본 포스팅에서는 Neural Probabilistic Language Model(NPLM)의 논문에 대해 리뷰를 해보도록 하겠습니다.
Statical language model은 단어의 시퀀스(Sequence)의 probability function을 찾는데 의의를 둡니다. 하지만 본 논문에서는 이러한 경우 curse of dimensionality라는 차원의 저주가 발생한다고 하였습니다.
Curse of dimensionality는 단어와 같은 sequential한 데이터를 학습 시킬때, 차원이 증가함에 따라 학습데이터의 수가 생성된 차원의 수보다 적어지면서 모델의 성능이 저하되는 현상을 의미합니다.
📌 Curse of dimensionality
기계에게 단어를 인식시키기 위해서는 단어를 숫자로 변환해주어야 합니다. 이러한 방법중 one-hot-encoding이 존재하는데, 이는 개의 단어를 각각 차원의 벡터로 표현해주는 방식입니다.
즉, 단어가 포함되는 자리에 1을 넣은후 나머지는 0을 넣는다고 이해하면된다. 하디만 이러한 방식은 단어의 의미와 개념의 차이를 담아내기 어렵습니다.
One-hot vector는 1개의 요소만 1이고 나머지는 0 인 희소 벡터 형태를 띄기 떄문입니다.이때 단어의 내적은 0을 띄우며 직교형식을 이루며, 사전 내의 단어가 무수히 많다면, 예를들어 a라는 자연어가 10만개 존재한다면 a를 표현하기위해서는 10만개의 차원을 형성해내는 curse of dimensionality에 빠질 가능성이 존재합니다.이러한 Curse of dimensionality는 모델의 테스트를 위한 단어의 시퀀스가 트레이닝시 등장할 단어의 시퀸스와 다른 현상이 발생될 가능성이 존재합니다.
따라서 본 논문은 이러한 curse of dimensionality의 문제를 distributed representation(분산표상)을 통해 해결하고자 하였습니다. 즉, probability function에 대해 neural netwrok를 사용하는 단어에 distributed representation을 학습시켜 curse of dimensionality를 해결하는 방법을 제시하였습니다.
Distributed Representation(분산표상)
Distributed Representation은 curse of dimensionality의 문제를 해결하기 위한 방법 중 하나입니다. One hot vector에서의 차원 의 수는 전체 단어의 수가 되는데 이를 더작은 차원 벡터로 바꿉니다.
Distributed Representation으로 표현된 단어의 벡터는 연속형의 실수값이되며 이는 비슷한 분포를 가진 단어의 주변 단어들도 비슷한 의미를 가진다는것을 의미합니다. 또한 내의 각각의 차원은 정보를 내포하고있어 벡터연산을 통해 벡터간 similarity를 구할 수 있습니다.
📌 Neural Probabilistic Language Model(NPLM)
Neural Probabilistic Language Model(NPLM)은 curse of dimensionality를 해결하기 위해 효과적이면서 효율적인 확률 모델링 기법을 제시합니다. 그리고 모델의 단어의 시퀀스가 서로 달라지는 현상에 대한 해결방법 역시 제시 하였습니다.
