤 역할을 해주는 것인지에 대해 얘기해보면,
우선 아래 영어로 된 문장이 있다고 가정해보자.
이 문장을 이해하기 위해 중요한 점은 "it"이 어떤 단어에 dependent한 지 알아야 한다. 즉, 문장에 쓰인 단어를 설명할 때 단어를 그 자체로만 이해하는 게 아니라, 문장에서 다른 단어들과 어떤 interaction이 있는지를 알아야 한다.
해석해보면, it은 animal을 가리키는데, 여기서 transformer는 "it"이라는 단어를 encoding 시 다른 단어들과의 관계들을 보게 된다. 아래 it이 학습된 결과를 보면 animal과 관계가 있다고 학습된 것을 볼 수 있다. 그 결과, 더 잘 단어를 표현할 수 있고 기계가 단어를 더 잘 이해할 수 있게 된다.

다시 돌아와서, 두 개의 단어(Thinking and Machines)를 보자
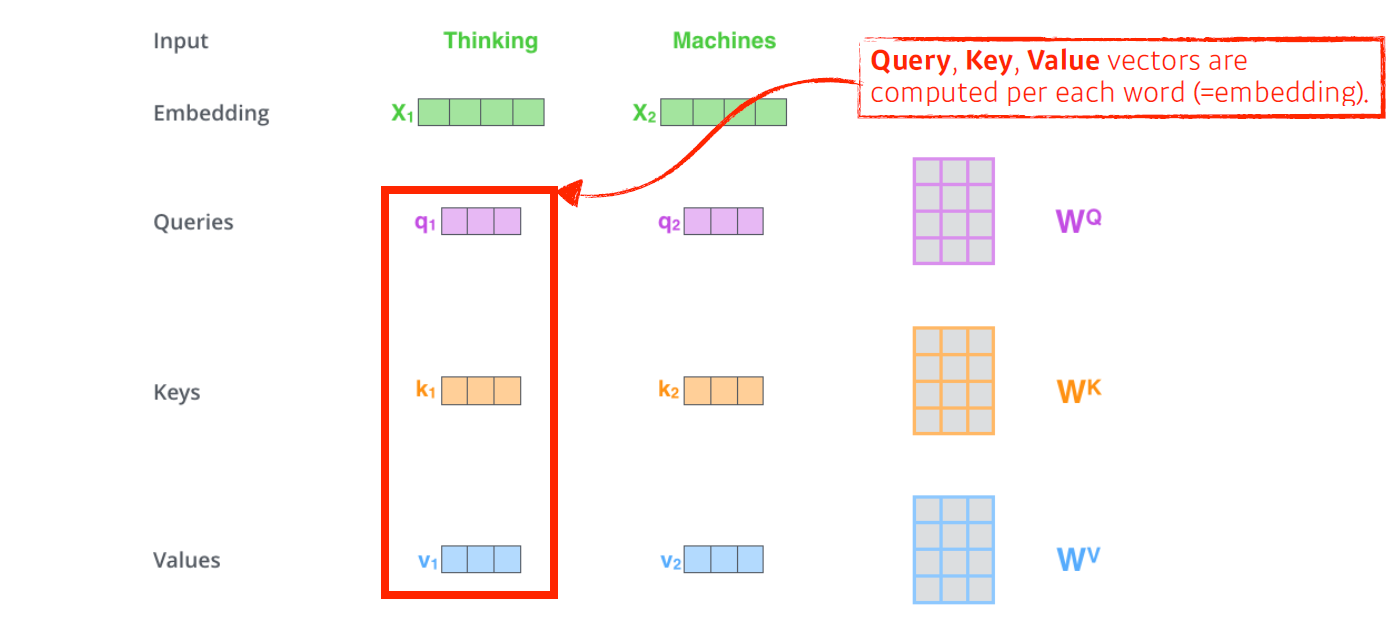
기본적으로 self-attention 구조는 vector 3개를 생성한다. vector 3개를 만드는 건 NeuralNet이 3개 있다고 보면 이해하기 쉽다.
각 vector는 query vector, key vector, value vector로, 번째 단어 vector 마다 vector가 생성된다.
이 세 개의 vector를 통해 단어에 대한 embedding vector를 새로운 vector로 바꿔준다.
- Suppose we are encoding the first word:"Thinking" given "Thinking" and "Machine".
여기서, 주어진 두 개의 단어 중 첫 번째 단어 Thinking을 encoding하고 싶을 때
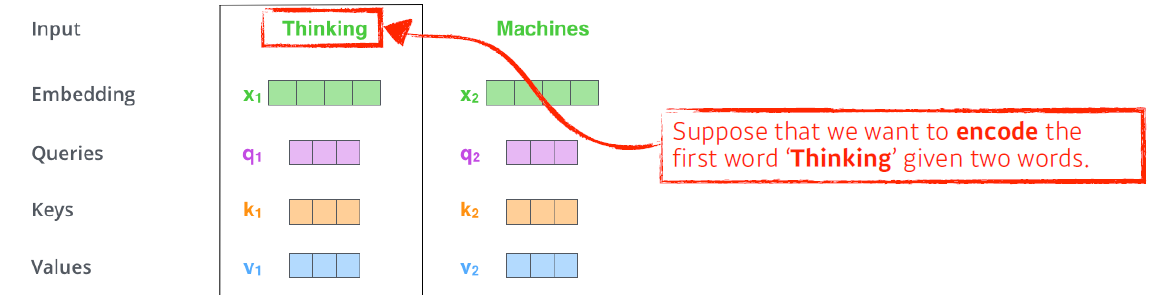
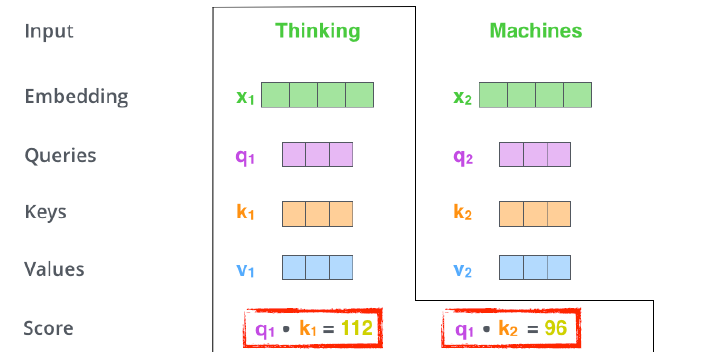
각각의 단어마다 생성한 query vector, key vector, value vector을 가지고, 우선 score를 생성한다.
score 계산할 때, encoding을 하고자 하는 단어의 query vector와 자기 자신을 포함한 나머지 n개의 key vector를 내적하여, 두 단어가 얼마나 algin되어 있는지, 얼마나 유사한 지를 구한다.
즉, i 번째 단어와 나머지 n개의 단어들 사이에 얼마나 interact해야 하는지에 대해 알아서 학습하게 하는데, 이것을 query vector와 나머지 key vector 사이 내적으로 표현한 것이다.
즉, 이게 바로 attention으로, 특정 task를 수행할 떄 특정 time step에 어떤 input들을 더 주의깊게 본다.
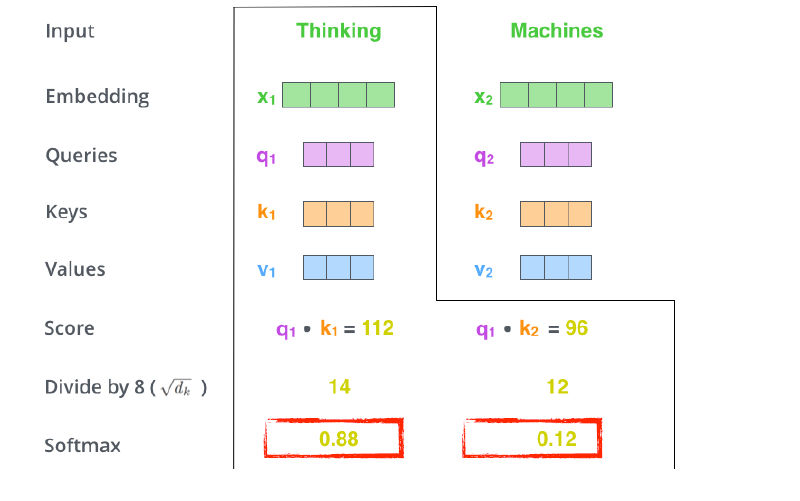
- Then, we compute the attention weights by scaling followed by softmax.
이렇게 구한 score를 normalize를 해주는데, 그 떄의 값은 key vector의 dimension(하이퍼 파라미터)이며, 예제에서는 64-dimension의 벡터로 만들어서 결과인 8로 나눠줬다.
이후 normalize score가 합계 1이 되도록 softmax를 취해준다.
아래 결과를 보면, Thinking이란 단어는 자기 자신과의 interaction은 0.88이고, Machines과의 interaction은 0.12인 attention weight를 구한 것을 볼 수 있다.
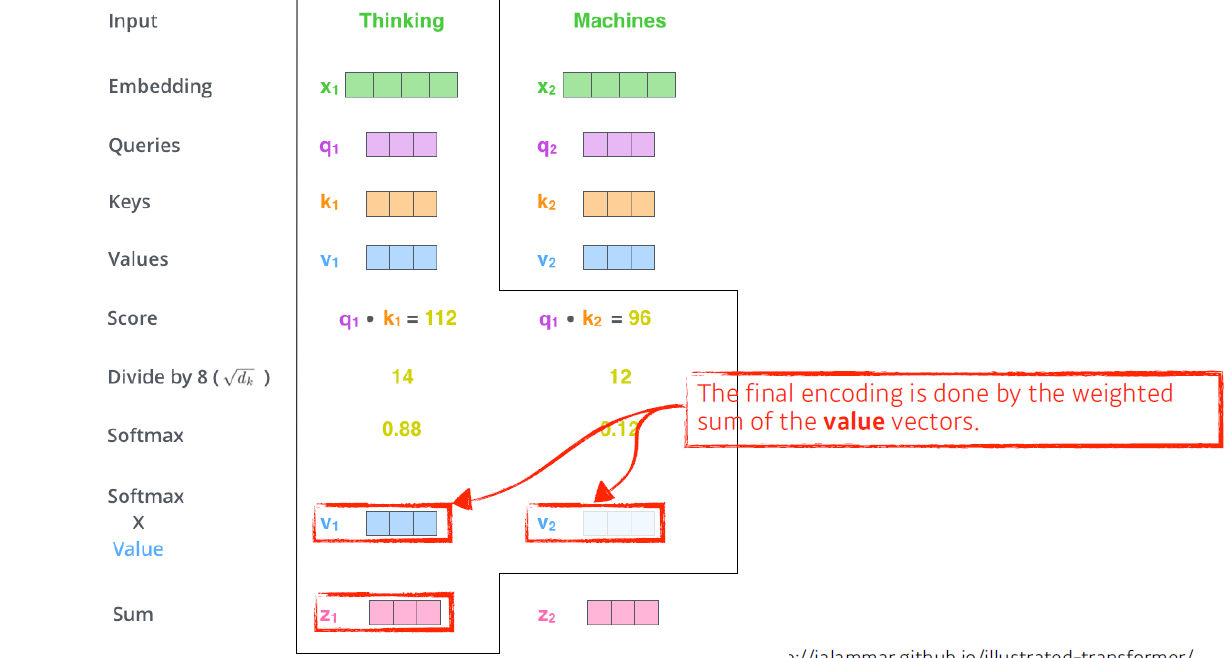
여기서, attention weight 각 단어가 자기자신을 포함한 나머지 단어와 얼마나 interaction해야 하는지에 대한 scalar 값이고
최종적으로 출력되는 envoding vector는 embedding으로부터 나오는 각 단어 embedding vector와의 weighted sum이다.
이 과정에서 중요한 점은,
query vector와 key vector는 내적해야 하므로 차원수가 같아야 한다.
반면, value vector는 weight sum만 하면 되므로 달라도 된다.
또한, encoding vector의 차원은 value vector와 동일하다.(단, multi head attention이란 것에선 다르다..)
이를 행렬로 표현한다면..
x가 2x4면 단어가 2개이며, 각 단어의 ebedding vector는 4-차원이다.
