ML/DL
1.DBSCAN - 밀도 기반 클러스터링

본 포스팅에서는 밀도기반 클러스터링이라고도 불리는 DBSCAN(Density based spatial clustring of applications with noise)에 대해서 진행해 보도록 하겠습니다. DBSCAN은 19996년도의 A density-based al
2.CNN(Convolutional neural network)의 배경
본 포스팅에서는 대략적인 CNN이라고 불리는 Convolutional neural network의 역사에 대해 진행해보려구합니다. 최근 뉴스에서 인공지능이 하나의 주요 이슈로 부상하면서 우리는 머신러닝, 딥러닝이라는 말을 많이 들어보았을겁니다. 그럼 왜 인공지능이 주요
3.랜덤포레스트(Random Forest)
이번 포스팅에서는 tree 구조의 앙상블 학습방법인 랜덤포레스트(Random Forest) 에 대해 써보겠습니다. 랜덤포레스트는 기계학습의 일종으로, 분류, 회귀 분석 등 의 문제에 활용되며 훈련 과정에서 구성한 다수의 결정 트리로부터 분류 또는 평균 예측등에 주로 사
4.Confusion matrix(혼동 행렬) 및 평가지표
이번 포스팅에서는 ML모델의 평가 지표중 하나인 Confusion Matrix에 대해 진행해 볼려구 합니다.모델에 대한 성능 평가를 위해서 일반적으로는 정확도(accuracy)라는 기준을 주로 사용하는데, 정확도만을 이용하여 모델을 평가하기에는 충분하지 않을 수 있습니
5.Subword model은 무엇일까?(ft. FastText)
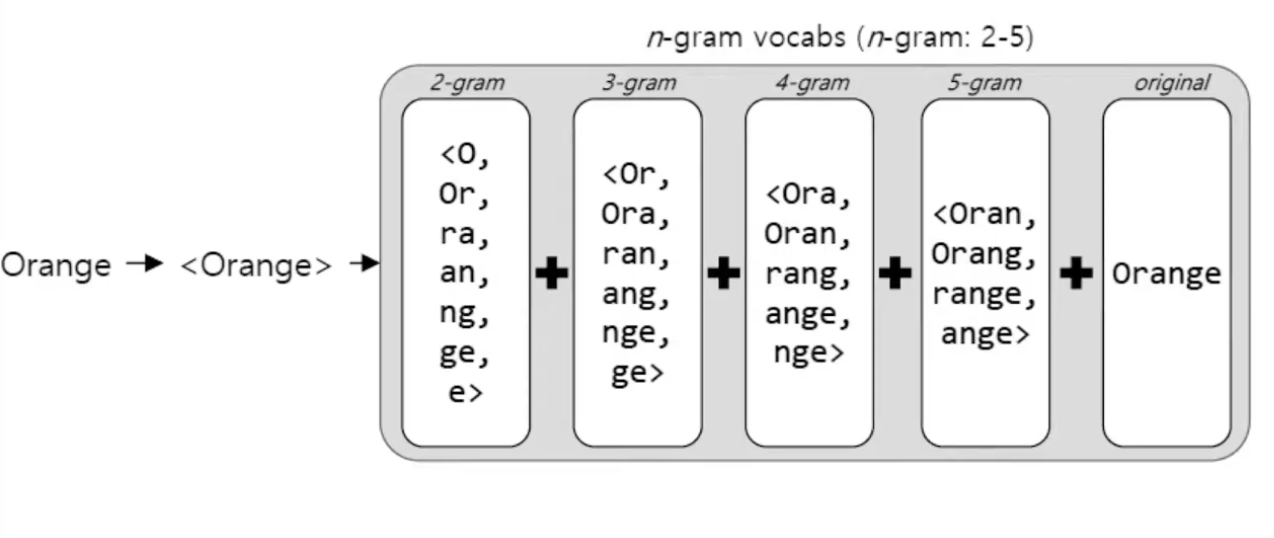
본 포스팅에서는 FastText(Enriching Word Vectors with Subword Information) 논문에서 말하는 Subword model에 대해 리뷰해 보도록 하겠습니다.FastText는 2017년 ACL에서 발표되었으며, 오늘날 워드임베딩의 개
6.Neural Probabilistic Language Model 논문리뷰
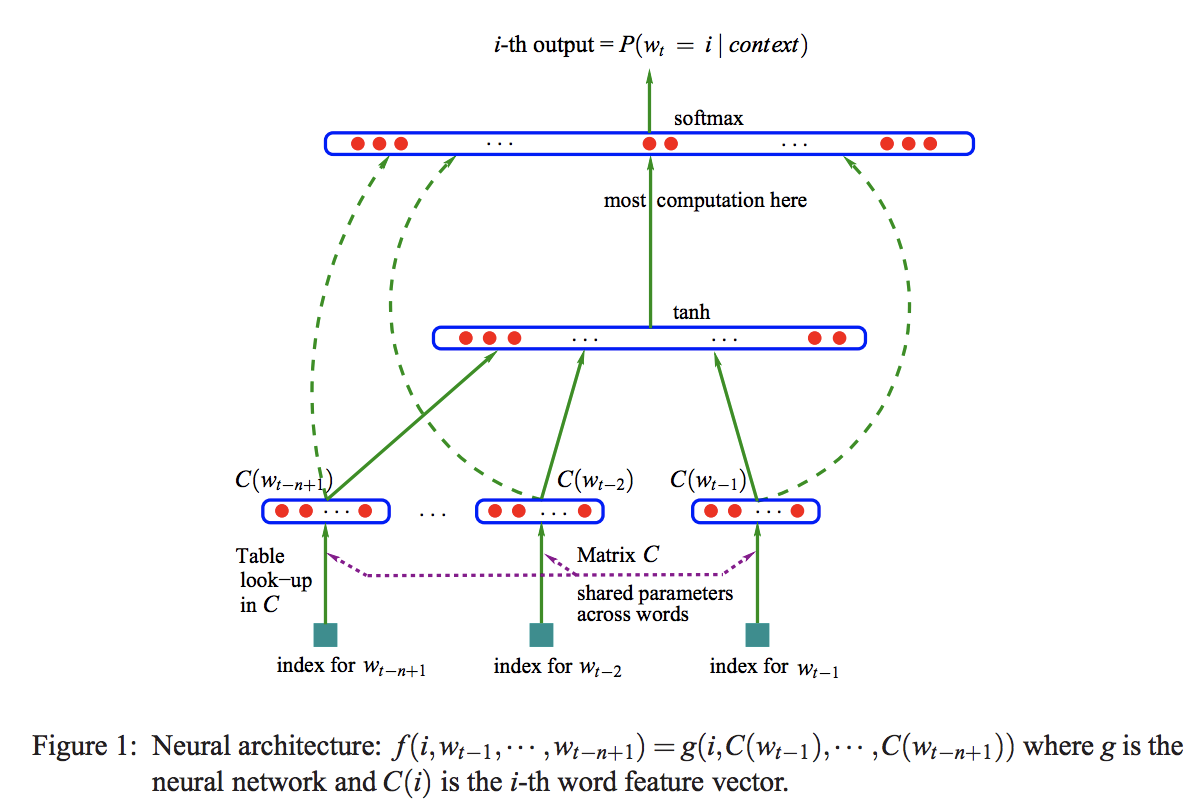