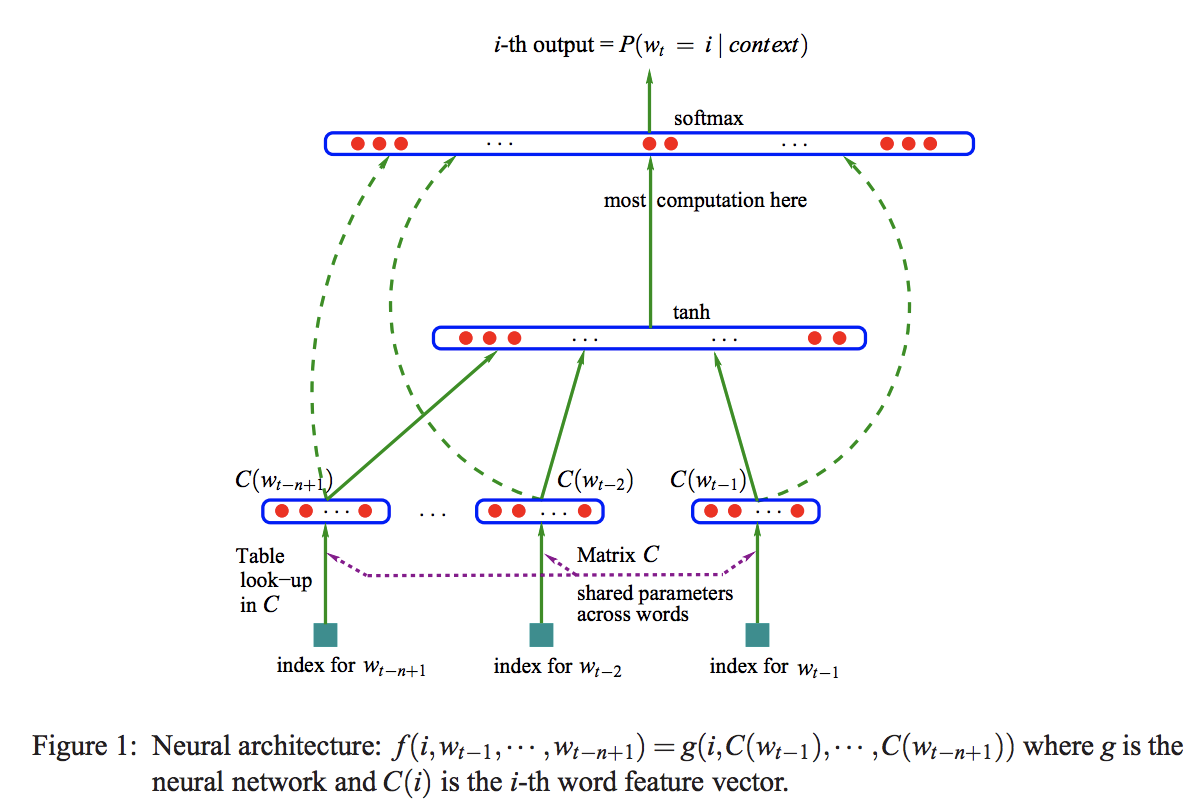
Neural Probabilistic Language Model(NPLM)은 어휘 내 각 단어들을 분산된 단어 백터와 연관시키고 시퀀스에서 이 단어들의 벡터로 단어 시퀀스의 결합 함수를 표현하고, 단어 벡터와 파라미터를 동시에 학습 하는 모델입니다. 또한 단어에 대한 확률함수는 문맥상 단어에 대한 벡터의 입력 시퀀스를 다음 단어에 대한 조건부 확률 분포에 mapping을 합니다.
즉, Neural Probabilistic Language Model(NPLM)은 각 단어의 distributed representation과 distributed representation에 대한 함수로써, 시퀀스의 확률함수를 학습합니다. 또한, Neural Probabilistic Language Model(NPLM)의 신경망에는 tanh화 되어있는 hidden layer와 output의 경우 softmax 함수로 이루어져있습니다.
본 논문의 경우 총 2가지의 데이터로 실험을 진행 하였습니다. 먼저 brawn campus의 경우 1,101,401개의 단어로 구성되었으며 이중 대략 8:2의 비율로 학습을 진행 하였습니다. 또한 AP Nese Corpus의 경우 14million 개의 단어로 학습을 진행하였으며, 이중 1million개의 단어를 각각 test 및 validation 데이터로 사용하였습니다.
그리고 Neural Probabilistic Language Model(NPLM)와의 비교를 위해 Smoothed trigram model과 back-off-n-gram model를 사용 하였습니다. Neural Probabilistic Language Model(NPLM)의 결과로는 neural network를 사용할때 좋은 결과를 얻을 수 있었으며, MLP(Multi-layer perceptron)을 적용 시켰을 때 Brown corpus의 경우 대략 24% 그리고 AP Nese Corpus 8%의 차이가 존재 하였습니다.
NPLM의 동작 과정
Neural Probabilistic Language Model(NPLM)은 단어의 시퀀스가 제공되었을 때, 다음단어가 무엇인지 맞추는 과정에서 학습을 진행한다고 합니다. 즉 개의 단어로 다음단어를 예측하는한다고 합니다. 즉 아래의 수식과 같이 나타낼수 있습니다.
수식을 살펴보면, NPLM은 위의 조건부 확률을 최대화 하려고 합니다.
그리고 NPLM의 밑부분 출력은 차원의 score vector 에 softmax 함수를 적용한 차원의 확률 벡터라고 합니다. 이때 는 다음과 같이 정의 됩니다.
즉 NPLM은 에 softmax를 적용시킨후 backpropogation 하는 방식으로 학습합니다. NPLM의 입력은 문장의 n번째 단어에 대응하는 단어 백터 를 만드는 과정입니다. 이러한 Nueral Probabilistic Language Model의 구조를 살펴보면 다음과 같습니다.