그리고 query, key, value 총 3개의 weight matrix를 찾는 각각의 MLP가 있다. 이 MLP는 encoding된 단어마다 share하며 MLP를 통과 시 각 단어의 query vector, key vector, value vector가 출력된다.
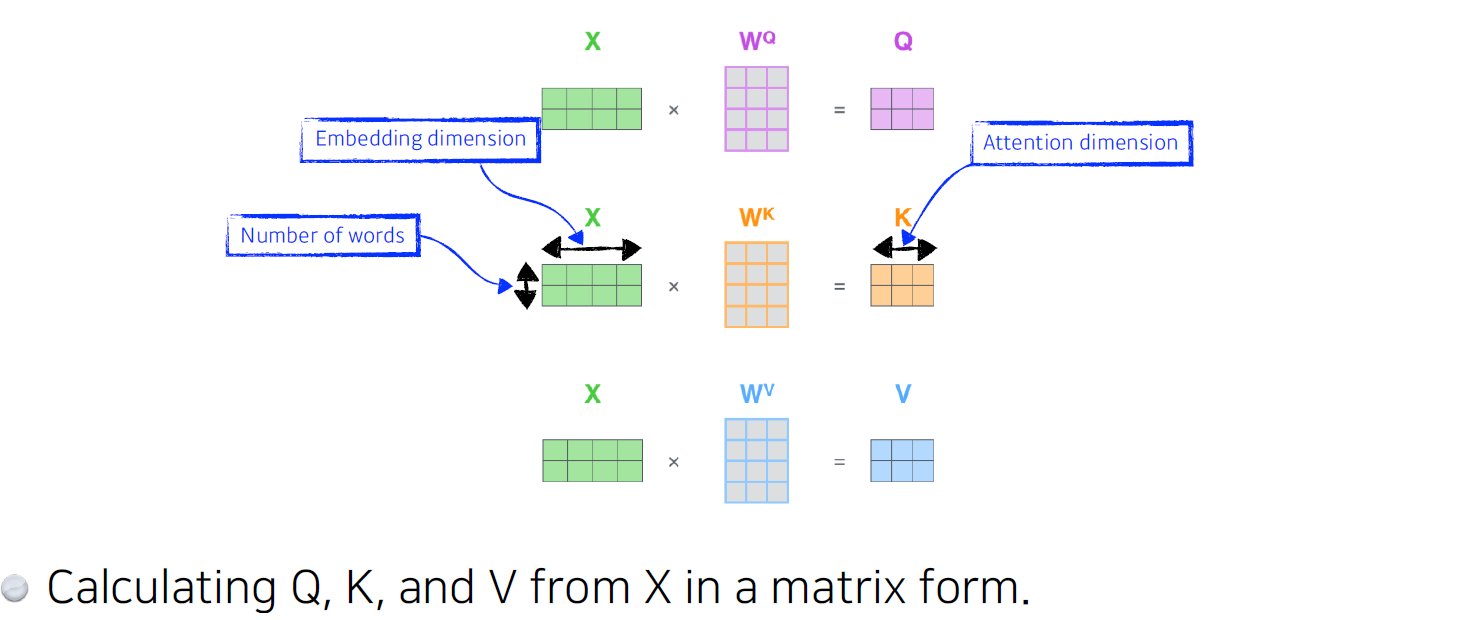
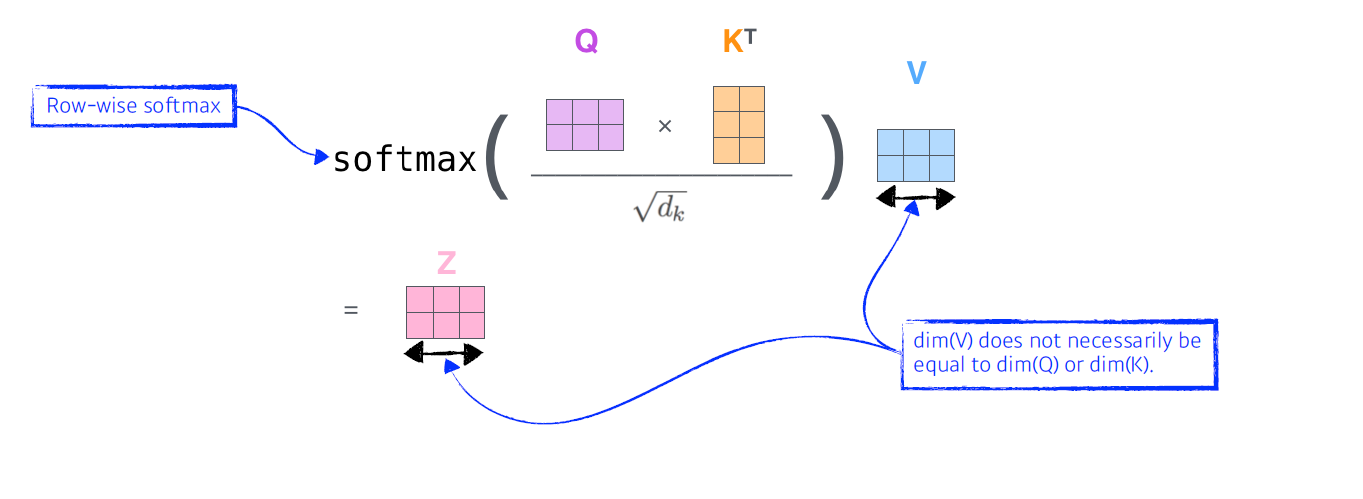
그 다음으론
query vector와 key vector를 내적 후, key vector의 dimension에 square root를 취한 값을 나눠준 후, softmax를 통해 weight를 sum to 1으로 만든 각 attention weight을 각 value vector에 곱한 다음 성분합을 취하여 encoding vector를 출력한다.
그렇다면 좀 더 high level에서 바라볼 때 왜 transformer가 잘 될까?
image 하나가 주어졌을 때 cnn이나 mlp로 dimension을 바꾸면 kernel이나 weight가 고정되어 있기에 출력이 고정된다.
반면, transformer는 하나의 input이 고정되어 있다 하더라도, 인코딩 하려는 단어와 주변 단어들에 따라 인코딩 값이 달라서 출력이 달라질 여지가 있다.
따라서 mlp나 cnn 모델보다 조금 더 flexible하여 보다 많은 것을 표현할 수 있는게 transformer 구조이며, 바꿔 말하면 더 많은 표현을 위한 computation이 필요하다.
단, transformer의 한계를 보면, 만약 1만 개의 단어가 있을 때, RNN은 시간이 오래 걸릴지라도 1만 번을 수행하면 되지만, transformer는 한 번에 1만 개의 단어를 처리하는데, 이때 computational cost가 이다. 따라서 length가 길어짐에 따라 처리의 한계가 있다.
하지만 flexible하고 훨씬 더 많은 것을 표현할 수 있기에 transformer를 사용한다.
- Multi-headed attention (MHA) allows Transformer to focus on different positions[MHA 자세한 설명 + 장점]
단, 한 input 단어에 하나의 Q,K,V embedding vector를 만드는게 아니라 입력 단어 개수(n) 만큼 Q,K,V embedding vector를 생성하여 MHA가 되는것이며

- If eight headed ard used, we end up getting eight different sets of encoded vectors(attention heads)
이 벡터들을 통해 n 번의 encoding을 반복하면 n개의 encoding vector를 얻을수 있게 된다.
단, encoding된 vector는 다음 encoder로 넘어가야 하므로, 입력과 출력의 차원은 맞춰줘야 한다.
그렇다면 n 개의 encoded vector가 있는데 이것을 어떻게 다음 과정으로 넘길 수 있을까?
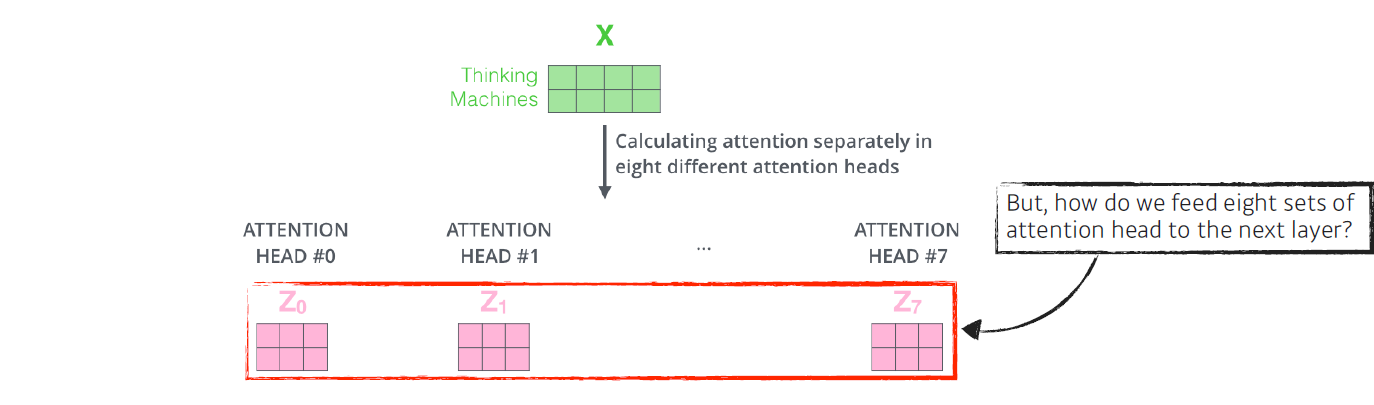
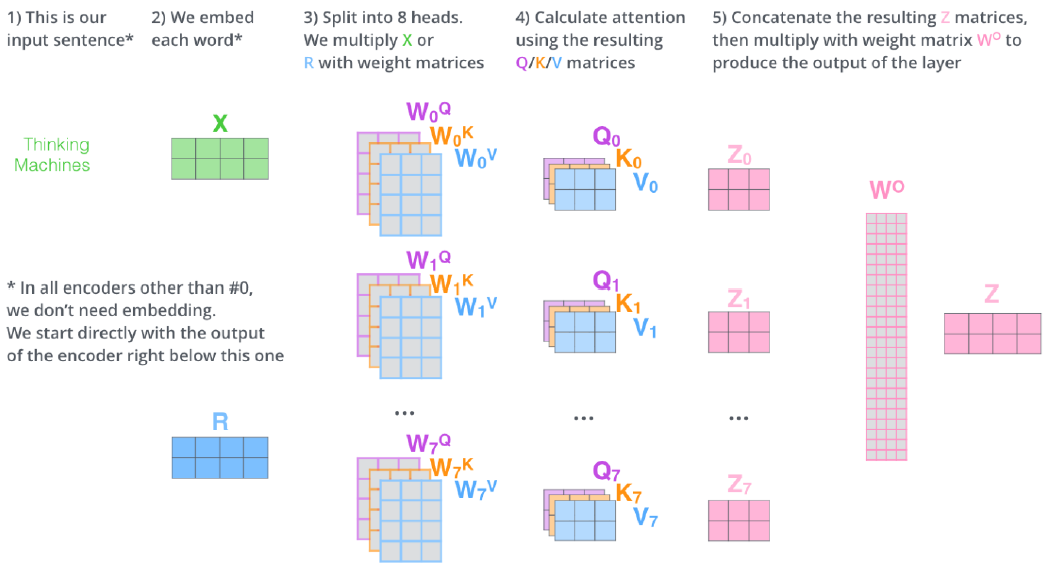
- We simply pass them through additional (earnable) liear map
- concatenate all attention heads
- Multiply with a weight matrix that was trained joinly with the model
- The result would be the matrix that captures information from all the attention heads. We can send this forward to the FFNN
간단하게, 우선 모든 encoded vector를 concat 후 weight maxrix와 내적을 하여 초기 embedding vector의 dimension을 가진 vector로 변환해준다.

결과적으로 아래 과정이 self-attention의 일련의 과정을 설명했는데, 실메 MHA 구현체를 보면 이렇게 구현되지 않는다.
