본 포스팅에서는 FastText(Enriching Word Vectors with Subword Information) 논문에서 말하는 Subword model에 대해 리뷰해 보도록 하겠습니다.
📌 서론
FastText는 2017년 ACL에서 발표되었으며, 오늘날 워드임베딩의 개념인 word vectors representation을 학습시키는 방법에 대한 논문입니다. 본 논문이 등장 할 때 까지만 해도 워드 임베딩(word embedding)이라는 단어 대신 distributed 혹은 continious word represnetation이라는 단어가 주로 사용되었습니다. FastText은 Word2vec을 타겟 논문으로 잡았으며, word2vec의 몇가지 한계점에 대해 언급했습니다.
📌 Word2Vec의 한계점
Word2Vec의 한계는 하나의 단어에 고유한 벡터를 할당 하기 때문에 단어의 형태학적 특징을 반영할수 없습니다. 예를 들어 go와 going이 라는 단어가 있다고 가정해 봅시다. Word2vec은 2개의 단어인 go 와 going에 대해 각각 고유한 벡터를 할당합니다.
이 두 단어는 근본적으로 'go'라는 같은 의미를 가짐에도 불구하고 서로다른 벡터를 할당받게 됩니다. 벡터 a가 go에 할당되고 b가 going에 할당되는 의미입니다. 이런식으로 같은 의미를 가진 단어들에 서로 다른 벡터를 할당하게 되면, 단어의 수가 기하급수적으로 많은 경우의 학습이 제대로 이루어지지 않을 가능성이 존재합니다
Word2Vec의 학습방법(Continuous Skip-gram)
word2vec모델의 학습방법은 총 w개의 단어가 있을때 각 단어들의 단어들에 대해 백터를 할당해주고 주변에 있는 단어들에 대해 어떠한 단어들이 올지 잘 예측할수 있게 학습 진행하게 됩니다.
먼저 수식을 통해 간략하게 살펴보며는 개의 단어 시퀀스가 있다고 가정했을 때, 라는 주변의 문맥단어인 를 잘 맞추는 방식으로 학습이 진행 됩니다. 즉 가 어떤 단어들이 왔을때, 확률값이 가장 높은 지를 최적화하는 방법으로 학습이 진행됩니다. 또한 와 는 서로다른 벡터를 지니게 됩니다. 즉 위의 2개의 벡터를 가지고 확률값을 만들어야 합니다.
Training focus에있는 모든 vocabulary에 대해서 가 주어졌을때 다른 모든단어들이 등장할 확률을 더한 것 분의 가 주어졌을때 실제 정답인 문맥 단어 가 등장할 확률을 분자로가면 확률값을 구할 수 있습니다.
대표적으로 이러한 경우 우리는 대표적으로 softmax를 사용하게 됩니다. 하지만 word2vec은 softmax를 사용하지 않는데, 이는 주변 문맥단어 한개에 대해 잘맞출수 있지만, 주위 다른단어들에 대해서는 예측이 어려운 상황이 생깁니다. 예를들어 5개의 단어가 있고 가운데에 라는 단어가 주어졌을 떄 가운데 를 보고 주위 단어를 맞춰야하는데, 1번째 단어가 잘 맞춰지도록 학습이 되면 2,4,5번째 단어들을 맞추기 어렵습니다.
따라서 word2vec은 softmax대신 네게티브샘플링(Negative Sampling)을 진행하게 됩니다. 간략하게 네거티브샘플링에 대해 설명드리면, 학습과정에서 전체 단어집합이 아니라 일부 단어 집합에만 집중하도록 하는 방법입니다.
📌 Subword Model
FasText논문에서는 subword model에 대한 중요성을 강조합니다. Subword model은 기존의 word2vec에서는 하나의 단어에서 주변단어들의 정보만을 가지고 지금현재 단어의 백터를 만들기 때문에 go와 going에서 둘이 동일하다는 내재적 정보를 반영하지 못하는 단점이 있습니다. Subword model의 경우 이를 다음과 같이 해결 합니다.
위의 그림과 같이 where 이라는 단어를 예를들면 where에 대해 각각을 나눌수 있는 모든 n-gram으로 나누게 합니다. 예를들면 이면, 경우로 나눕니다. 모든 n-gram으로 나눌수 있는 모든 경우의 수들의 단어들의 벡터를 더한값을 where의 백터로 나타나는게 subword model 입니다. 이것을 다시 수식으로 살펴보면 다음과 같습니다.
여기서 의 경우는 n-gram의 dictionary의 사이즈를 의미하고, 는 단어 에서 나올 수 있는 모든 n-gram의 경우의 세트이며, 는 n-gram의 각각 vector representaiton입니다.
