강의 & 실습 5)
KLUE 데이터셋 소개
한국어 자연어 이해 벤치마크
-
단일 문장 분류 task
- 문장 분류, 관계 추출
-
문장 임베딩 벡터 유사도
- 문장 유사도
-
두 문장 관계 분류 task
- 자연어 추론
-
문장 토큰 분류 task
- 개체명 인식, 품사 태깅, 질의 응답
-
목적형 대화
-
의존 구문 분석
의존 구문 분석
단어들 사이의 관계를 분석하는 task
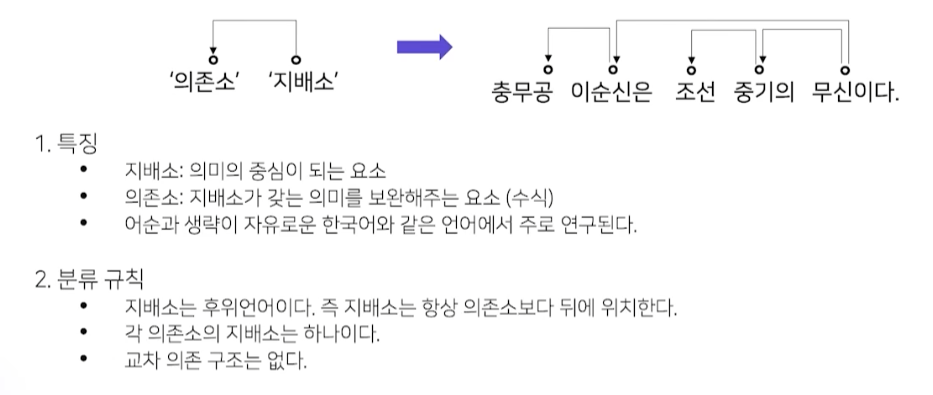
분류 방법
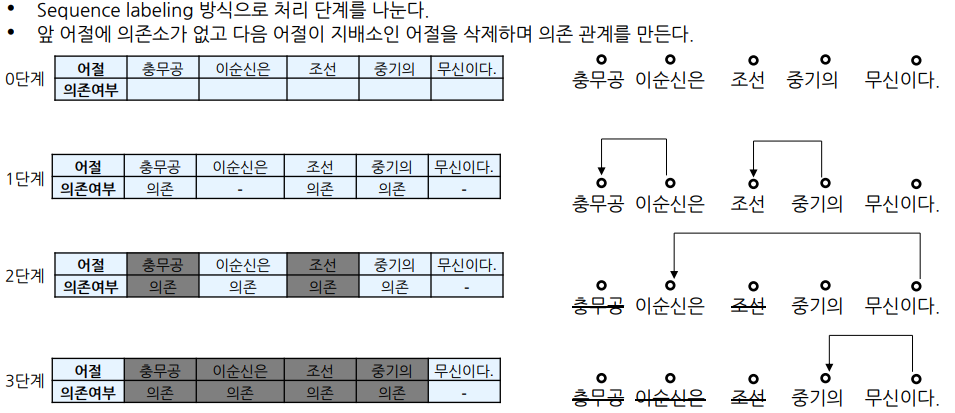
-
1단계에서 ‘충무공’, ‘조선’은 앞에 의존소가 없고 다음 어절은 지배소이므로 삭제
-
2단계에선 ‘이순신은’은 ‘무신이다’의 의존소이고 앞에 의존소가 없으므로 삭제
-
3단계에서 마지막 지배소 ‘무신이다’만 남고 삭제
어디에 쓰이는가?
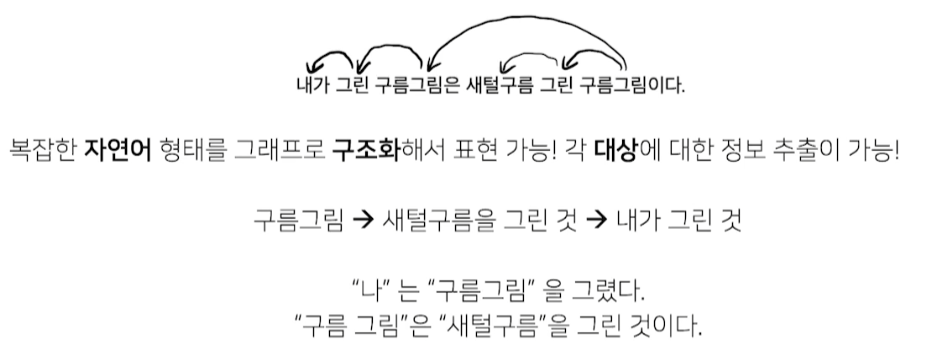
단일 문장 분류 task
문장 분류 task
-
주어진 문장이 어떤 종류의 범주에 속하는지 구분
-
감정분석
- 문장의 긍정, 부정, 중립 등 성향 분류 프로세스
-
주제 라벨링 (토픽 라벨링)
- 문장 내용을 이해하고 적절한 범주를 분류하는 프로세스
-
언어 감지
- 문장이 어떤 나라 언어인지 분류
-
의도 분류
-
문장이 가진 의도를 분류
-
챗봇에 사용
-
-
문장 분류를 위한 데이터
- Kor_hate, Kor_sarcasm, Kor_sae, …
단일 문장 분류 모델 학습
모델 구조도
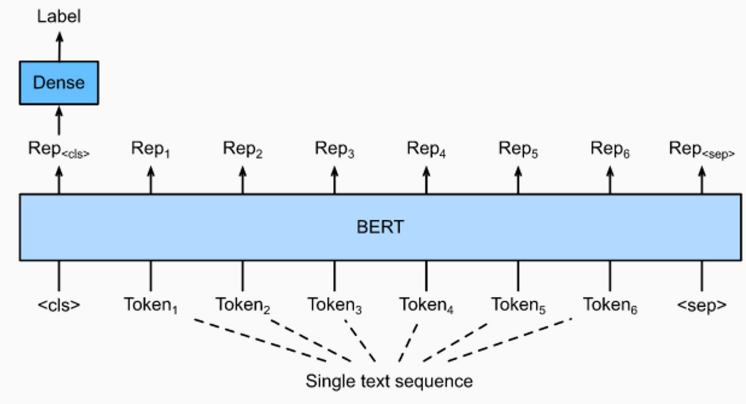
학습 과정
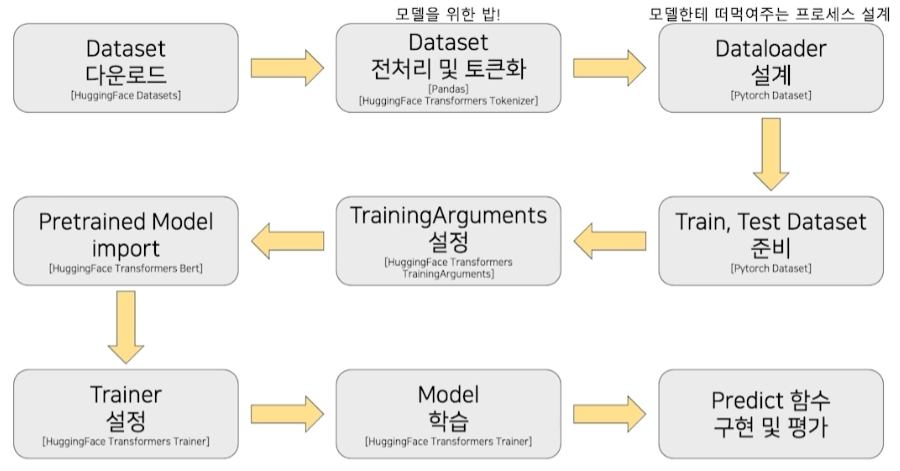
실습 - BERT를 활용한 단일 문장 분류
datasets
import datasets
# 사용가능한 dataset list 불러오기
dataset_list = datasets.list_datasets()
# dataset list 확인
for datas in dataset_list:
if 'ko' in datas:
print(datas)-
huggingFace에서 dataset 이름만 주면 dataset을 불러올 수 있도록 datasets 라이브러리 제공
-
실습에선 nsmc dataset 이용
dataset = datasets.load_dataset('nsmc') # nsmc, hate, sarcasm
train_data = pd.DataFrame({"document":dataset['train']['document'], "label":dataset['train']['label']})
test_data = pd.DataFrame({"document":dataset['test']['document'], "label":dataset['test']['label']})## Dataset 구조 ##
DatasetDict({
train: Dataset({
features: ['id', 'document', 'label'],
num_rows: 150000
})
test: Dataset({
features: ['id', 'document', 'label'],
num_rows: 50000
})
})-
dataset은 train, test로 나뉘며 feature 정보도 제공
-
train과 test dataset을 dataframe으로 생성
문장 길이 EDA
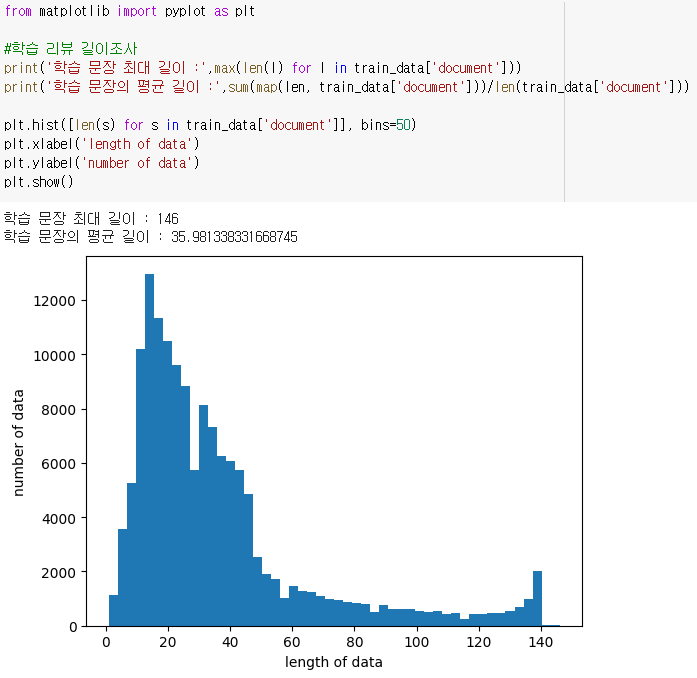
- imbalance 확인 가능
tokenizing
tokenized_train_sentences = tokenizer(
list(train_data['document']),
return_tensors="pt",
padding=True,
truncation=True,
add_special_tokens=True,
)- pre-trained tokenizer에 train data를 넣고 tokenizing
- tokenizer에 새로운 단어를 추가해 fine-tuning 처럼 다시 토크나이저를 학습하는 것이 아님
평가
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics
)
trainer.evaluate(eval_dataset=test_dataset)-
Trainer의 compute_metrics에 선언한 compute_metrics 함수를 넣으면,
trainer.evaluate이 실행될 때 compute_metrics 함수가 실행된다. -
원하는 메트릭을 return
training using torch

- transformers의 trainer말고 torch로도 똑같이 학습할 수 있음
Predict

- sentence를 input으로 받아 tokenizer에 tokenizing
- tokenized sentence를 model에 넣고 output 도출
-
nlp_sentence_classif = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, device=0)코드를 사용해도 된다.
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid