BERT 모델
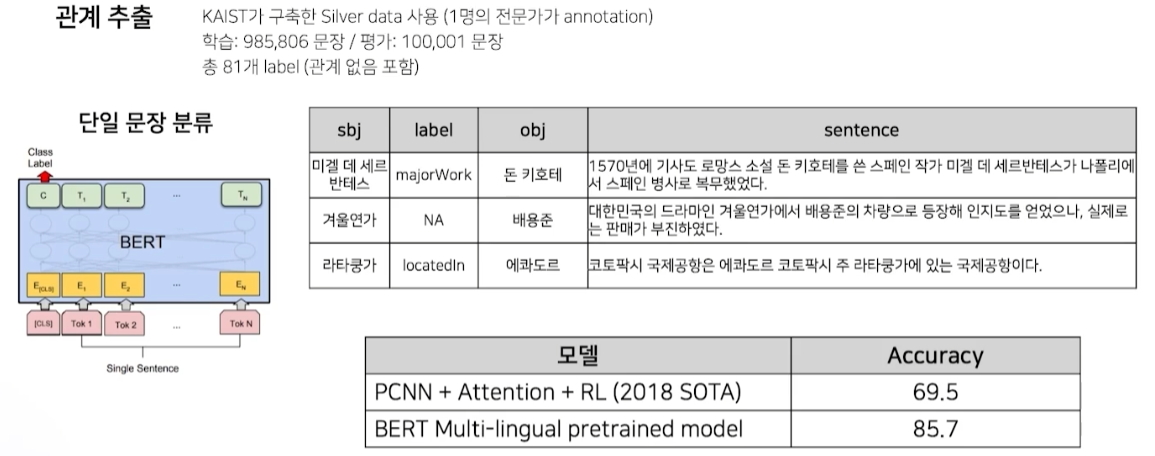
- sbj와 obj 사이의 관계를 추출하는 문제
한국어 BERT 모델
-
ETRI의 KoBERT Tokenizing
-
형태소 분석을 먼저 한 후 wordpiece 적용
-
높은 성능
-
-
Entity를 명시하고 Entity 임베딩을 추가하면 성능 향상
중요한 것은 개인 task에 맞게 tokenizer를 커스터마이징 하는 것
실습 - tokenizer

- attention_mask에서 pad 토큰은 0으로 표기

- tokenizer가 자동으로 [CLS], [SEP] token 부착
tokenizer.tokenize(text, add_special_token=False)로 하면 부착 X

- max_length & truncation
- max_length는 token의 최대 개수를 지정
truncation=True로 잘라냄- max_length는 token의 최대 개수이기 때문에 decode 결과 sequence 길이와는 무관
tokenizer 새로운 token 추가

- Unknown token이 많으면 해석이 원활히 되지 않음

- 이 때
tokenizer.add_tokens()로 새로운 단어를 추가할 수 있음 - UNK token이 나타나지 않음
special token 추가

- [SHKIM] 이라는 special token을 추가할 때,
tokenizer.add_special_tokens()- dict의 key는 “additional_special_tokens”가 되어야 함
- 총 7개의 새로운 token이 추가됐고, 추후 모델 resize를 위해 이 값을 알고 있어야 함
BERT tokenizer input
# Single segment input
single_seg_input = tokenizer("이순신은 조선 중기의 무신이다.")
# Multiple segment input
multi_seg_input = tokenizer("이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다.")
# ['[CLS]', '이', '##순', '##신', '##은', '조선', '중', '##기의', '무', '##신', '##이다', '.',
# '[SEP]', '그는', '임', '##진', '##왜', '##란', '##을', '승', '##리로', '이', '##끌', '##었다', '.', '[SEP]']- 문장 두 개를 넣으면 자동으로 [CLS], [SEP] token 추가
tokens = tokenizer(
["이순신은 조선 중기의 무신이다.", "그는 임진왜란을 승리로 이끌었다."],
padding=True # First sentence will have some PADDED tokens to match second sequence length
)- 배열 형태로 넣고
padding=True입력 시- 짧은 문장이 긴 문장 길이에 맞춰 자동으로 패딩
BERT model test
transformers의 pipeline

- mask 정보를 예측해 inference
- fill-mask가 아닌 다른 값을 넣어 task에 맞게 사용 가능
Token wise output vs Pooled output

- token wise output
- 13개의 token에 대한 output
- Pooled output
- [CLS] token output
- 13개 token output의 pooling된 결과
model resize

- 앞서 추가한 새로운 7개의 token에 맞게
model.resize_token_embeddings()수행
문장 유사도 측정

- cosine 유사도를 이용해 문장의 pooler_output 간 유사도를 구할 수 있음
- sent1과 sent4는 큰 관계가 없어 보이는데, 코사인 유사도가 높게 나옴
- 정확하다고 판단할 수 없음
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid