본 포스팅에서는 reading comprehension task에 대해 새로운 모델을 제시한 QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension에 대해 진행해보도록하겠습니다.
📌 서론
본 논문이 나오기 이전의 QA모델의 경우 RNN과 Attention이 결합된 모델이 있었으며, 이는 학습과 추론에 오랜 시간이 걸린다는 단점이 있었습니다. 따라서 본 논문은 RNN 대신 convolution과 self-attention을 결합한 모델을 제시하였으며, 성능은 비슷하면서 SQuAD 데이터셋에서 성능은 유지하면서 학습속도는 3~13배 빠르고 추론이 4 ~ 9배 빠른 결과를 보여주었습니다. 본 논문에서 활용된 데이터셋은 위키피디아에서 모은 데이터셋으로 span-base 데이터셋이라는 특징을 가지고 있습니다. 또한 sigle model을 기준으로 해당 데이터셋에서 84.6 F1 스코어를 기록하였습니다.
📌 QA(Question Answering)가 뭘까?
QA는 질문이 주어졌을때 정답을 예측하는 테스크 입니다. 본 논문 이전의 QA모델은 아래의 그림과 같은 구조를 가지고 있습니다.
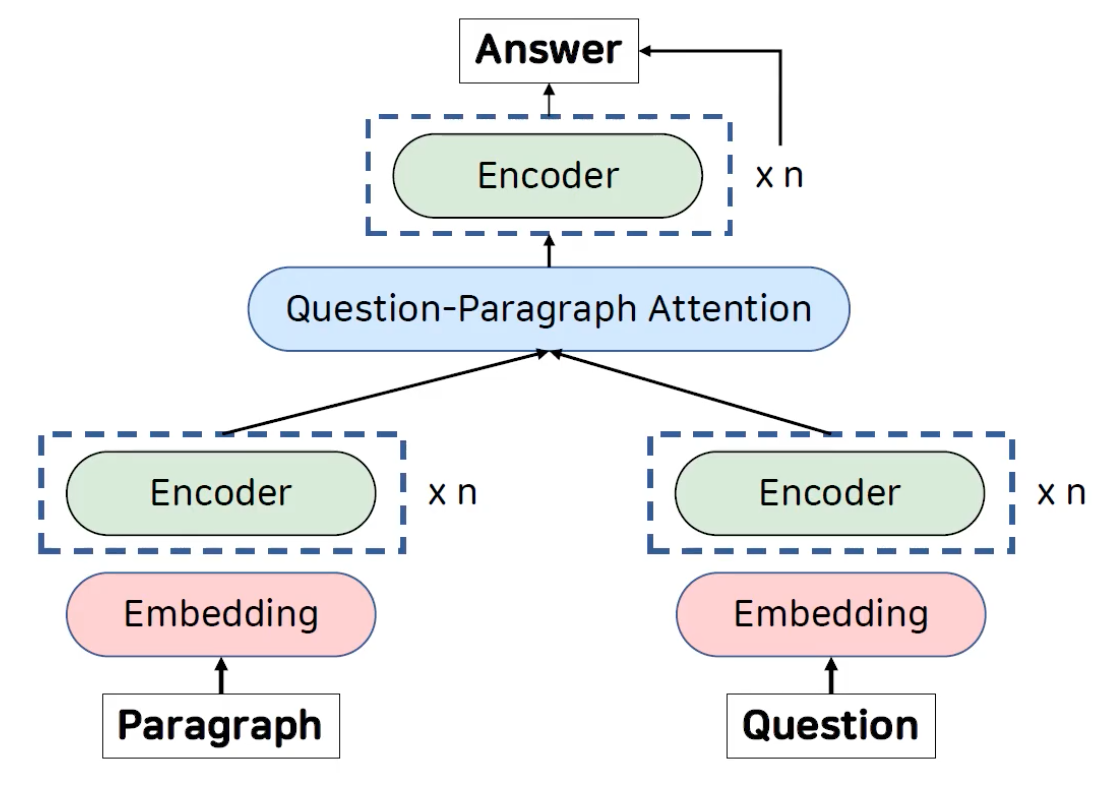
주어진 paragraph와 question을 임베딩하여 encoding하고 피쳐를 뽑아낸 이후 서로간의 attention을 계산합니다. 그리고 추가적인 인코더를 통과하여 정답을 예측하는 구조입니다. 여기서 인코더 레이어가 대부분 RNN으로 이루어져있는데, RNN의 경우 크게 2가지 문제가 존재합니다.
첫번째로 문단과 같은 긴 문맥을 처리하는 과정에서 시간이 지날 수록 앞의 정보가 점차 희미해지는 경향이 있습니다. 두번째로는 학습과 추론에 시간이 오래 걸린다는 단점이 있습니다. 학습의 경우 experimentation에 걸리는 시간이 오래걸려서 큰 데이터셋을 사용하는데 cost가 너무 많이 들며 추론의 경우 QA모델의 추론이 실시간 수준으로 빠르지 않기 때문에 실제 산업에 적용되는데 어렵다는 단점이 존재합니다. 따라서 본 논문에서는 QANet이라는 새로운 모델을 제시하였습니다.
📌 QANet이란?
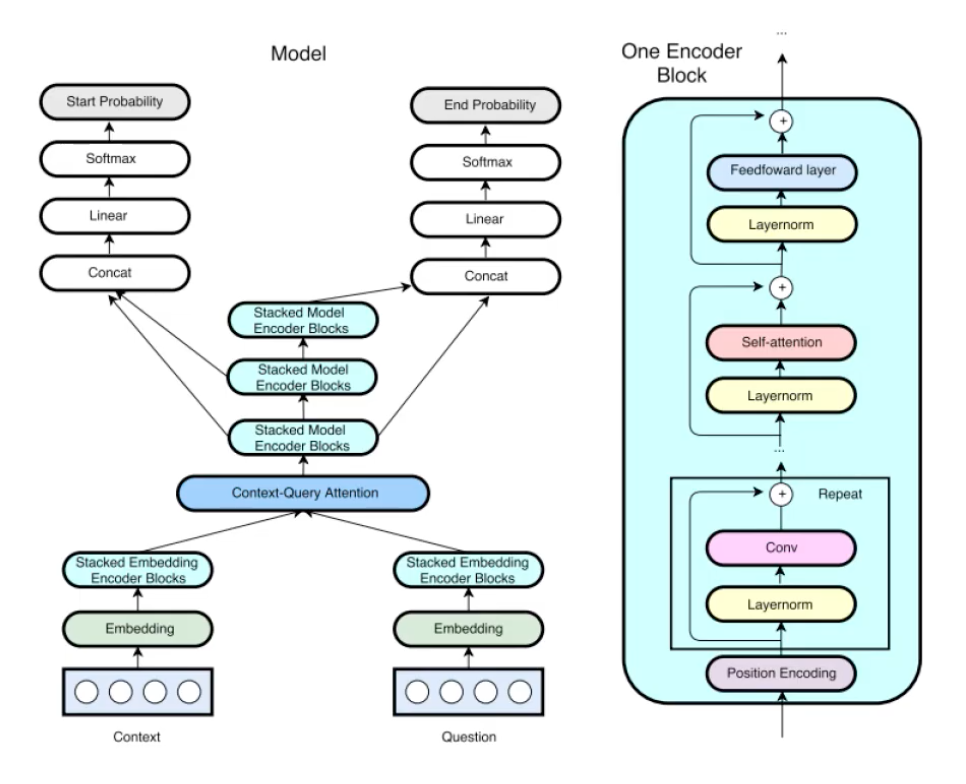
위의 사진은 QANet에 대한 전체적인 모델 구조입니다. Encoder block인 하늘색 부분이 RNN이 아닌 convolution과 self-attention을 사용하는 transformer block을 사용하였습니다. 해당 QANet의 모델 구조를 각 layer별로 살펴보면 다음과 같습니다.
Input Embedding Layer
해당 레이어는 처음 context와 question을 임베딩하는데 사용되는 레이어 입니다. Word embedding과 character embedding으로 이루어져 있으며, word embedding의 경우 pretraind GloVe를 사용하였습니다. Embedding layer에서 look-up한 후에는 2개의 highway network로 이루어진 convolution layer를 통과해서 아웃풋을 만들어냅니다.
Embedding Encoder Layer
해당 레이어는 기존의 모델과는 다르게 RNN을 사용하지 않았으며, convolution과 self-attention을 사용한 transformer모델을 사용하였습니다. Convolution은 depthwise separable convolution을 사용하였으며, self-attention의 multi-head attention을 적용하였습니다. 그리고 각 convolution, self-attention, feed-forward 부분 모두 layer normalization 및 residual block으로 이루어져있습니다.
Context-Query Attention Layer
해당 레이어는 context 피쳐와 query 피쳐간의 유사도를 계산하여 어텐션을 계산하는 레이어 입니다. 먼저 유사 행렬 S를 만들고 행으로 정교한것이 context의 어텐션이며 열로 정교한것이 query의 어텐션 입니다. Query to context 어텐션의 경우 context to query 어텐션과 식이 다른데 이는 좀더 좋은 성능을 보이는 tcm 모델의 쿼리 투 컨텍스트 계산 방식을 가져왔습니다
Model Encoder Layer
해당 레이어의 구조는 Embedding Encoder Layer와 동일하며, convolution layer의 갯수 및 block의 갯수의 차이만 존재합니다.
