
그래프 탐색 알고리즘이란?
그래프 탐색 알고리즘(Graph Search Algorithm):
- 그래프 구조에서 노드와 간선을 탐색하는 알고리즘을 말한다.
- 자료구조에서 데이터를 어떻게 구축할지 고민한다면, 알고리즘에서는 어떤 순서와 방식으로 탐색할지를 고민한다.
그래프 탐색 알고리즘의 종류
그래프 탐색 알고리즘은 크게 두 가지로 나눌 수 있다. 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)이다. 우선 간단히 경로를 찾는 방법을 설명해 보겠다.
-
깊이 우선 탐색(
DFS): 더 이상 탐색할 노드가 없을 때까지 일단 가본다. 그러다가 더 이상 탐색할 노드가 없으면 최근에 방문했던 노드로 되돌아간 다음 가지 않은 노드를 방문한다. -
너비 우선 탐색(
BFS): 현재 위치에서 가장 가까운 노드부터 모두 방문하고 다음 노드로 넘어간다. 그 노드에서 또 다시 가장 가까운 노드부터 모두 방문한다.
이 두 방법으로 탐색하는 과정을 그림으로 보자.
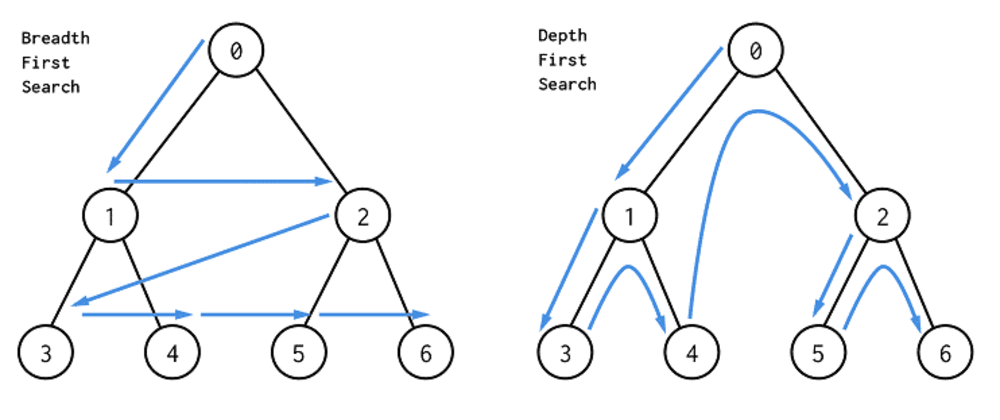
우선 깊이 우선 탐색에서는 0-1-3까지 방문하다가 더 이상 갈 곳이 없으므로 위로 올라와 4를 방문한다. 같은 방식으로 2-5를 방문한 후 마지막으로 6을 방문한다. 최종 방문 루트는 0-1-3-4-2-5-6이다.
너비 우선 탐색에서는 가장 가까운 곳부터 방문하므로 0-1-2 순으로 방문한다. 그 다음으로 가까운 3으로 이동해 3-4-5-6 루트로 이동한다. 최종 방문 루트는 0-1-2-3-4-5-6이다.
🌲 깊이 우선 탐색(DFS)
깊이 우선 탐색(DFS)은 시작 노드에서 출발하여 더 이상 방문할 수 없는 깊이까지 탐색한 후, 다시 이전에 방문한 노드로 *백트래킹하여 탐색하는 방법이다. 주로 스택 자료구조를 사용하여 구현한다.
💡 백트래킹(
back tracking)이란?
탐색하고 있는 방향의 역방향으로 되돌아가는 동작을 백트래킹(back tracking)이라고 한다. 스택은 최근에 푸시한 노드를 팝할 수 있으므로 특정 노드를 방문하기 전, 최근 방문 노드를 팝 연산으로 쉽게 확인할 수 있다.
🗒️ 깊이 우선 탐색(DFS) 과정
-
시작 노드 설정: 시작 노드를 스택에 넣고 방문 처리한다.
-
스택이 비었는지 확인: 스택이 비었다는 건 방문할 수 있는 모든 노드를 방문했음을 의미한다. 따라서 스택이 비었으면 탐색을 종료한다.
-
스택이 빌 때까지 반복:
-
스택에서 노드를 팝한다. 팝한 원소는 최근에 스택에 푸시한 노드이다.
-
팝한 노드의 방문 여부를 확인한다. 아직 방문하지 않았다면 노드를 방문 처리한다.
-
방문한 노드와 인접한 모든 노드를 확인하고, 그 중 아직 방문하지 않은 노드를 스택에 푸시한다. 스택은
FILO구조이므로 역순으로 노드를 푸시해야 한다.
-
🚨 코드로 구현할 때 고려사항
-
탐색할 노드가 없을 때까지 간선을 타고 내려갈 수 있어야 한다.
-
가장 최근에 방문한 노드를 알아야 한다.
-
이미 방문한 노드인지 확인할 수 있어야 한다.