실제 구현을 할 때, 예를 들어 10개의 단어에 대해 출력된 embedding vector가 100 dimension이라고 가정을 하면,
단어 개수와 맞게 10개의 head를 사용하므로 embedding vector의 차원을 10으로 나눠서(100 / 10) input으로 넣는다.
즉, 실제 100 차원의 embedding vector의 10 dimension만 가지고 각 attention을 수행한다!!
자 그러면, 이제 입력에 Positional encoding을 값을 더해주는 과정이 추가된다.(bias를 더해주는 것 처럼)
- why do we need positional encoding?
갑자기 추가하라고 하니 "? 왜? ¿¿??¿?¿? 라는 의문이 들 수 있다.
그 이유는, n개의 단어에 대해 sequential하게 입력으로 넣었다고 치지만, 실제 self-attention 과정에서는 각 단어의 관계만을 보고 그것을 고려한 새로운 vector 값을 출력했다는 것을 알 수 있다.
다시 생각해보면 A B C D E 라는 단어가 있을 때 각 단어의 자리를 바꿔서 입력으로 넣었다고 생각해보자. 이때 각 단어별 score를 계산한 게 달라질까? 전혀!?
따라서 위에 얘기 했던 것 처럼, 입력에 posititonal encoding을 더해주는데 마지 bias 값을 더해주는 것과 같다.
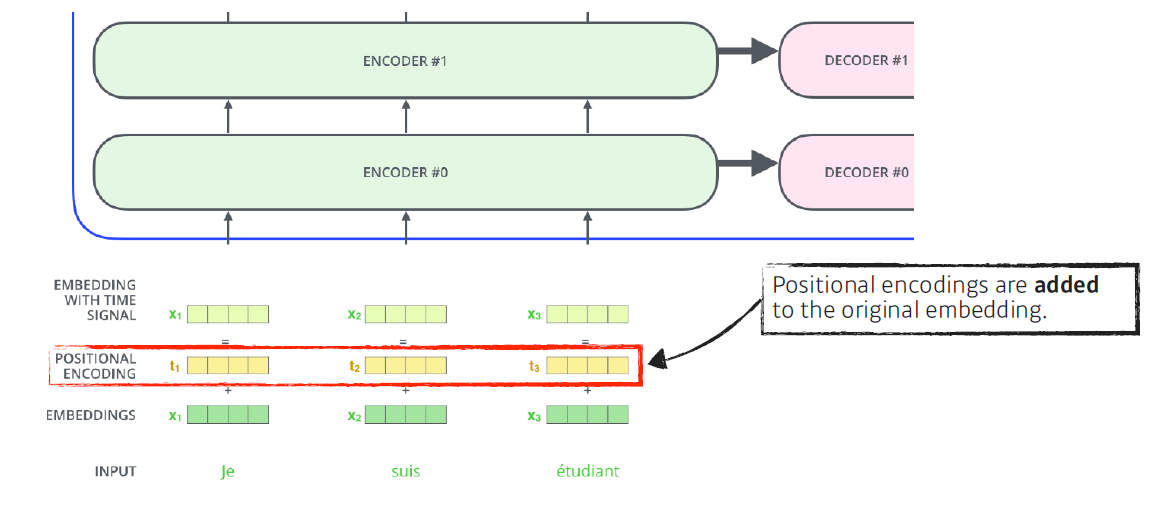
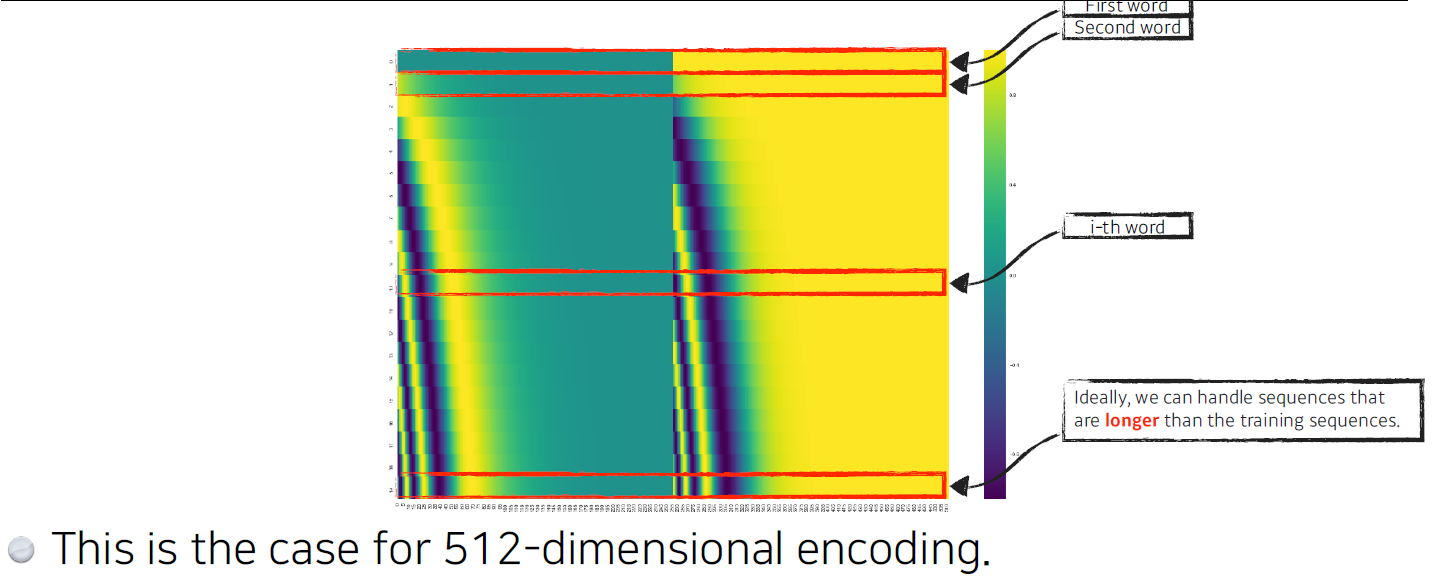
- This is the case for 4-dimensional encoding.
embedding vector가 4차원이라고 가정할 경우, 특정 방법으로 만들어진 positioning encoding도 다음과 같이 4차원이다.
