vocab_size = 100
max_len = len(max(data, key=len)) # 20
# valid_lens : padding 되기 전 문장들의 원래 길이 리스트
# 10개의 data를 하나의 batch로 사용하고 있음
batch = torch.LongTensor(data) # (B, L) = (10, 20)
batch_lens = torch.LongTensor(valid_lens) # (B) = (10)embedding_size = 256
embedding = nn.Embedding(vocab_size, embedding_size)
# d_w: embedding size
batch_emb = embedding(batch) # (B, L, d_w)-
word embedding을 위한 embedding layer
-
vocab size(100)을 embedding size(256)으로 transformation
-
따라서 batch_emb의 shape은 (10, 20, 256)이 된다.
-
RNN Structure in PyTorch


embedding_size = 256
hidden_size = 512 # RNN의 hidden size
num_layers = 1 # 쌓을 RNN layer의 개수
num_dirs = 1 # 1: 단방향 RNN, 2: 양방향 RNN
rnn = nn.RNN(
input_size=embedding_size, # embedding된 vocab
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True if num_dirs > 1 else False
)
# (num_layers * num_dirs, B, d_h)
h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size))
hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0) # (B, L, d_w) -> (L, B, d_w)-
RNN module 생성 시 input_size와 생성한 rnn에 넣는 input의 size는 다른 것임
-
RNN module에서는 input x의 feature, 즉 batch, sequence length를 제외한 단어의 dimension이 input_size로 들어감
-
생성한 모듈의 input에서는 sequence length, batch를 고려한 size를 넣음
-
PyTorch에서 다른 모델들은 batch_size가 맨 앞으로 들어감
-
RNN, LSTM module에선 sequence_length를 맨 앞으로 지정
-
이를 바꾸려면 RNN 생성 시
batch_first=True -
위 코드에선 transpose를 이용해 sequence length와 batch_size transpose
-
-
-
h_0은 초기 hidden state로, (D*num_layers, batch_size, hidden_size) 크기를 가짐
-
rnn layer의 개수만큼 hidden state input이 필요하며,
양방향일 경우 양쪽에서 hidden state input이 필요하므로 D*num_layers -
hidden state는 hidden dimension size이며, output을 얻고 싶다면 output layer에서
와 선형 결합을 통해 logit을 얻을 수 있음
-
print(hidden_states.shape) # (L, B, d_h)
print(h_n.shape) # (num_layers*num_dirs, B, d_h) = (1, B, d_h)
print(hidden_states[-1, :, :])
print(h_n)torch.Size([20, 10, 512])
torch.Size([1, 10, 512])
tensor([[ 0.7547, -0.4283, -0.2233, ..., -0.4451, 0.4492, 0.7862],
[-0.6019, 0.2133, -0.4292, ..., 0.1674, 0.1696, 0.3318],
[-0.6019, 0.2132, -0.4290, ..., 0.1672, 0.1698, 0.3318],
...,
[-0.6019, 0.2132, -0.4292, ..., 0.1674, 0.1696, 0.3318],
[-0.6019, 0.2133, -0.4292, ..., 0.1675, 0.1697, 0.3318],
[-0.5311, 0.2010, -0.3150, ..., 0.3855, 0.2739, 0.4209]],
grad_fn=<SliceBackward0>)
tensor([[[ 0.7547, -0.4283, -0.2233, ..., -0.4451, 0.4492, 0.7862],
[-0.6019, 0.2133, -0.4292, ..., 0.1674, 0.1696, 0.3318],
[-0.6019, 0.2132, -0.4290, ..., 0.1672, 0.1698, 0.3318],
...,
[-0.6019, 0.2132, -0.4292, ..., 0.1674, 0.1696, 0.3318],
[-0.6019, 0.2133, -0.4292, ..., 0.1675, 0.1697, 0.3318],
[-0.5311, 0.2010, -0.3150, ..., 0.3855, 0.2739, 0.4209]]],
grad_fn=<StackBackward0>)RNN에 batch data를 넣으면 아래와 같이 2가지 output을 얻음
-
hidden_states: 각 time step에 해당하는 hidden state들의 묶음- 각 time step을 거쳤으므로 크기가 (sequence_length, batch_size, hidden dim)
-
h_n: 모든 sequence를 거치고 나온 마지막 hidden state -
따라서 마지막 hidden state인 h_n은 hidden state들의 묶음인 hidden_states의 sequence length 차원의 맨 마지막이다.