본 포스팅에서는 Neural Probabilistic Language Model(NPLM)의 논문에 대해 리뷰를 해보도록 하겠습니다.Statical language model은 단어의 시퀀스(Sequence)의 probability function을 찾는데 의의를 둡니
7.QANet 논문리뷰
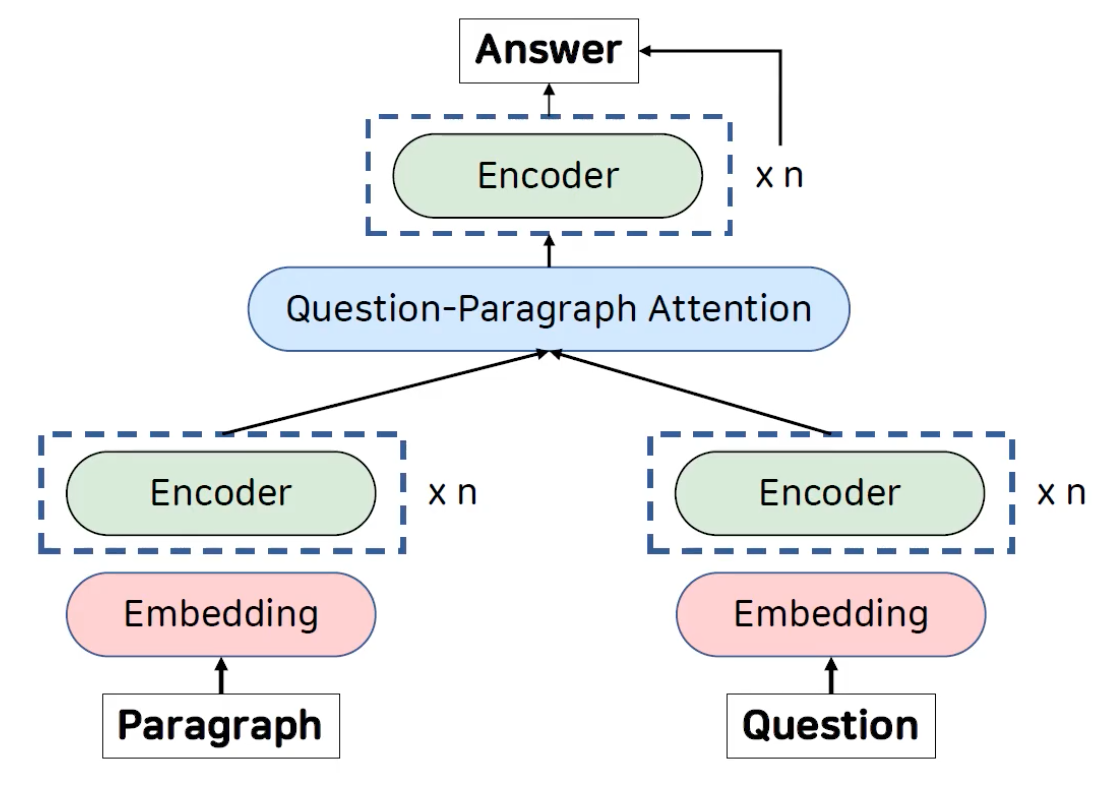
본 포스팅에서는 reading comprehension task에 대해 새로운 모델을 제시한 QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension에 대해 진행해보도록
8.RoBERTa 논문리뷰
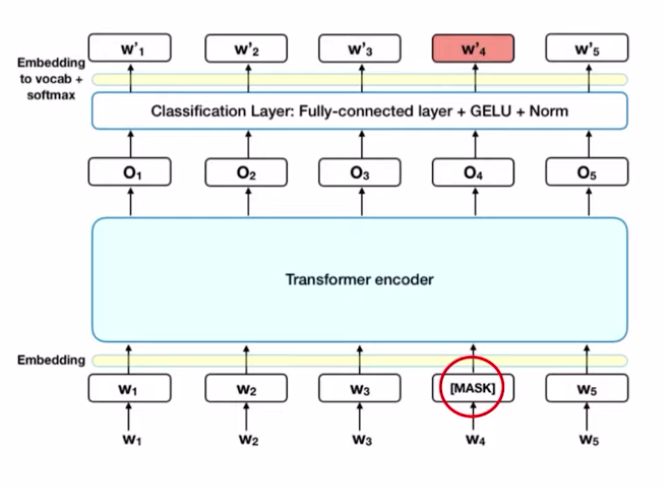
본 포스팅에서는 RoBERTa : A Robustly Optimized BERT Pretraing Model에 대해 소개해드리겠습니다. RoBERTa의 경우 BERT의 후속 모델로 유명합니다.BERT는 Bidirectional Encoder Representations