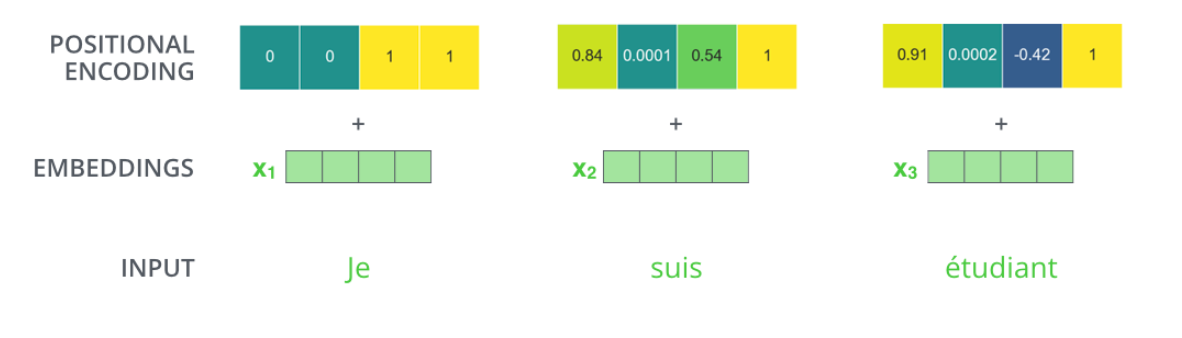
따라서, 다음과 같이 각 단어 순서마다 다음 ebedding 순서별로 값을 더해주며
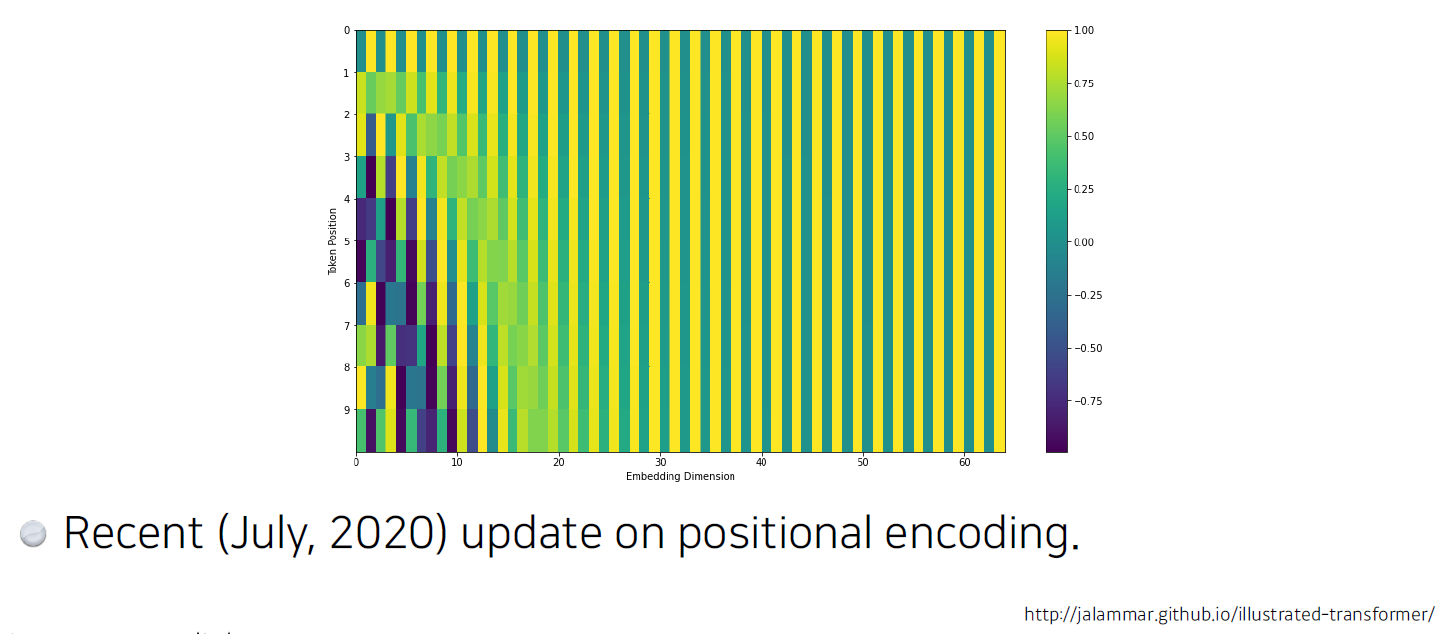
2020년 아래 블로그에선 다음과 같이 positional encoding이 바뀌었다고 한다.
(관심이 있으면 찾아서 들어가보자.. [링크][링크2] << 클릭!
그리고 이렇게 나온 encoded vector Z는 Layer Normalization(이 부분도 찾아보자..!!)을 하고

결론적으로 이런 과정을 거쳐 decoder로 들어간다.
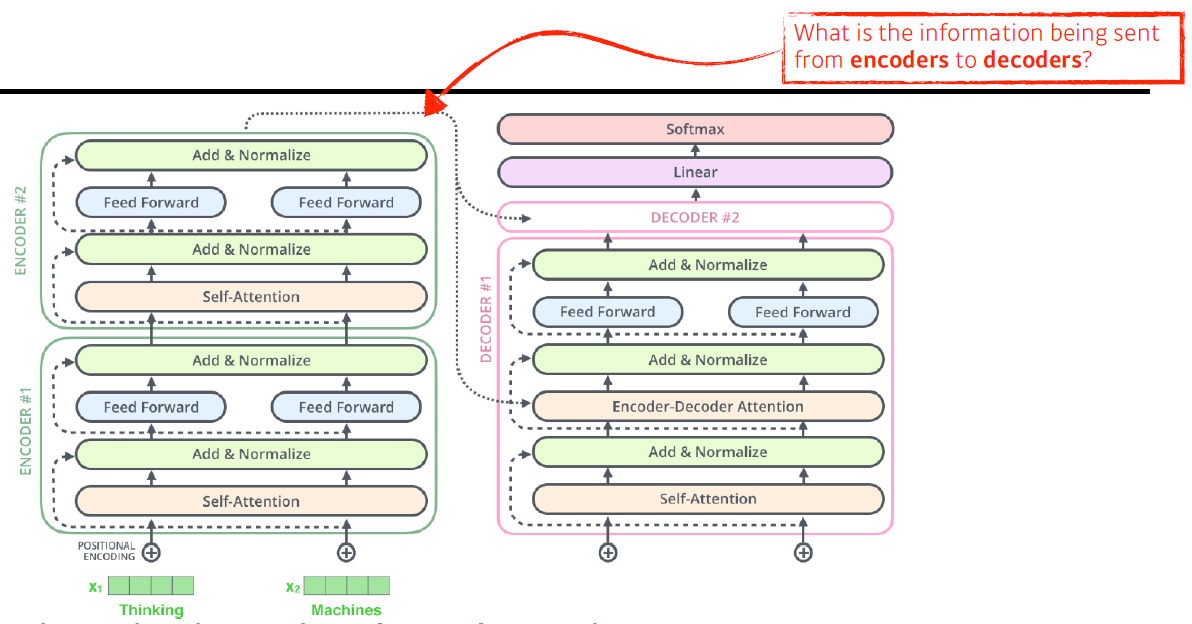
- Transformer transfers key(K) and value(V) of the topmost encoder to the decoder.
