본 포스팅에서는 RoBERTa : A Robustly Optimized BERT Pretraing Model에 대해 소개해드리겠습니다. RoBERTa의 경우 BERT의 후속 모델로 유명합니다.
📌 BERT란?
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 2018년 구글에서 발표한 언어모델중 한 개 입니다. BERT는 여러가지 자연어 task중 최고 성능을 기록하면서 모델이 처음 발표되었을때부터 지금까지 자연어처리분야에서 큰 화제를 불러왔던 모델입니다. 그리고 RoBERTa는 이러한 BERT의 몇가지 한계점에 대해 개선한 모델중 하나 입니다.
📌 RoBERTa에 대해서
RoBERTa의 경우 기존의 BERT가 underfitting되어있음일 지적하면서 등장한 모델입니다. 즉, underfitting의 문제점등을 해결하면서 성능을 좀더 끌어올릴수 있다고 주장한 논문입니다. 성능을 끌어 올리기위해 본 논문에서는 3가지 방법을 제시하였습니다.
첫번째로 dynamic masking 방법을 사용합니다. 두번째로는 더 많은 데이터와 더큰 batch 사이즈를 사용하였습니다. 마지막으로는 기존의 BERT학습에 사용되었던 NSP(Next Sentence Prediction)을 제거 하였습니다.
Dynamic masking
BERT는 학습을 위해 2가지의 task를 수행합니다 첫번째로는 Masked languaged model이라 불리는 MLM task이며, 두번째는 NSP task 입니다.
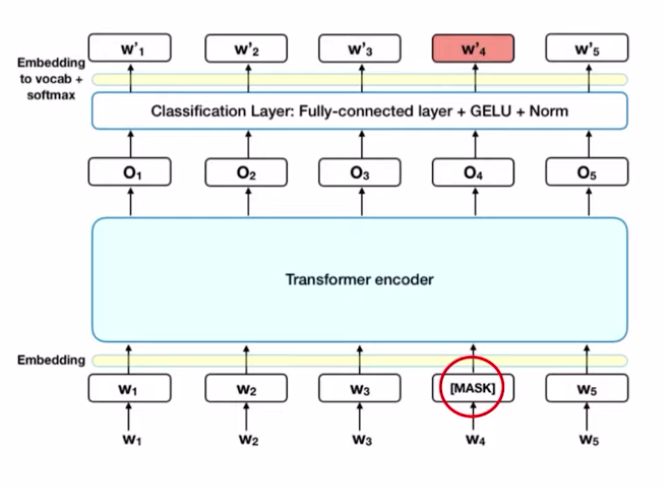
MLM task는 BERT 모델이 입력이 들어올때, 그중 일부를 mask 처리합니다. 즉 가려진 token에 대해 맞추는 task라고 할 수 있습니다. 따라서 BERT는 가려진 token을 예측하기위해 문맥정보를 최대한 활용하는 방향으로 학습이 수행됩니다. 이때 기존의 BERT는 masking하는 토큰을 static하게 선정하는 반면, RoBERTa의 경우 토큰을 dynamic한 방법을 사용하여 masking 합니다.
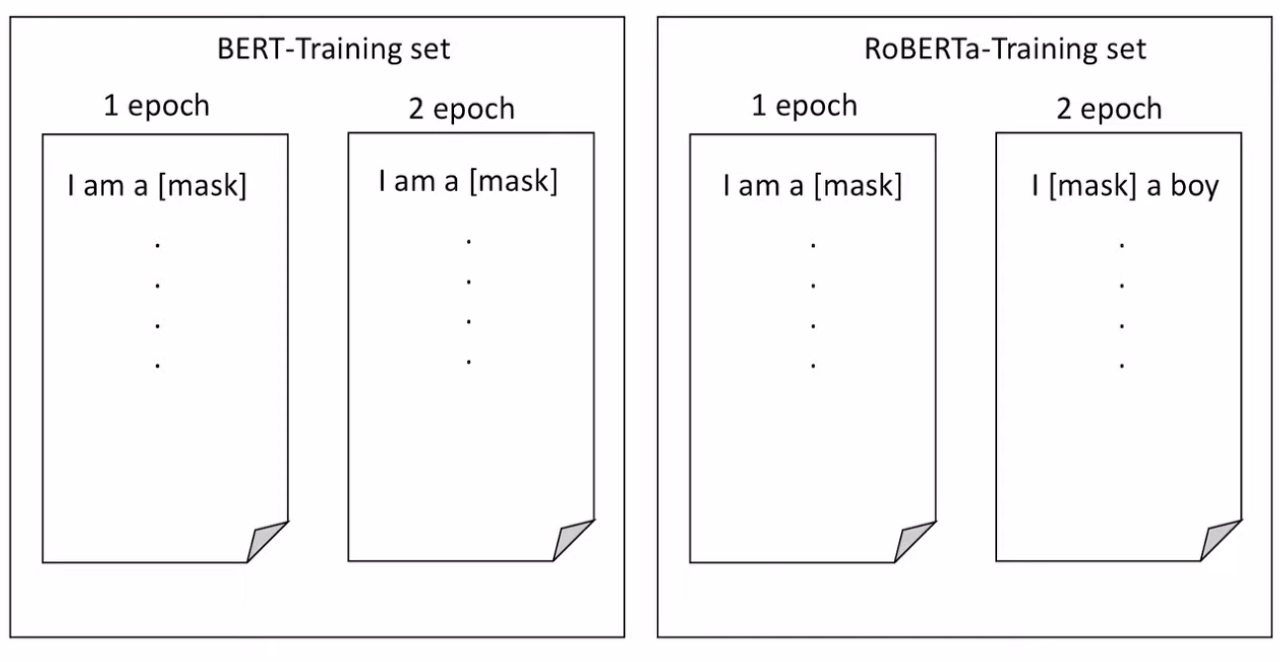
위의 그림은 BERT에서 사용된 static 방법과 RoBERTa에서 사용된 dynamic한 방법에 대한 그림입니다.
먼저 왼쪽그림은 기존 BERT에서 사용된 static한 방식인데, 예를 들어 'I am a boy'라는 문장이 주어졌을 때, BERT는 전처리 단계에서 일부 토큰을 masking하여 모델의 입력값으로 넣습니다.
즉, 입력값이 모델에 들어갈때 부터 가려진 토큰이 결정되므로 왼쪽 그림에서 확인 할 수 있듯이 epoch에 관계없이 같은 입력에 대해서 항상 동일한 위치에 토큰이 가려지게 됩니다.
반면 RoBERTa의 경우 dynamic한 masking 방식으로 마스킹 처리하게되는데, 따라서 매 epoch마다 다른 토큰이 마스킹 되게 됩니다. 이를 통해 오버피팅을 방지 할수 있음과 더불어 task의 난이도 상승으로 인해 학습후에 모델이 더 어려운 task에 대해서도 잘 해결 할 수 있게 학습을 수행합니다.
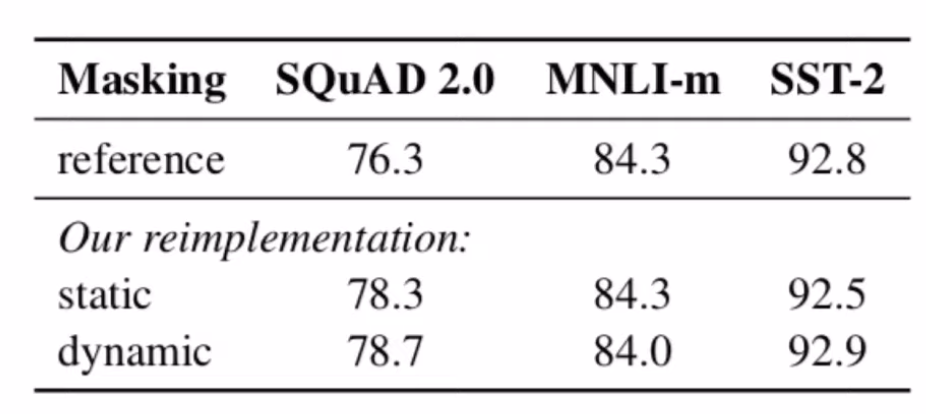
아래 지표에서 확인 할 수 있듯이, dynamic한 방식이 모든 task에 대해 높은 성능을 보인것은 아니지만, SQuAD와 SST와 같은 task에서 저자들의 컨트리뷰션이 유효했음을 알수 있습니다.
More datasets and Batch size
RoBERTa는 모델의 성능 향상을 위해 더 많은 데이터와 더 큰 배치사이즈를 사용하였습니다.
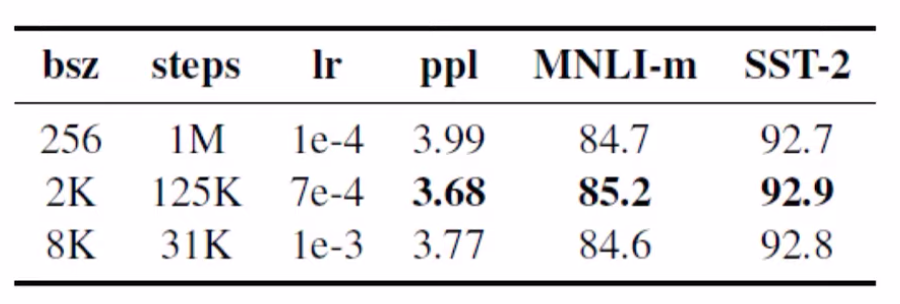
위의 지표를 보면 batch 사이즈를 높인다고해서 무조건 모델의 성능이 향상되는것은 아니지만, 이전 BERT 모델과 비교해서 더 큰 batch 사이즈를 사용하였을때, 모델의 성능이 높아지는것을 확인할수 있습니다.
Next Sentence Prediction
RoBERTa는 모델의 성능을 높이기위해 Next Sentence Prediction(NSP)을 제거하였습니다.

NSP는 위에서 설명드렸던 것과 같이 BERT의 학습에 이용되는 task 중 하나로써, NSP는 입력값으로 들어간 두 문장이 이어지는 문장인지, 아니면 관계없는 문장인지를 예측하는 이진분류(binary classification) task 입니다.
즉, 두 문장의 일관성에 대해 학습하는것으로도 볼 수 있습니다. NSP는 처음 BERT가 등장한 이후로 자연어처리 분야에서는 꾸준히 의문이 제기되어왔는데, 예를들어 XLNet의 경우 RoBERTa와 같이 NSP를 제거하여 Pre-training하는 방법을 제안하였습니다. 아래 지표의 경우 NSP를 제거하였을 때와 제거하지 않았을때의 각 데이터셋에 대한 성능을 나타내었습니다.
