Greedy decoding
sequence 전체 문장의 확률을 보는 것이 아닌, 매 time step에서 가장 확률이 높은 것을 선택
만약 단어를 잘못 예측했더라도, 뒤로 돌아갈 수 없음
Exhaustive search
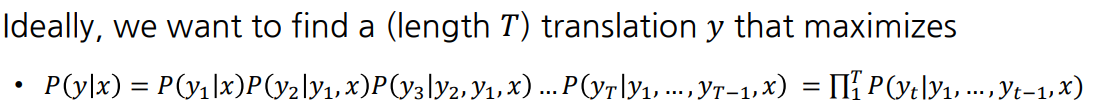
- 이상적으로는, i번째 time step output word 에 대해 모든 상황을 고려하면 최적의 output
- 시간, 연산량이 기하급수적으로 증가해 불가능
Beam search
매 time step마다 하나의 단어를 고르는 greedy decoding과,
매 time step마다 가능한 모든 단어의 조합을 고려하는 exhaustive search 사이의 차선책
-
decoder의 매 time step마다 k개의 가능한 가지수를 고려해 최종 k개 candidates에서 선택
-
k개의 경우의 수를 hypothesis라고 함
-
k는 beam size라고 하며, 보통 5~10
-
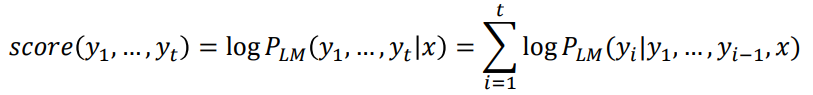
-
-
단어를 하나씩 생성하며 그 때의 확률값을 순차적으로 곱셈
-
해당 식을 최대화하는 것이 목표
-
-
log를 적용해 곱셈을 덧셈으로 바꿈
- log는 단조증가함수임으로 최대일 때 log값도 최대
-
매 time step마다 score가 가장 높은 k개의 candidate을 고려하고 추적
Example
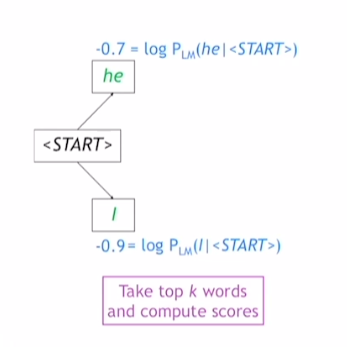
beam size = 2
-
