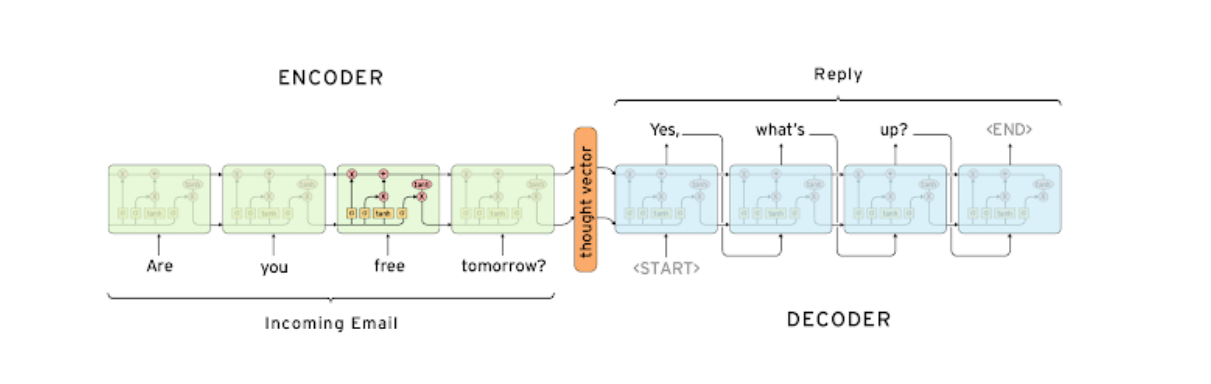
Seq2Seq
RNN의 many-to-many에 해당
-
입력 문장은 Encoder에서, 출력 문장은 Decoder로 처리
-
Encoder의 최종 output(hidden state vector)이 Decoder의 input hidden state vector
-
Decoder은
<SOS>token을 받아 문장의 처음을 시작<EOS>token을 출력하면 문장의 끝을 알림
-
LSTM이 long term dependency를 해결했다 하더라도, sequence가 길어지면 초반 data의 정보는 변질되거나 소실되기 쉬움
-
또한 긴 sequence를 정해진 차원의 context vector로 압축하는 것도 소실 문제가 있음
⇒ Attention 이용
Attention
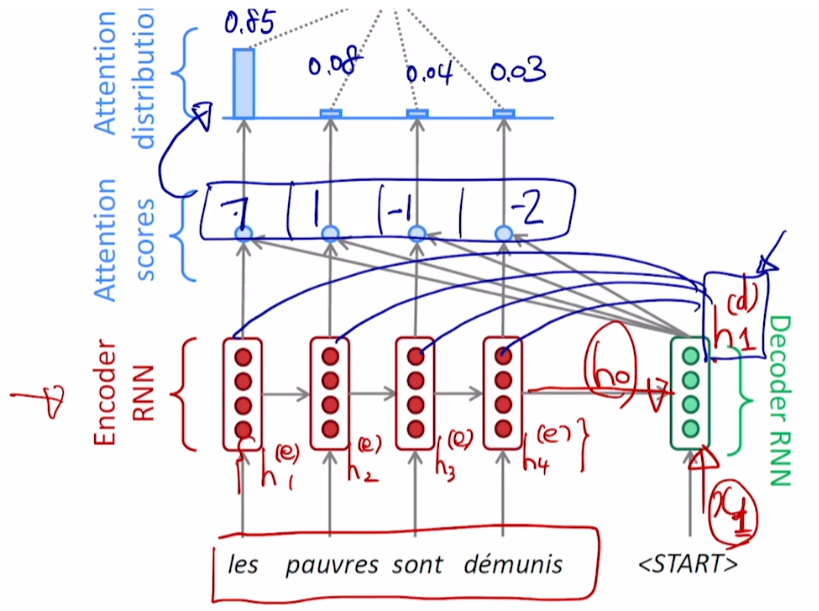
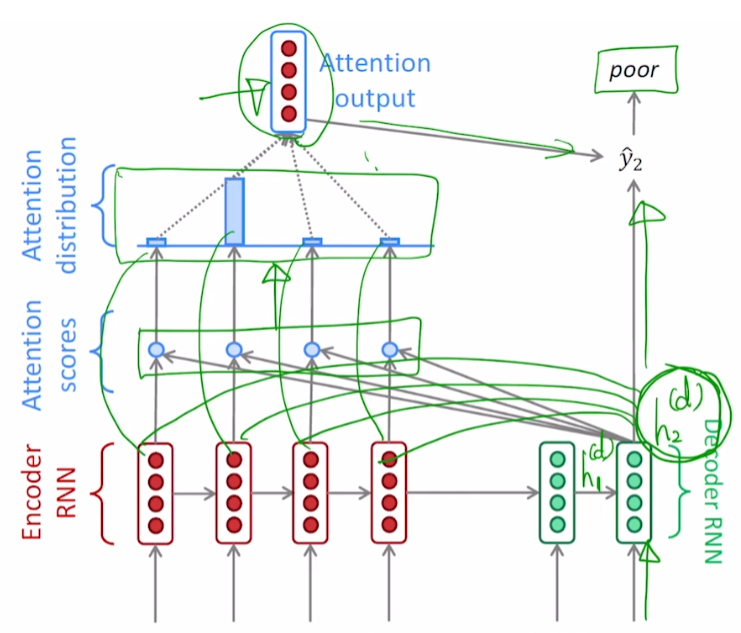
Decoder의 첫 번째 hidden state vector 와의 연산을 살펴보자
-
Encoder에서 각 token의 hidden state vector 생성
-
마지막 time step의 Encoder hidden state vector가 Decoder의 첫 번째 입력으로 들어감
-
Decoder의 첫 번째 input 과 연산을 거쳐 Decoder의 첫 번째 hidden state vector
-
이 모든 Encoder hidden state vector 와 내적을 거침
-
두 hidden state vector 내적에 기반한 유사도를 구함
-
예시로 7, 1, -1, 2라고 가정
-
해당 값들을 Attention Scores라고 칭함