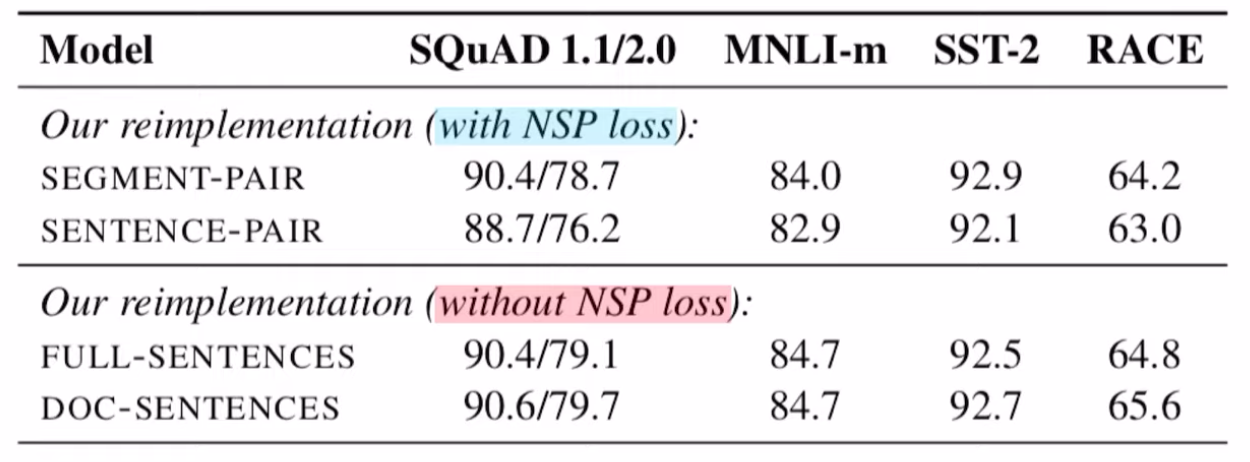
지표를 살펴보면 NSP를 제거하였을때의 성능이 NSP를 사용하였을때의 성능보다 높은것을 확인 할 수 있습니다. 하지만, BERT논문의 경우 NSP를 사용하였을 떄 성능이 높아진것을 보여준 결과, NSP의 경우 모델의 성능을 사용하는 사용자가 각자의 task에 맞게 NSP를 조절해서 사용하는게 맞다고 생각이 듭니다.
📌 결과
RoBERTa의 경우 BERT 모델의 성능을 끌어 올리기위해 첫번째로 dynamic masking 방법, 두번째로는 더 많은 데이터와 더큰 batch 사이즈를 사용, 그리고 마지막으로는 기존의 BERT학습에 사용되었던 NSP(Next Sentence Prediction)을 제거 하는 방식에 대해 제안하였습니다.
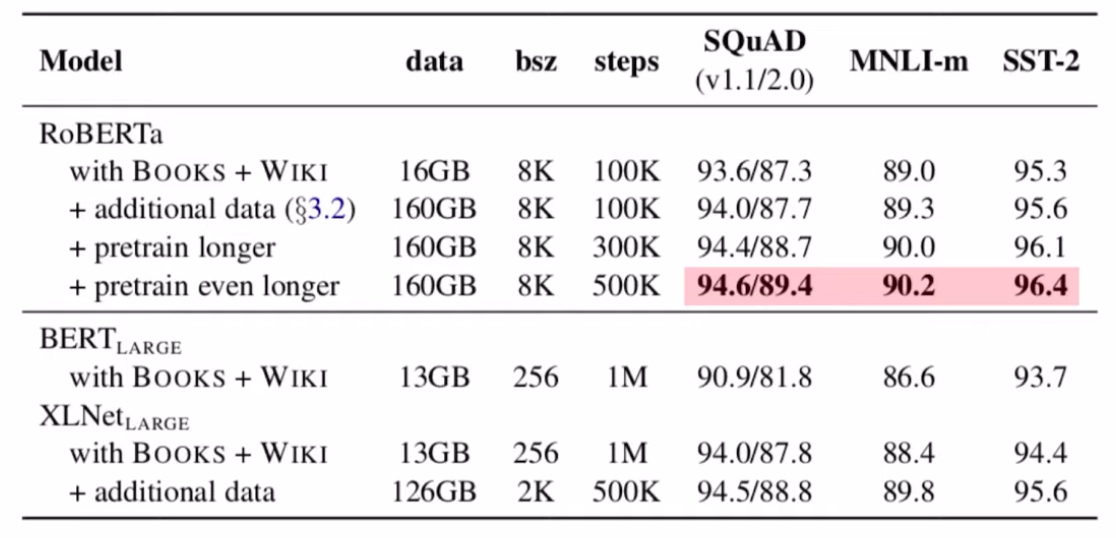
위의 결과에서 확인할수 있듯이 3가지 방법 모두 모델의 성능을 높이는데 유의미한 결과를 보여주었음을 확인 할 수 있습니다.