깊이 우선 탐색의 핵심은 '가장 깊은 노드까지 방문한 후에 더 이상 방문할 노드가 없으면 최근 방문한 노드로 돌아온 다음, 해당 노드에서 방문할 노드가 있는지 확인한다'이다.
💻 스택을 활용한 DFS
다음은 간단한 그래프를 통해 DFS를 설명하는 예제이다. 아래 그래프를 시작 노드 A에서 DFS로 탐색하는 과정을 살펴보자.
A
/ | \
B C D
| |
E F-
초기 상태: 시작 노드 A를 스택에 넣고 방문 처리한다.
Stack: [A] # Stack []은 방문한 노드들을 의미한다. 방문 처리: A 방문 -
A 노드에서 꺼내서 탐색: A에서 인접한 노드 B, C, D를 스택에 넣고 방문 처리한다.
Stack: [D, C, B] 방문 처리: B 방문, C 방문, D 방문 -
B 노드에서 꺼내서 탐색: B에서 인접한 노드 E를 스택에 넣고 방문 처리한다.
Stack: [D, C, E] 방문 처리: E 방문 -
E 노드에서 꺼내서 탐색: E는 더 이상 인접한 노드가 없으므로 다음 노드를 꺼낸다.
Stack: [D, C] 방문 처리: C 방문 -
C 노드에서 꺼내서 탐색: C는 더 이상 인접한 노드가 없으므로 다음 노드를 꺼낸다.
Stack: [D] 방문 처리: D 방문 -
D 노드에서 꺼내서 탐색: D에서 인접한 노드 F를 스택에 넣고 방문 처리한다.
Stack: [F] 방문 처리: F 방문 -
F 노드에서 꺼내서 탐색: F는 더 이상 인접한 노드가 없으므로 스택에서 꺼낸다.
Stack: [] -
탐색 종료: 스택이 비어있으므로 탐색을 종료한다.
이렇게 스택을 이용하여 깊이 우선 탐색(DFS)을 구현할 수 있다. 이 경우 최종 탐색 루트는 A-B-E-C-D-F로 깊이 우선 탐색의 순서를 그대로 따른다.
🔄️ 재귀 함수를 활용한 DFS
스택을 직접 사용하지 않고도 재귀 함수를 활용해 깊이 우선 탐색을 구현할 수 있다. 재귀 함수를 호출할 때마다 호출한 함수는 시스템 스택이라는 곳에 쌓이므로 DFS에활용할 수 있는 것이다.
def dfs(graph, start, visited):
# 현재 노드를 방문 처리
visited[start] = True
print(f"방문 처리: {start}")
# 현재 노드와 연결된 다른 노드들을 재귀적으로 방문
for neighbor in graph[start]:
if not visited[neighbor]:
dfs(graph, neighbor, visited)
# 예시 그래프의 인접 리스트 표현
graph = {
'A': ['B', 'C', 'D'],
'B': ['A', 'E'],
'C': ['A', 'F'],
'D': ['A', 'F'],
'E': ['B'],
'F': ['C', 'D']
}
# 방문 여부를 나타내는 리스트
visited = {node: False for node in graph}
# 시작 노드 'A'에서 DFS 시작
dfs(graph, 'A', visited)이 코드에서 dfs 함수는 세 개의 인자를 받는다.
graph: 그래프를 인접 리스트로 표현한 딕셔너리start: 현재 탐색할 노드를 나타냄visited: 각 노드의 방문 여부를 기록하는 딕셔너리
함수의 동작
-
시작 노드
start를 방문 처리하고 출력한다. -
시작 노드와 연결된 각 인접 노드에 대해 순회한다.
-
인접 노드가 방문되지 않았다면 해당 노드를 새로운 시작 노드로 설정하여 재귀적으로
dfs함수를 호출한다.
이렇듯 재귀적인 호출을 통해 시작 노드에서 출발하여 깊이 우선 탐색을 수행하며, 방문된 노드들을 차례로 출력할 수 있다.
🌊 너비 우선 탐색(BFS)
너비 우선 탐색(Breadth-First Search, BFS)은 그래프나 트리에서 가까운 노드부터 탐색하는 알고리즘입니다. BFS는 두 노드 사이의 최단 경로를 찾거나 상태 공간 탐색 문제에서 최소 단계로 목표 상태에 도달하는 데 유용하게 사용됩니다. 이 알고리즘은 큐(Queue)를 사용하여 구현됩니다.
🗒️ 너비 우선 탐색(BFS) 과정
-
시작 노드를 큐에 넣고 방문 처리:
- 시작 노드를 큐에 넣고 방문 처리한다.
-
큐에서 노드를 꺼내어 인접한 노드들을 큐에 추가:
- 큐에서 노드를 하나 꺼내고, 이 노드의 인접한 모든 미방문 노드들을 큐에 넣고 방문 처리한다.
-
반복:
- 큐가 빌 때까지 위 과정을 반복한다. 큐는 선입선출(FIFO)의 구조를 가지므로, 가장 먼저 들어온 노드부터 탐색을 진행한다.
-
모든 노드를 방문할 때까지 혹은 목표 노드에 도달할 때까지 반복:
- BFS는 모든 노드를 방문하거나 목표 노드에 도달할 때까지 탐색을 계속한다.
💻 큐를 활용한 BFS
다음은 간단한 그래프를 통해 BFS를 설명하는 예제이다. 아래 그래프를 시작 노드 A에서 BFS로 탐색하는 과정을 살펴보자.
A
/ | \
B C D
| |
E F이 그래프를 인접 리스트로 표현하면 다음과 같다.
graph = {
'A': ['B', 'C', 'D'],
'B': ['A', 'E'],
'C': ['A', 'F'],
'D': ['A', 'F'],
'E': ['B'],
'F': ['C', 'D']
}-
초기 상태: 시작 노드 'A'를 큐에 넣고 방문 처리한다.
Queue: [A] 방문 처리: A 방문 -
'A'를 꺼내고 인접한 노드들을 큐에 추가:
- 'A'의 인접 노드는 'B', 'C', 'D'이다. 이들을 순서대로 큐에 넣고 방문 처리한다.
Queue: [B, C, D] 방문 처리: B 방문, C 방문, D 방문 -
'B'를 꺼내고 인접한 노드들을 큐에 추가:
- 'B'의 인접 노드는 'A', 'E'이다. 이미 'A'는 방문한 상태이므로 'E'를 큐에 넣고 방문 처리한다.
Queue: [C, D, E] 방문 처리: E 방문 -
'C'를 꺼내고 인접한 노드들을 큐에 추가:
- 'C'의 인접 노드는 'A', 'F'이다. 'A'는 이미 방문한 상태이므로 'F'를 큐에 넣고 방문 처리한다.
Queue: [D, E, F] 방문 처리: F 방문 -
큐에서 노드 'D'를 꺼내고 인접한 노드들을 큐에 추가:
- 'D'의 인접 노드는 'A', 'F'이다. 둘 다 이미 방문한 상태이므로 추가할 노드가 없다.
Queue: [E, F] -
큐에서 노드 'E'를 꺼내고 인접한 노드들을 큐에 추가:
- 'E'의 인접 노드는 'B'이다. 'B'는 이미 방문한 상태이므로 추가할 노드가 없다.
Queue: [F] -
큐에서 노드 'F'를 꺼내고 인접한 노드들을 큐에 추가:
- 'F'의 인접 노드는 'C', 'D'이다. 둘 다 이미 방문한 상태이므로 추가할 노드가 없다.
Queue: [] -
탐색 종료:
- 큐가 비어 있으므로 BFS 탐색을 종료한다.
이렇게 큐를 활용하여 BFS를 구현할 수 있다. 최종 탐색 루트는 A → B → C → D → E → F이다.
🆚 깊이 우선 탐색 vs 너비 우선 탐색
| 항목 | 깊이 우선 탐색 (DFS) | 너비 우선 탐색 (BFS) |
|---|---|---|
| 동작 방식 | 한 경로를 최대한 깊이 탐색 후 다른 경로 탐색 | 한 레벨의 모든 노드를 탐색 후 다음 레벨 탐색 |
| 구현 방법 | 스택(Stack) 또는 재귀 함수로 구현 | 큐(Queue)로 구현 |
| 메모리 사용 | 적은 메모리 사용 (재귀 스택 사용 가능) | 많은 메모리 사용 (각 레벨의 모든 노드를 저장) |
| 적합한 문제 | 사이클 검사, 경로 찾기 등 | 최단 경로 찾기, 최소 단계 탐색 등 |
| 선택 기준 | 깊이에 따라 탐색해야 할 때 선택 | 최단 경로를 찾거나 너비 기준 탐색할 때 선택 |
깊이 우선 탐색의 활용
깊이 우선 탐색은 모든 가능한 해를 찾는 백트래킹 알고리즘이나 그래프의 사이클을 감지해야 하는 경우 활용할 수 있다.
코딩 테스트에서는 일반적인 경로 탐색이나 사이클 검사와 같이 깊이 우선으로 탐색해야 할 때 유용하며, 재귀적 구현이 필요한 경우에 많이 사용된다.
너비 우선 탐색의 활용
너비 우선 탐색은 찾은 노드가 시작 노드로부터 최단 경로임을 보장한다. 왜냐하면 시작 노드로부터 직접 간선으로 연결된 모든 노드를 먼저 방문하기 때문이다.
코딩 테스트에서는 미로 찾기 문제에서 최단 경로를 찾거나, 네트워크 분석 문제를 풀 때 활용할 수 있다.
마치며
다음 게시물은 그래프 최단 경로 구하기를 다룰 것 같다. 향후 다익스트라 알고리즘 등을 다룰 때 이해할 수 있도록 그래프에 대해 잘 공부하자.