vocab에 정의된 단어 상 확률 분포에서 가장 확률값이 높은 두 단어를 추출
-
만약 greedy decoding이었다면 하나의 값을 뽑아냄
-
log를 취한 값이 음수임을 확인할 수 있는데,
이는 확률이 항상 0 ~ 1 사이값을 가지기 때문
-
-
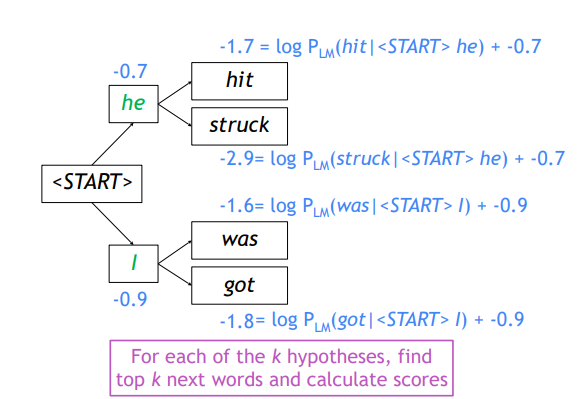
두 경우에 대해 각각 k개의 큰 확률값의 단어를 뽑아냄
-
가설은 총 개
-
log에 의해 곱셈이 덧셈 연산이 되며 각각의 총 확률값을 얻을 수 있음
-
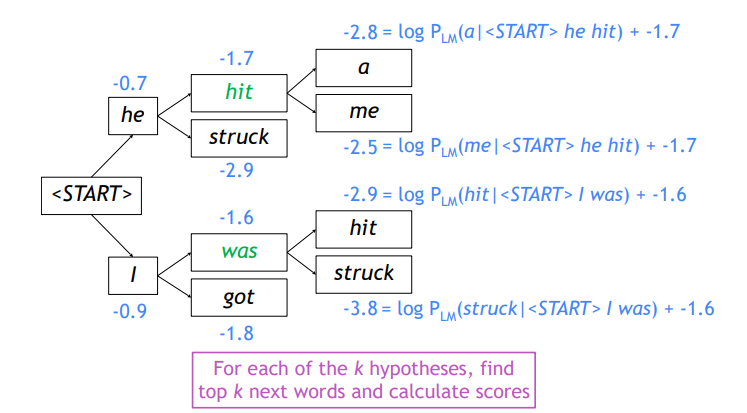
-
=4개의 candidates에서 가장 값이 큰 he hit, I was만을 뽑음
- 선정된 candidates에서 다시 각각 k개만큼 candidate 선정
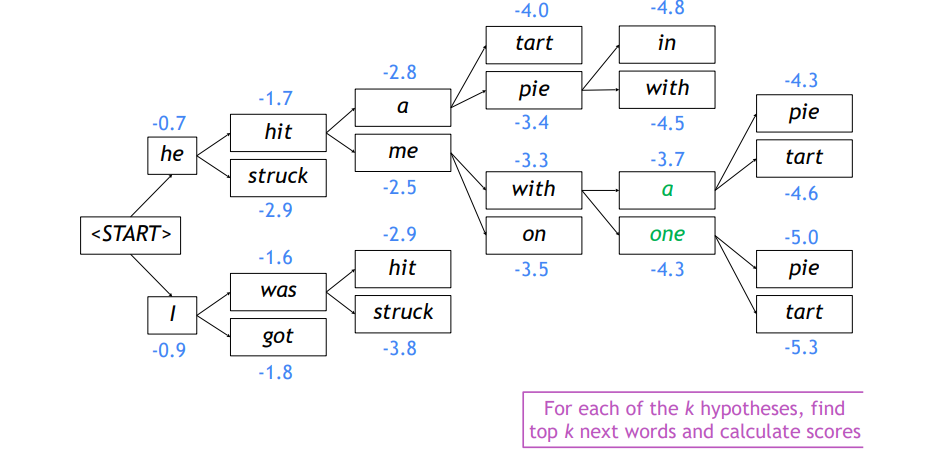
- 해당 과정 반복해 decoding 완료
Stopping criterion
greedy decoding에선 <EOS> 만나면 decoding 종료
beam search decoding에선 다른 time steps에서 <EOS> 생성
-
어떤 가설이
<EOS>token을 생성했으면, 해당 가설은 decoding 완료 -
완료된 가설은 어딘가에 저장하고 남은 끝나지 않은 가설은 계속 진행
-
유저가 최대 time steps T를 정하거나, 저장된 가설의 최대 개수 n을 정해서 종료시킴
Finishing up
최종적으로 가설 리스트를 얻게 됨
- 그 중에서 값이 가장 높은 것 한 개를 뽑음
가설의 sequence 길이가 다르다면?
-
상대적으로 짧은 sequence가 joint probability값이 높을 것임
-
이를 Normalize하기 위해 각 hypothesis sequence length를 나눠줌
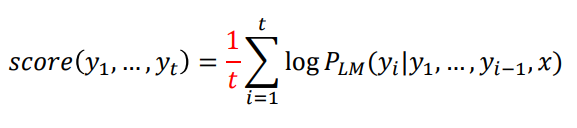
BLEU Score
생성 모델의 정확도를 결정하는 척도
Precision and Recall

-
precision (정밀도) : 맞힌 단어 개수 / 예측 문장 길이
-
recall (재현율) : 맞힌 단어 개수 / ground truth 길이
-
F-measure
- 서로 다른 기준을 갖는 두 precision, recall을 가지고 조화평균
※ 평균에는 대표적으로 산술평균, 기하평균, 조화평균이 있음
- 서로 다른 기준을 갖는 두 precision, recall을 가지고 조화평균
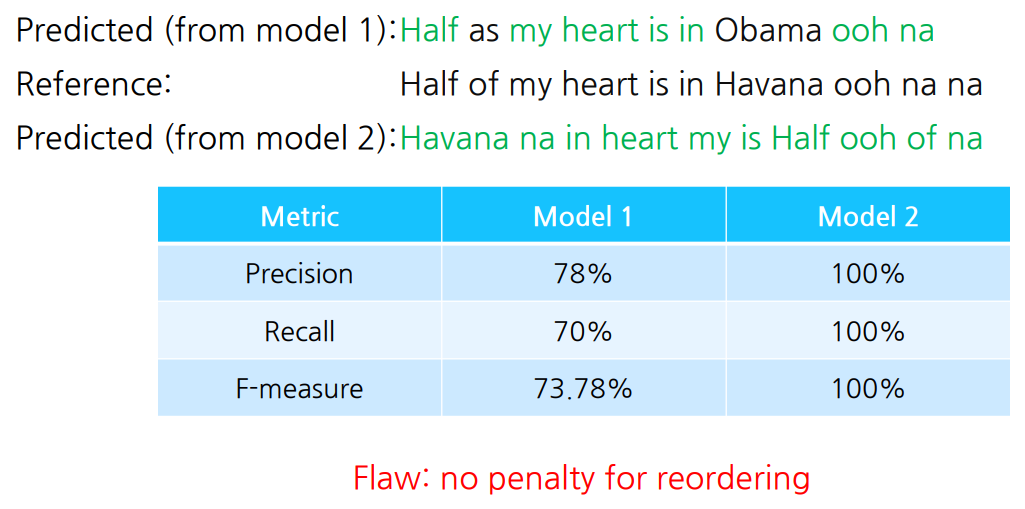
-
Predicted_2의 precision, recall, f-measure 모두 100이 나옴
-
순서에 penalty가 없음
BLEU Score
연속된 n개의 단어 phrase(N-gram)가 얼마나 ground truth와 겹치는지 반영
- four-gram까지 계산
recall은 무시하고 precision만 사용
-
recall은 ground truth에서 빠짐없이 하나하나 다 번역을 했는가에 집중
-
‘I love you so much’ → ‘나는 너를 많이 사랑해’ 번역에서
so에 해당하는 ‘정말’을 생략해도 어느정도 해석에 무리가 없음 -
따라서 recall 보다는 결과값에 치중한 precision을 사용
-

-
1-gram ~ 4-gram까지 계산해 기하평균 사용
-
다 곱해서 4중근
-
조화평균은 작은 값에 큰 가중치를 부여하는 특성이 있어 기하평균 사용
-
0 ~ 100 사이 값을 가짐
-
-
brevity penalty
-
만약 ground truth의 길이가 prediction 길이보다 작으면 min값을 적용해 1로 계산
-
ground truth보다 길이가 작게 예측되면 그 값만큼 penalty 부여
-
recall의 최대값을 의미하기도 함
-

-
1-gram
- reference의 각 단어와 predicted의 각 단어를 비교해 precision 계산
-
2-gram
-
문장 내 연속된 두 개의 단어를 묶음
-
Predicted_1에선 (Half, as), (as, my), (my, heart) ··· (Obama, ooh), (ooh, na) 총 8개
-
reference에선 (Half, of), (of, my), (my, heart) ··· (ooh, na), (na, na) 총 9개
-
precision이므로 분모에 predicted 단어 쌍 개수가 들어감
-
-
-
3-gram
-
문장 내 연속된 세 개의 단어를 묶음
-
Predicted_1에선 (Half, as, my), (as, my, heart) ··· (Obama, ooh, na) 총 7개
-
reference에선 (Half, of, my), (of, my, heart) ··· (ooh, na, na) 총 8개
-
-
-
4-gram까지 계산해서 모든 precision을 곱한 뒤, 사중근을 취해줌
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