Output Layer
해당 레이어는 정답을 예측하기 위한 레이어이고, 어떠한 task에냐에 따라 다르게 구성될 가능성이 있습니다. 본논문의 QANet의 경우 span-based 데이터셋에 대한 예시를 들고있기 때문에, start-index와 end-index를 예측하는 부분으로 output layer가 2개로 나누어져있습니다.
Back Translation
Back Translation은 본 논문에서 추가 학습을 위해 사용되었으며, 구글에서 발표된 NMT모델(=번역모델)을 사용하여 하나의 데이터를 늘리는 데이터 agmentation 기법을 사용하였습니다.
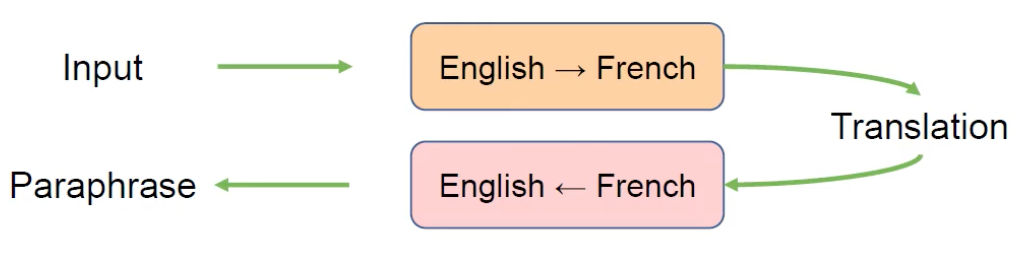
해당 기법은 위의 그림에서처럼 영어를 불어로 번역후 생성된 번역본을 다시 영어로 번역하는 방식입니다. 즉, 다시 번역한다는 의미를 담아서 back translation이라고도 부릅니다. 본 논문에서는 해당 방식을 사용하여 기존 데이터 대비 더 많은 학습을 진행하였으며, 기존 데이터 학습 성능보다 1.1 포인트의 F1 score 향상되었습니다.
📌 결과
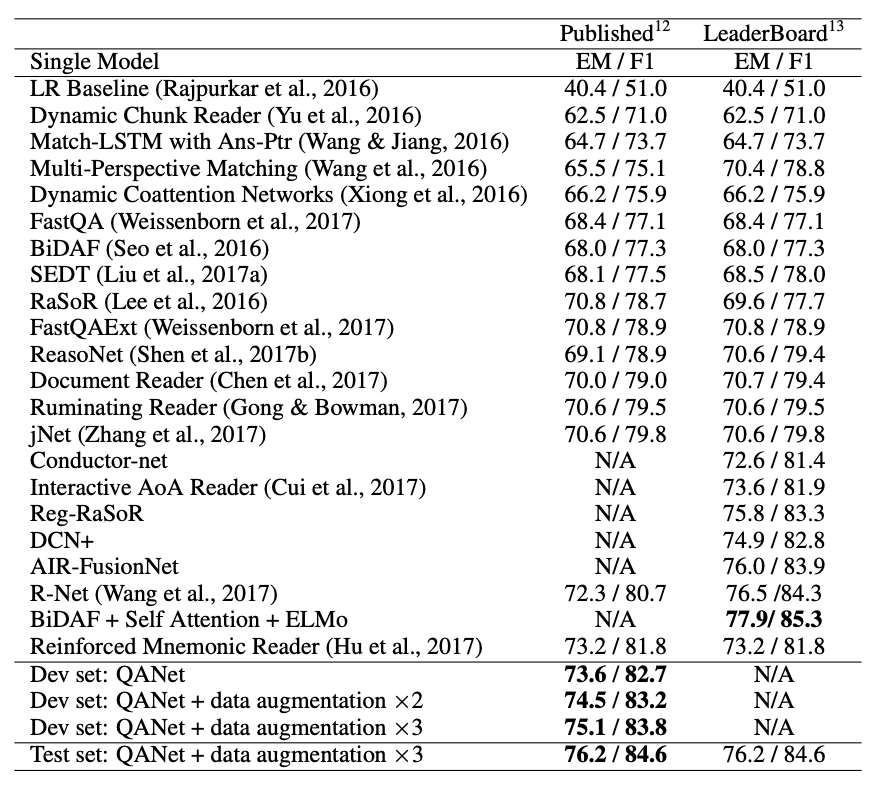
SQuAD 데이터셋의 공식 테스트셋에서 완전 일치를 나타내는 지표에서 76.2를 기록하였으며 F-1 스코어의 경우 84.6을 기록 하였습니다. 이는 본 논문이 출시되었을시 SOTA로 지정되었습니다.

위의 지표는 RNN모델과의 성능 차이를 기록한 지표입니다.

위의 지표의 경우 BiDAF모델과의 비교 지표입니다.