- 위 결과에서 동일한 tensor임을 확인 가능
-
만약 num_layers가 1이 아닌 정수였다면, h_n의 가장 마지막은 num_layer의 가장 끝을 의미
num_classes = 2
classification_layer = nn.Linear(hidden_size, num_classes)
# C: number of classes
output = classification_layer(h_n.squeeze(0)) # (1, B, d_h) => (B, C)
print(output.shape) # torch.Size([10, 2])모든 token의 output을 구하는 것이 아닌, 맨 마지막 hidden state에 대해서만 output을 구함
-
e.g., 문장의 감정 분석 task
-
size는 (batch_size, classes probability vector)
-
output에 softmax를 적용하면 가장 확률이 높은 class로 분류
num_classes = 5
entity_layer = nn.Linear(hidden_size, num_classes)
# C: number of classes
output = entity_layer(hidden_states) # (L, B, d_h) => (L, B, C)
print(output.shape) # torch.Size([20, 10, 5])모든 token의 output을 구해 매 time step마다 output 계산
-
e.g., 문장 내 각 단어의 품사 태깅
-
size는 (sequence length, batch size, class probability vector)
-
output에 softmax를 적용하면 가장 확률이 높은 class로 분류
Hidden layer의 weight와 Hidden states를 혼동하지 말 것
PackedSequence
torch.sort()
batch_lens = torch.tensor([20, 5, 8, 10, 15, 18, 17, 6, 6, 18])
batch_lens.sort()
