
REST
데이터를 주고받기 위한 아키텍처
URI로 자원을 명시하고, HTTP METHOD로 CRUD 연산을 한다.
다익스트라 알고리즘
그래프에서 한 정점(노드)에서 다른 정점까지의 최단 경로를 구하는 알고리즘.
- 출발 노드와 도착 노드를 설정한다.
- 현재 위치한 노든의 인접 노드 중 방문하지 않은 노드를 구별하고, 방문하지 않은 노드 중 거리가 가장 짧은 노드를 선택한다. 그 노드는 방문 처리한다.
Session Based Authentication
User logs in and then Server stores seesion data in memory. Server sends cookie to the client. Client sends auth request and cookie and then server compares session-id with stored data. Server sends response.
Token based Authentication
유저가 로그인을 하면 서버는 클라이언트에게 jwt를 발급해준다. 클라이언트는 jtw를 로컬 스토리지에 저장한다. 클라이언트는 헤더에 jwt를 넣어서 인증 요청을 보낸다. 서버는 해당 유저의 jwt가 맞는지 검증한다. 맞다면 리스판스 한다.
Summary
To sum up, for session, It it better for security because all authentication information are saved on the server. However, server doesn't keep track of the token, while client have all quthentication information. It enhances the risk of the security. 또한 페이로드가 암호화되지 않아 민감한 정보는 실릴 수 없다.
대부분의 웹 어플리케이션의 서버 확장 방식은 scale-out이다. 이 경우 정합성의 문제가 발생할 수 있다. 토큰 방식을 사용할 경우 세션 불일치의 위험을 줄일 수 있다. HTTP의 비상태성(stateless)를 그대로 활용할 수 있다는 측면에서 확장성이 좋다.
JWT, Refresh, Access Token
With security, access tokens have a short expiry time, so users have to log in newly every time the expiring time is closed and should have access tokens.
Refresh token
Token for access token again
-
Client requests to the server for log-in.
-
Server issues access and refresh tokens to the client, while stored refresh on the server.
-
Client saved two tokens on the local storage.
-
Client requests with header adding access token to the server every time.
-
If the access token has expired, the server responds to the state code that it has expired to the client.
-
Client sends refresh token for access token.
-
Server then validates the refresh token, and if no issue, issues a new access token.
-
Client map new access token origin access token.
OAuth
Open Authorization
다른 웹사이트에서 패스워드를 주지 않고 웹사이트 또는 어플리케이션이 유저 자신의 정보에 access할 수 있는 권한을 허용하는 것을 말한다. 제 3의 어플리케이션 또는 웹사이트가 유저 자신의 계정에 대한 정보를 공유할 수 있도록 하는 것이다. credential 없이 서버 자원에 third-party가 access할 수 있는 권한을 주는 것을 명시한다. OAuth는 authrorization server가 제 3의 클라이언트에게 엑세스 토큰을 발급해준다. 그러면 제 3자는 액세스 토큰을 사용해서 보호된 자원에 엑세스할 수 있다.
HTTP 상태코드
200 OK
요청이 성공적으로 처리되었음을 나타낸다. It refers to that the request is carried out successfully. GET: resource를 불러와서 메시지 바디에 전송된다. PUT/POST: 수행 결과에 대한 리소스가 메시지 바디에 전송된다.
201 Created
요청이 성공적이었고 그 결과로 새로운 리소스가 생성되었을 때의 응답코드. 보통 POST / PUT 요청 이후에 따라온다.
400 Bad Request
This response means that the server can't understand the request for wrong semantics.
*401 Unauthorized
비인증을 의미한다.
403 Forbidden
클라이언트는 콘텐츠에 접근할 권리를 가지고 있지 않다. 401과 다른 점은 서버가 클라이언트가 누구인지 알고 있다.
404 Not Found
The server cannot found the resource requested. It means that it's unknown URL in browser.
500 Internal Server Error
It means that the Server doesn't know how to handle that.
502 Bad Gateway
CI/CD
CI and CD stand for continuous integration and continuous delivery/continuous deployment. Automated build-and-test steps triggered by CI ensure that code changes being merged into the repository are reliable.
TDD (Test Driven Development)
프로세스와 쓰레드
Program
어떤 작업을 위해 실행할 수 있는 파일
Process
컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램.
- 메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)
- 운영체제로부터 시스템 자원을 할당받는 작업의 단위
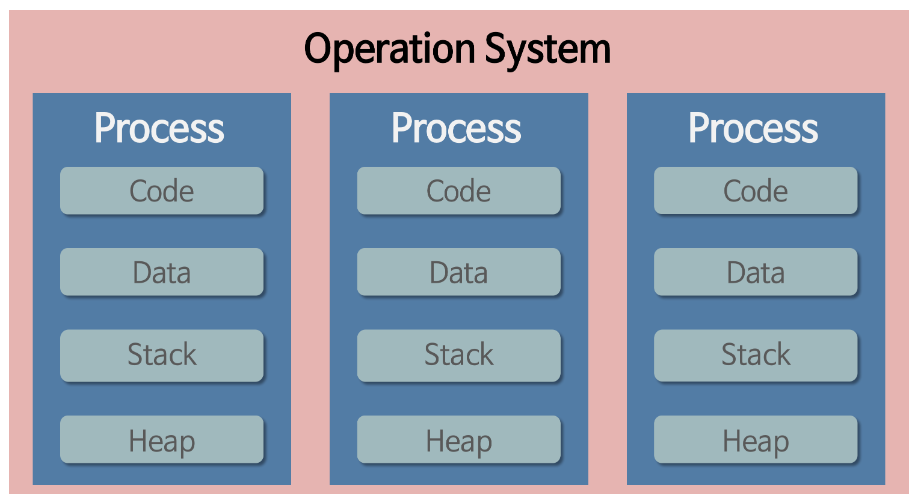
- 프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
- 프로세스당 최소 1개의 스레드를 가지고 있다.
- 각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
- 한 프로세스가 다른 프로세스의 자원에 접근하기 위해서는 프로세스 간의 통신(IPC: Inter-process communication)을 사용해야 한다.(PIPE, FILE, SOCKET ...)
Thread
- 프로세스 내에서 실행되는 여러 흐름의 단위
- 프로세스의 특정한 수행 경로
- 프로세스가 할당받은 자원을 이용하는 실행의 단위
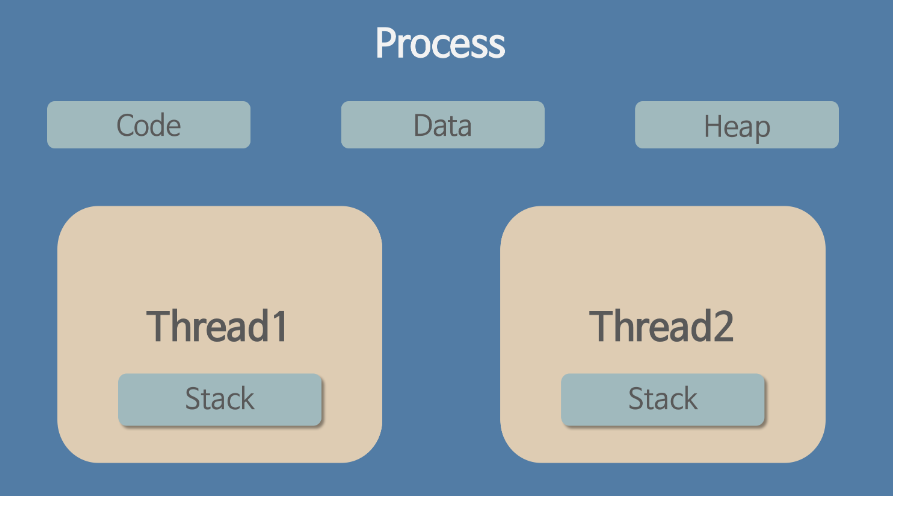
- 프로세스 내에서 각각 stack만 따로 할당받고, code, data, heap 영역은 공유한다.
Context Switching
- CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 과정.
- 동작 중인 프로세스가 대기를 하면서 해당 프로세스의 상태(Context)를 보관하고, 대기하고 있던 다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 작업
멀티 스레드
- 하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것.
- 시스템 콜이 줄어들어 자원의 효율적 관리
- context switching이 빠르다.
- 설계가 까다롭다 (디버깅도)
- 단일 프로세스의 경우 효과를 기대하기 어렵다.
- 동기화 문제
멀티프로세스와 멀티쓰레드의 특징
프로세스는 운영체제로부터 자원을 할당받는 작업의 단위이고 스레드는 프로세스가 할당받은 자원을 이용하는 실행의 단위이다.
- 멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 콘텍스트 스위칭이 빠르다는 장점이 있지만 동기화 문제와 하나의 스레드가 장애가 발생 시 전체 스레드의 위험이 될 수 있다는 risk를 안고 있다.
- 멀티 프로세스는 하나의 프로세스가 죽더라도 다른 프로세스에 영향을 주지 않아 안정성이 높지만, 멀티 스레드보다 많은 메모리공간과 CPU 시간을 차지하는 단점을 가지고 있다.
- 자원의 효율적인 관리를 생각하면 멀티 스레드를 쓰는게 맞다(메모리 효율) => 자원을 할당하는 시스템 콜의 감소 / 통신 비용 감소
- 스레드 간의 자원 공유는 전역 변수를 사용하기 때문에 동기화 문제가 발생할 수 있다.
멀티 프로세스
두 개 이상의 프로세서(CPU)가 협력적으로 하나 이상의 작업(Task)를 동시에 처리하는 것 (병렬처리)
각 프로세스 간 메모리 구분이 필요하거나 독립된 주소 공간을 가져야 할 경우 사용한다.
- 독립된 구조로 안정성이 높다
- 프로세스 중 하나에 문제가 생겨도 다른 프로세스에 영향을 주지 않아 작업의 속도는 영향을 받으나 정지되는 문제가 발생하지는 않는다.
- 작업량이 많을 경우, 콘텍스트 스위칭이 자주 일어나 오버헤드가 발생하여 성능저하를 나타낼 수 있다.
콘텍스트 스위칭
CPU는 한번에 하나의 프로세스만 실행 가능하다. CPU에서 여러 프로세스를 돌아가면서 작업처리하는 과정을 의미한다. 구체적으로, 동작 중인 프로세스가 대기를 하면서 해당 프로세스의 상태(context)를 보관하고, 대기하고 있던 다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 작업
멀티 스레드
하나의 프로세스에서 여러 스레드로 자원을 공유하며 작업을 나누어 수행하는 것
- 자원의 효율성(시스템 콜: <프로세스를 생성하여 자원을 할당> 감소)
- 콘텍스트 스위칭이 빠르다.
- 통신 비용이 적다.
- 힙 영역을 공유하므로 데이터를 주고 받을 수 있다.
- 자원을 공유해서 동기화 문제가 발생할 수 있다.(병목현상, 데드락)
- 디버깅이 어렵다.
- 성능저하가 발생할 수 있다.
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받는다.
- 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
쿼리 최적화
_ 불필요한 컬럼을 불러오지 않고 필요한 열만 갖고 온다. Like를 사용 시 와일드카드 문자열(%)을 string 앞 부분에 배치하지 않는 것이 좋다. 중복값을 제거하는 연산을 최대한 지양해야 한다. 중복 값을 제거하는 연산은 많은 시간을 필요로 한다. 대안으로 distinct 보다는 exists를 들 수 있다. 같은 내용의 조건이라면 GROUP BY 연산 시 HAVING보다는 WHERE 절을 이용하는 것이 좋다. 쿼리 실행 순서가 WHERE 절이 HAVING절보다 먼저 실행되서 먼저 WHERE 절로 데이터를 잘게 짤라서 효율적인 연산이 가능하다. groupby는 뭉탱이로 조건을 거는 거기 때문에 효율적이지 않다. 3개 이상의 테이블을 이너 조인 할 때는 크기가 가장 큰 테이블을 프롬 절에 배치하고 이너 조인 절에는 남은 테이블을 작은 순서대로 배치하는 것이 좋다.
DB 로직 최소화
- 일관된 데이터 모델링
- 데이터베이스 테이블과 엔터티를 일관성 있게 설계
- 중복 데이터를 피하고 정규화를 적용하여 중복을 최소화여 무결성을 유지한다.
- 비즈니스 로직 분리
- 데이터베이스에 직접적인 비즈니스 로직을 내장시키는 것을 피하고 서비스나, 애플리케이션 레이어에서 비즈니스 로직을 처히다로고 분리시키다.
- 조회 최적화
- 쿼리를 작성할 때는 필요한 데이터만 조회하고 조인 등 복잡한 연산을 최소화
- 필요한 데이터를 미리 계산하여 캐싱하거나 데이터베이스 뷰를 이용하여 미리 계산된 결과를 조회하는 방식을 고려한다.
- 인덱스 활용
- 필요한 컬럼에 인덱스를 걸어 검색 성능을 높인다.
- 하지만 과도한 인덱싱은 쓰기 성능에 부정적으로 영향을 미칠 수 있어 잘 관리해야 한다.
- 쿼리 캐싱
- 자주 사용되는 쿼리 결과를 캐싱하여 반복적인 쿼리 실행을 피한다.
캐싱 시 데이터 갱신 주기와 데이터의 유효성을 고려해야 한다.
-
트랜잭션 사용 최소화
-
배치 처리
- 배치 작업을 활용하여 대량의 데이터를 처리
- 적절한 커밋 주기와 배치 크기를 설정하여 성능의 최적화
-
프로시저 및 함수 활용
-
데이터 캐싱
- 자주 사용되는 데이터를 애플리케이션 내에 캐시하여 데이터베이스 접근을 줄이고 성능을 향샹시킨다.
- 제약 조건 활용
- 데이터 무결성 보장 검색 성능 향상
유지보수성을 높이는 데 큰 도움이 된다.