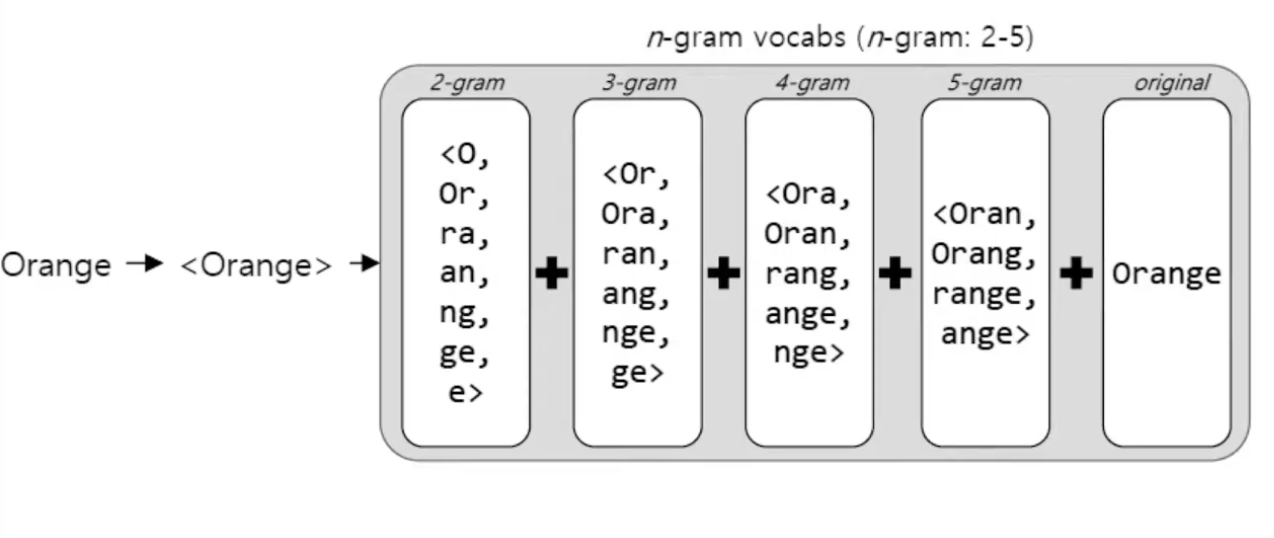
위의 그림을 살펴보면 Orange라는 단어가 주어졌을때 orange에 대해 n-gram에 대한 모든 경우의 수로 나타내면 총 n=2 부터 5까지로 나타나게 됩니다. 여기서 n이 2~5일때 까지의 n-gram의 경우의 수를 모두 더한값을 orange에 대한 하나의 백터로 사용하게 됩니다.
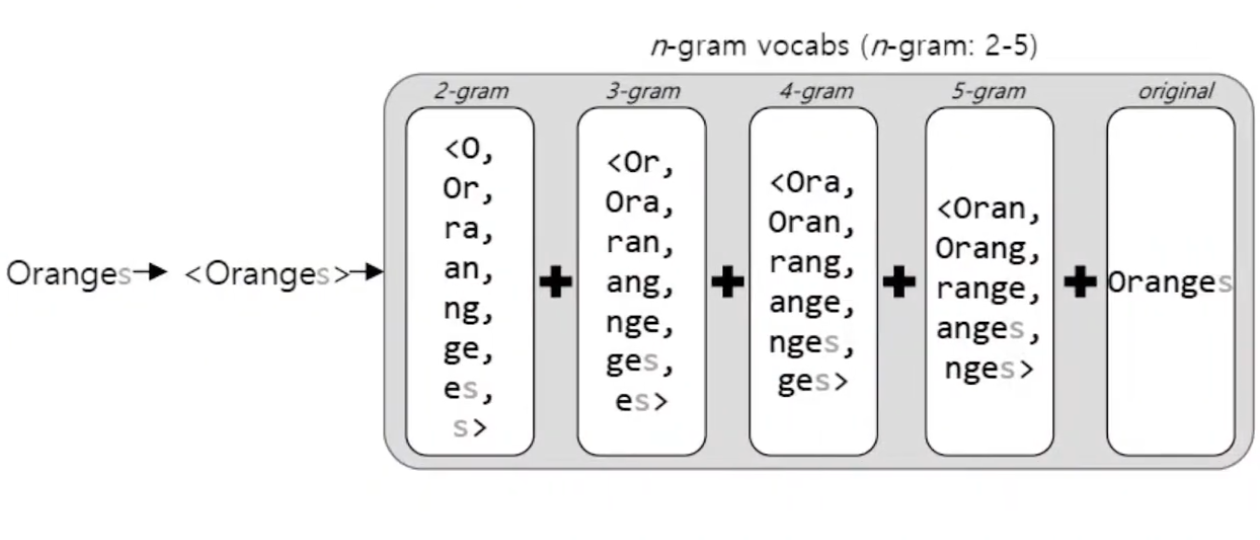
Subword modeld은 이렇게 모든 n-gram에 대한 경우의 수들의 합을 사용하므로써, 모르는 단어(Out Of Vocabulary, OOV)에 대해서도 다른 단어와의 유사도를 계산할 수 있어 위의 그림과 같이 oranges 라는 모르는 단어가 발생됬을때 해당 문제를 해결할수 있습니다.