-
-
Attention Scores를 softmax 함수를 적용시켜 Attention Distribution을 구함
- 예시로 0.85, 0.08, 0.04, 0.03이라고 가정
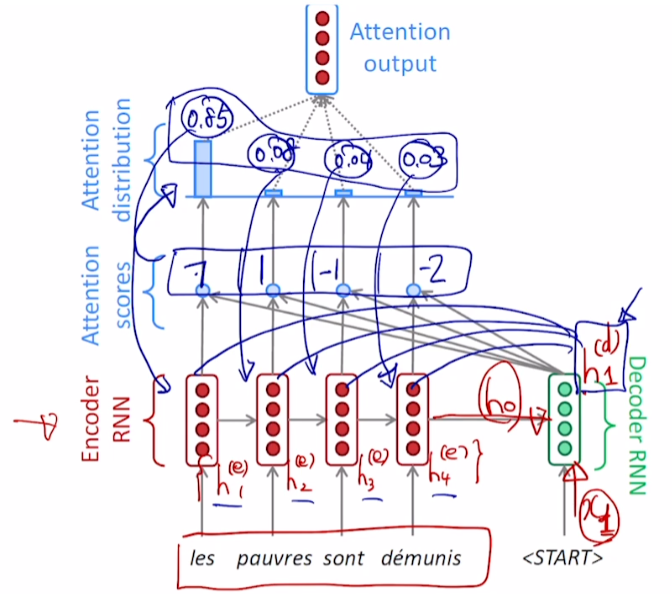
- 와 가중합을 구해 Attention Output을 구함 (= context vector)
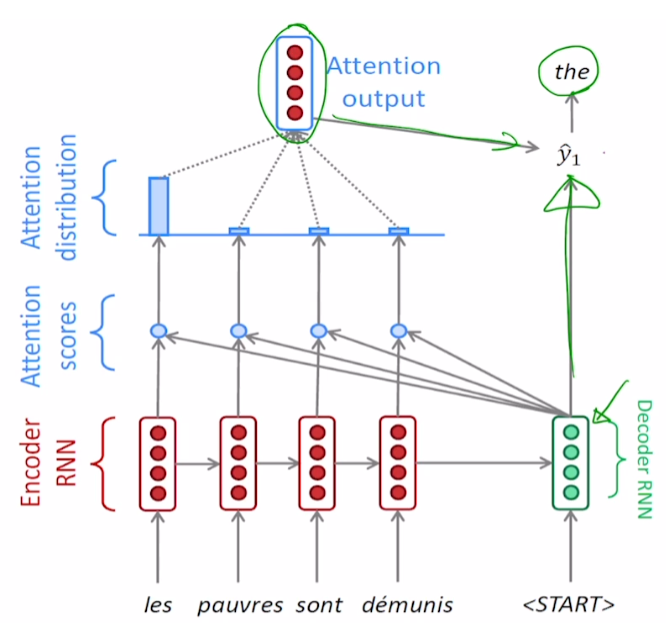
7. Attention Output과 Decoder hidden state vector가 concat되어 output layer를 거쳐 time step의 output을 뽑아냄
-
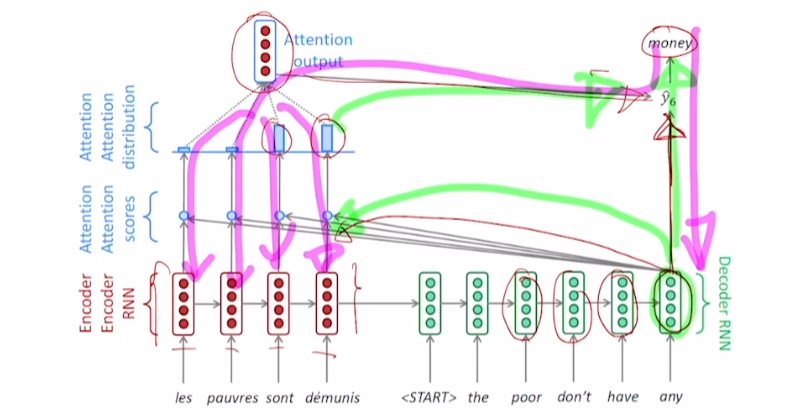
와 2번째 time step의 input 와의 연산을 통해 계산
-
앞선 과정과 동일하게 반복해 output 계산
-
같은 과정을 반복해
<EOS>token이 나올 때까지 생성 과정 수행
Decoder hidden state vector의 역할
output layer의 입력으로 사용됨과 동시에,
각 Encoder vector들 중 어떤 vector를 중점적으로 반영할지 결정
-
초록색이 순전파, 분홍색이 역전파 과정
- output 단어를 예측하고, 필요한 encoder 정보를 선택하도록 학습 진행
-
Decoder은 time step마다 입력으로 ground truth를 받고 있음
-
전 단계에서 예측을 잘못했다 하더라도, 다음 단계에서 올바른 단어를 입력으로 넣음
-
e.g., 첫 단어가 the가 아닌 A가 나와도, 다음 time step의 input은 a가 아닌 the
⇒ Teacher Forcing -
추론 과정에선 ground truth가 아닌 이전 time step의 output이 다음 time step의 input
- Teacher forcing이 아닌 방식을 inference에 활용
-
학습을 빠르고 용이하게 하기 위해 teacher forcing 활용
-
처음엔 teacher forcing으로 학습을 진행하다, 모델 예측 정확도가 높아지면 사용하지 않는 방법도 존재
-
Different Attention Mechanism
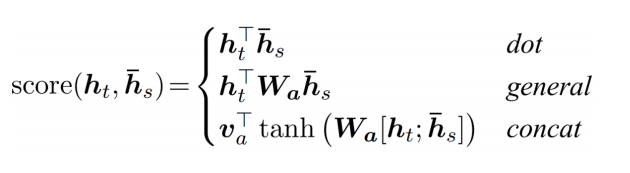
dot : 일반적인 내적
general
-
** 에서 는 학습 가능한 가중치 행렬
-
가중치 행렬을 학습시킴으로써 일반화
concat
-
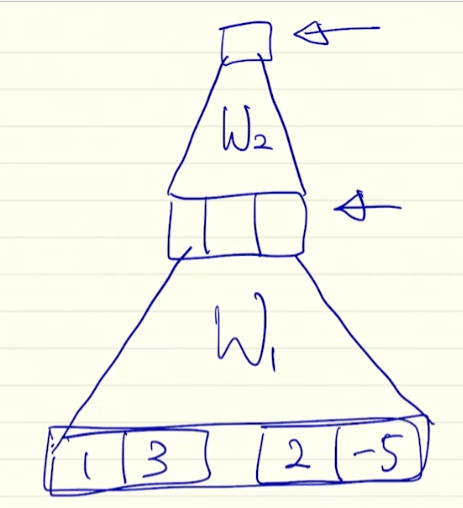
[1, 3], [2, -5]를 Encoder와 Decoder의 hidden state vector라고 하자
-
둘을 concat해 [1 3 2 -5] vector를 만들고 (수식의 )와 곱셈
-
위 식에서 나온 vector에 tanh를 적용시키고, (수식의 )를 통과시킴
※ 행렬이 아닌 vector인 이유는 scalar 값을 뽑아야 하기 때문에 vector 형태 -
하나의 neural net 형성, attention의 backpropagation 과정에서 같이 parameter update
-
Attention 장점
기계 번역 task에서 성능을 월등히 올림
bottleneck 문제 해결
decoder가 encoder의 어떤 단어에 집중했는지 알 수 있음
gradient vanish 문제 해결
- 역전파 과정에서 멀리 있는 data도 빠르고 변질 없이 이동 가능
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