# torch.return_types.sort(
# values=tensor([ 5, 6, 6, 8, 10, 15, 17, 18, 18, 20]),
# indices=tensor([1, 7, 8, 2, 3, 4, 6, 5, 9, 0]))- sorting된 결과와 해당 index를 namedTuple 형태로 반환
packing
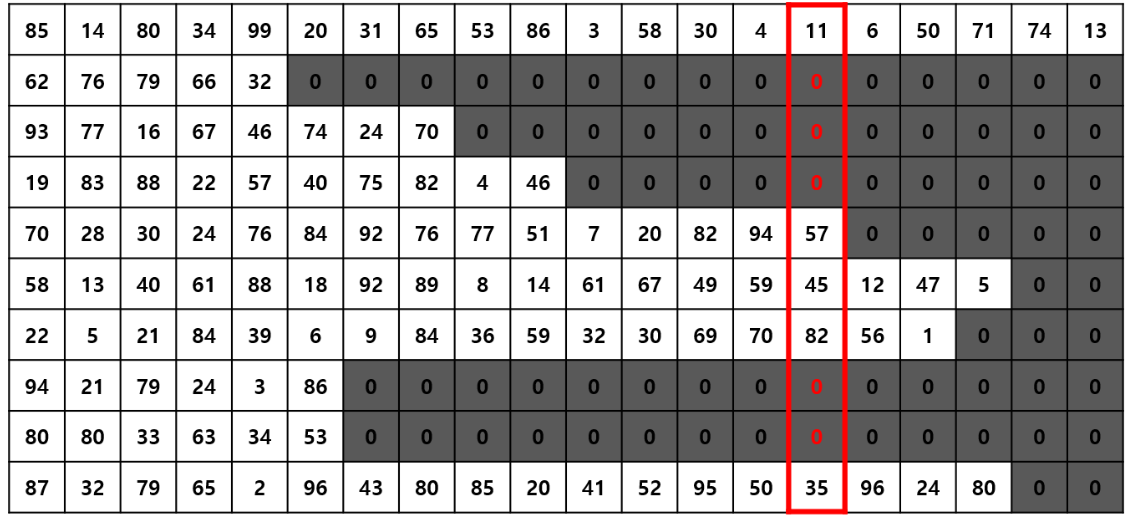
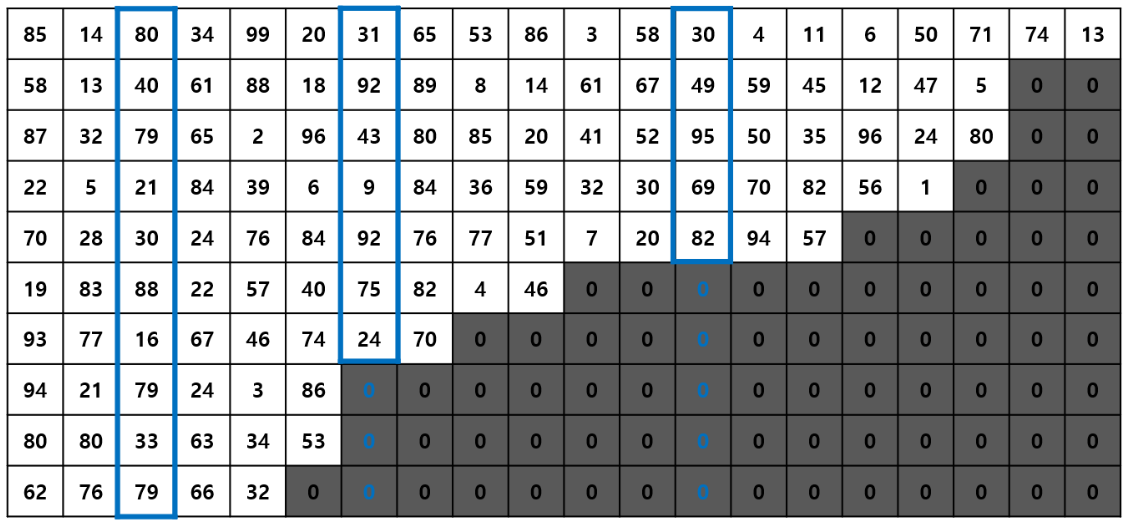
- 아래와 같이 sequence를 정렬해 불필요한 padding 연산을 줄임
-
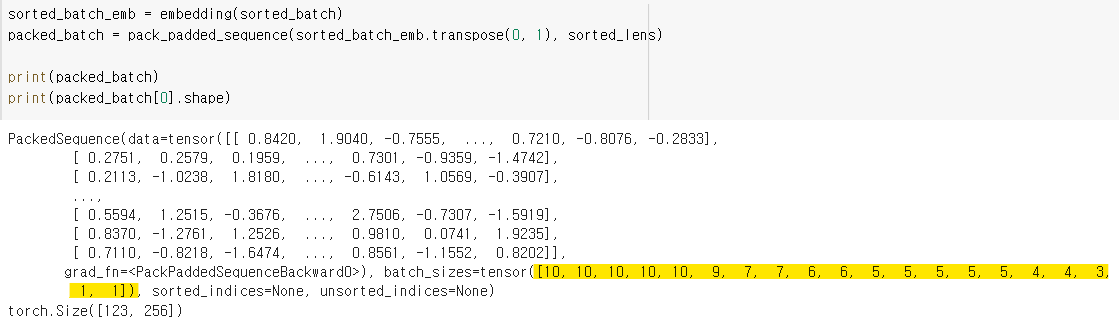
pack_padded_sequence(tensor, sequence length tensor)로 PackedSequence 생성 -
위 사진처럼 batch_sizes가 10 , 10, … , 1, 1이 되는 것을 확인 가능
-
PackedSequence는 tuple 형태로
(data, batch_sizes, sorted_indicies, unsorted_indices)포함 -
PackedSequence의 size가 (123, 256)
-
batch_sizes를 sum하면 123이 나온다.
-
sorted_batch_emb의 size는 (10, 20, 256)으로, (batch, sequence length, dim)이다.
-
이를 (batch_sizes의 총합, dim)으로 변환해서 계산
-

-
pack_padded_sequence size는 (123, )
-
element를 보면 85, 58, 87, …, 80, 74, 13으로 위 그림의 data를 세로로 가지고 와 flatten된 형식
-
data를 embedding해서 넣으면 size가 (123, embedding size=256) 이 되는 것

-
rnn 모듈에 넣은 결과값에서 마지막 hidden state(h_n)의 크기는 변함이 없음
-
packed_outputs는 hidden states의 묶음으로, shape이 (sequence length, batch_size, dimension)이 아닌 (batch_sizes sum, dimension)

- 다시 원래 sequence로 돌리기 위해
pad_packed_sequence이용
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