Subword Model의 성능
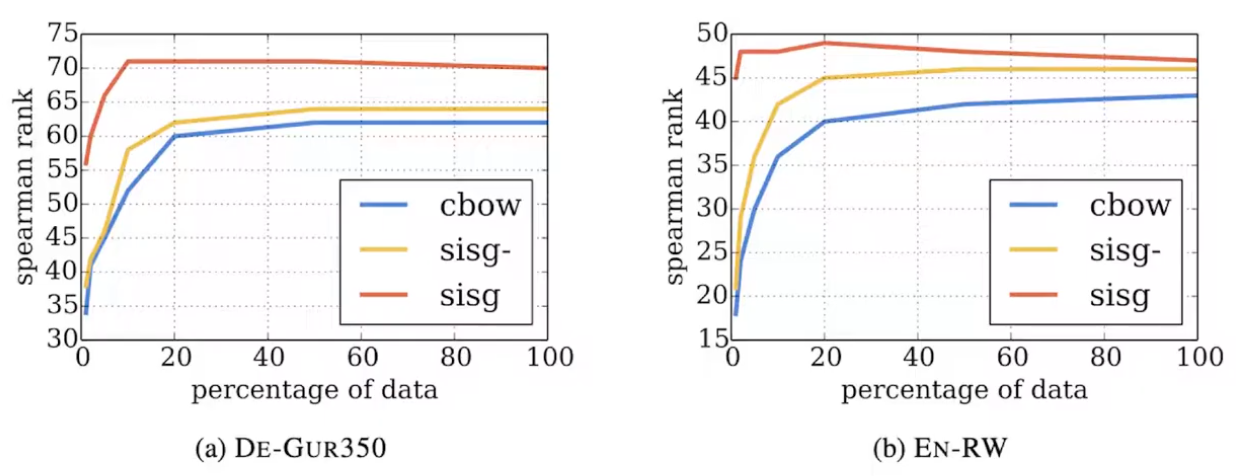
위의 그림은 FastText를 De-GUR350데이터와 EN-RW의 데이터를 가지고 학습을 했을때 성능에 대한 지표입니다.
sisg : FastText 모델
sigs- : OOV문제를 해결하지 않은 FastText 모델
cbow : Word2Vec의 CBOW 모델
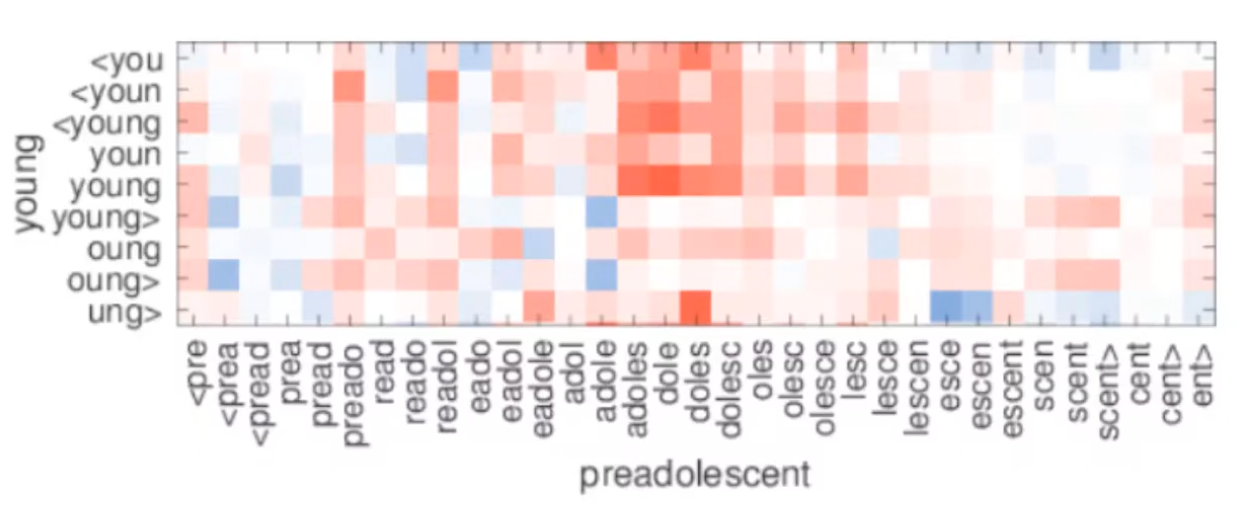
더나아가, young 과 preadolescent가 주어졌을때, 위의 차트를 보면 dole과 young의 유사도가 높은걸을 확인 할 수 있습니다. 여기서 preadolescef를 학습할때 young을 일부 반영하여 학습이 진행되는 점 역시 확인 할 수 있습니다.
