task
src_data → trg_data
- 두 데이터는 sequence length는 다르고 batch_size는 같은 형태
trg_data는 <SOS>, <EOS> 토큰을 앞뒤로 넣음
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
)
self.output_layer = nn.Linear(hidden_size, vocab_size)
def forward(self, batch, hidden): # batch: (B), hidden: (1, B, d_h)
batch_emb = self.embedding(batch) # (B, d_w)
batch_emb = batch_emb.unsqueeze(0) # (1, B, d_w)
outputs, hidden = self.gru(batch_emb, hidden) # outputs: (1, B, d_h), hidden: (1, B, d_h)
# V: vocab size
outputs = self.output_layer(outputs) # (1, B, V)
return outputs.squeeze(0), hiddenoutputs, hidden = self.gru(batch_emb, hidden)
- shape :
- outputs: (1, B, d_h)
- hidden: (1, B, d_h)
gru의 outputs shape은 (sequence_length, batch, hidden dim)인데, 왜 여기선 1?
-
batch_emb = batch_emb.unsqueeze(0)-
batch_emb의 shape은 (B, word dim)
-
unsqueeze를 통해 (1, B, word dim)
-
batch의 모든 단어 token을 input으로 하는 것이 아닌, time step에 맞는 단어만 gru 통과
↓Reason
-
class Seq2seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src_batch, src_batch_lens, trg_batch, teacher_forcing_prob=0.5):
# src_batch: (B, S_L), src_batch_lens: (B), trg_batch: (B, T_L)
_, hidden = self.encoder(src_batch, src_batch_lens) # hidden: (1, B, d_h)
input_ids = trg_batch[:, 0]
# (B) 첫 번째 timestep은 start token id (=1)로만 구성됨
batch_size = src_batch.shape[0]
outputs = torch.zeros(trg_max_len, batch_size, vocab_size) # (T_L, B, V)
for t in range(1, trg_max_len):
# 매 timestep (t) 마다 해당 t의 target id (또는 이전 timestep (t-1)에서 예측된 id)를 입력으로 주고, 다음 단어를 예측하는 과정을 반복함.
decoder_outputs, hidden = self.decoder(input_ids, hidden)
# decoder_outputs: (B, V), hidden: (1, B, d_h)
outputs[t] = decoder_outputs
_, top_ids = torch.max(decoder_outputs, dim=-1) # top_ids: (B)
input_ids = trg_batch[:, t] if random.random() > teacher_forcing_prob else top_ids
# 사전에 정의한 teacher_forcing_prob에 따라 teacher_forcing을 하는 경우 target id를 입력으로 주고, 아닌 경우 이전 timestep에서 출력된 top_ids를 입력으로 줌.
return outputs_, hidden = self.encoder(src_batch, src_batch_lens)
- decoder의 첫 번째 hidden state는 encoder의 output hidden state
input_ids = trg_batch[:, 0]
- tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
- batch에서 0번째 time step 단어들만 입력
- decoder이기 때문에
<SOS>가 0번째 - batch 내 각 sequence의 time step번째 token들이 input이 됨
for t in range(1, trg_max_len):
- target maximum 길이만큼 time step 반복
teacher_forcing_prob=0.5에 따라 이전 time step output 또는 ground truth를 input
decoder_outputs, hidden = self.decoder(input_ids, hidden)
- input_ids(batch개의 time step번 째 단어 token)과 hidden(이전 time step hidden)을 decoder에 넣어 decoder_outputs(logit)과 현재 time step hidden state 얻음
- 이전에 initialize한 outputs에 decoder_outputs를 저장
_, top_ids = torch.max(decoder_outputs, dim=-1)
- top_ids는 decoder_outputs에서 확률이 가장 높은 단어 token이 batch_size개 있는 tensor
input_ids = trg_batch[:, t] if random.random() > teacher_forcing_prob else top_ids
- teacher forcing prob을 이용해 top_ids 또는 ground truth를 다음 time step input
⇒ 해당 과정을 target_length번 반복

-
현재 data의 size는 (21, 10, 100) = (
<SOS>를 제외한 sequence length, batch_size, vocab_size)- CrossEntropyLoss를 위해 size를 (210, 100)으로 convert
class DotAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, decoder_hidden, encoder_outputs): # decoder_hidden: (1, B, d_h), encoder_outputs: (S_L, B, d_h)
query = decoder_hidden.squeeze(0) # (B, d_h)
key = encoder_outputs.transpose(0, 1) # (B, S_L, d_h)
energy = torch.sum(torch.mul(key, query.unsqueeze(1)), dim=-1) # (B, S_L)
attn_scores = F.softmax(energy, dim=-1) # (B, S_L)
attn_values = torch.sum(torch.mul(encoder_outputs.transpose(0, 1), attn_scores.unsqueeze(2)), dim=1) # (B, d_h)
return attn_values, attn_scoresenergy = torch.sum(torch.mul(key, query.unsqueeze(1)), dim=-1) # (B, S_L)
- why sum?
Concat Attention
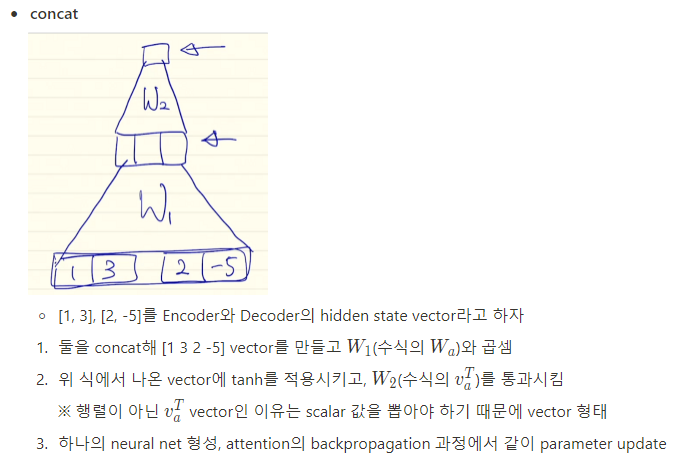
class ConcatAttention(nn.Module):
def __init__(self):
super().__init__()
self.w = nn.Linear(2*hidden_size, hidden_size, bias=False)
self.v = nn.Linear(hidden_size, 1, bias=False)
def forward(self, decoder_hidden, encoder_outputs): # (1, B, d_h), (S_L, B, d_h)
src_max_len = encoder_outputs.shape[0]
decoder_hidden = decoder_hidden.transpose(0, 1).repeat(1, src_max_len, 1) # (B, S_L, d_h)
encoder_outputs = encoder_outputs.transpose(0, 1) # (B, S_L, d_h)
concat_hiddens = torch.cat((decoder_hidden, encoder_outputs), dim=2) # (B, S_L, 2d_h)
energy = torch.tanh(self.w(concat_hiddens)) # (B, S_L, d_h)
attn_scores = F.softmax(self.v(energy), dim=1) # (B, S_L, 1)
attn_values = torch.sum(torch.mul(encoder_outputs, attn_scores), dim=1) # (B, d_h)
return attn_values, attn_scores- 수식과 동일하게 구현
repeat?x = torch.tensor([1, 2, 3]) x.repeat(4, 2) # tensor([[ 1, 2, 3, 1, 2, 3], # [ 1, 2, 3, 1, 2, 3], # [ 1, 2, 3, 1, 2, 3], # [ 1, 2, 3, 1, 2, 3]]) x.repeat(4, 2, 1).size() # torch.Size([4, 2, 3])- repeat(4, 2)는 dim 0 방향으로 4번, dim 1 방향으로 2번 반복해 tensor 확장
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