가장 상위 encoder의 출력은 key vector와 value vector로 바뀌며 이 값들이 decoder로 보내는진다. 왜 그럴까?
i 번째 단어를 만들기 위해선, i 번째 query vector와 나머지 단어와 key vector를 내적 후 value vector를 weight sum을 하는데, input에 있는 단어들을 decoder에서 출력하려는 단어들에 대해 attention map을 만들려면 해당 벡터들이 필요하다.
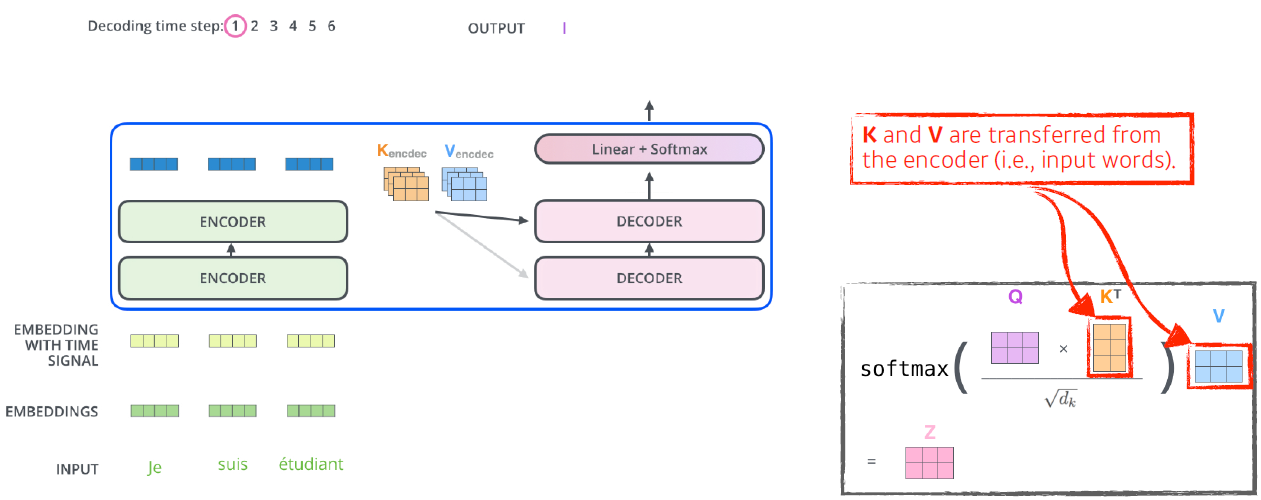
- The output sequence is generated in an autoregressive manner.
이후, decoder에 들어가는 단어 벡터들로 만들어진 query vector와 encoder에서 나온 key, value vector를 통해 최종 값 출력이 출력되며,
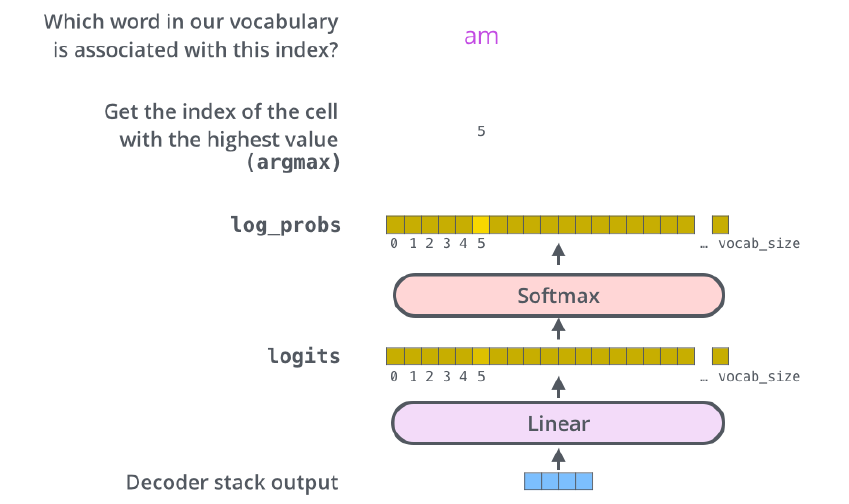
decoder의 각 time-step에는 decoder의 직전 output을 input으로 받아 Decoder stacks를 거쳐 linear + softmax 후 다시 output을 내뱉는 과정을 거치며 <end of sentence>라는 스페셜 토큰이 출력되면 과정이 종료된다.
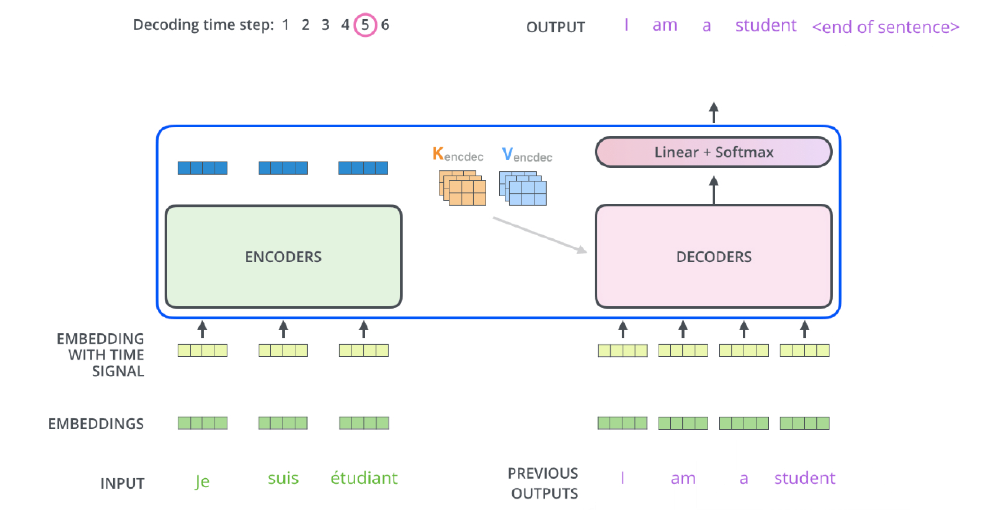
- In the decoder, the self-attention is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before softmax step.
단, 학습 단계에서 입력과 출력 정답을 알고 있는데 i 번째 단어를 만드는데 모든 문장을 있기에 학습하는 의미가 없어서 학습을 위해 masking을 한다.
masking이란 이전 단어들에 대해 dependent하고 이후 단어들에 대해선 indendent하게 만드는 방법이다.
inference 할 때도 masking한 것을 넣는다.
즉 학습이든 추론이든 현재 시점에서 미래 정보를 활용하지 않겠다는 의미!!

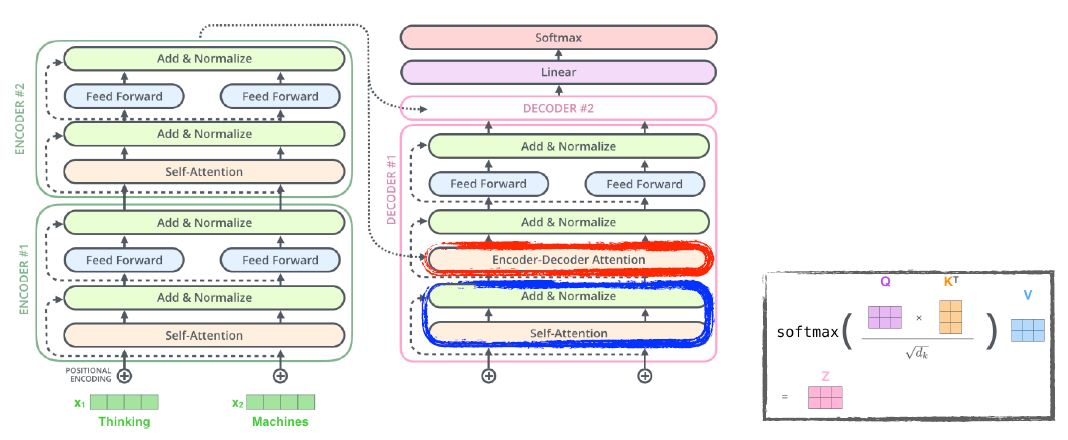
- The "Encoder-Decoder Attention" layer works just like multi-headed self-attention, except it creates its queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
decoder에선 이전에 generation된 단어들로 query를 만들고 encoder로 나온 key & value vector를 활요한다.
- The final layer converts the stack of decoder outputs to the distribution over words.
최종단에선 단어들의 분포를 만들고, 그 중에서 단어를 sampling 하는 식으로 된다.
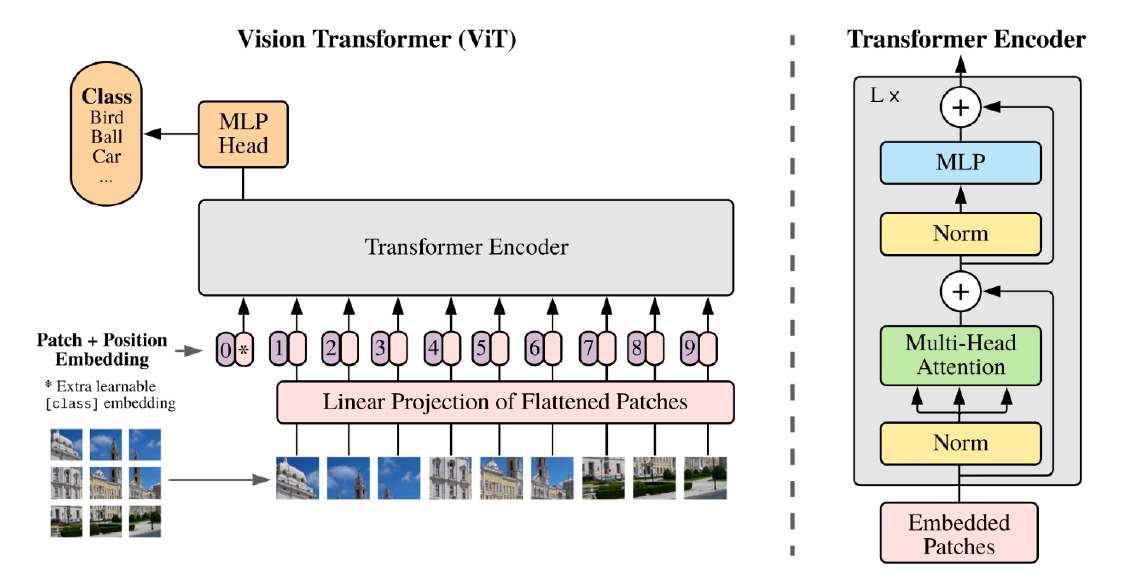
초기 transformer는 nmt, 즉, 번역 문제에만 활용되었는데
최근엔 seq-to-seq만 하는게 아니라 image문제를 다루는데에도 사용된다.
또한 DALL-E라는 network도 있는데, 문장이 주어지면 문장에 대한 이미지를 생성해낸다!
https://openai.com/blog/dall-e/

