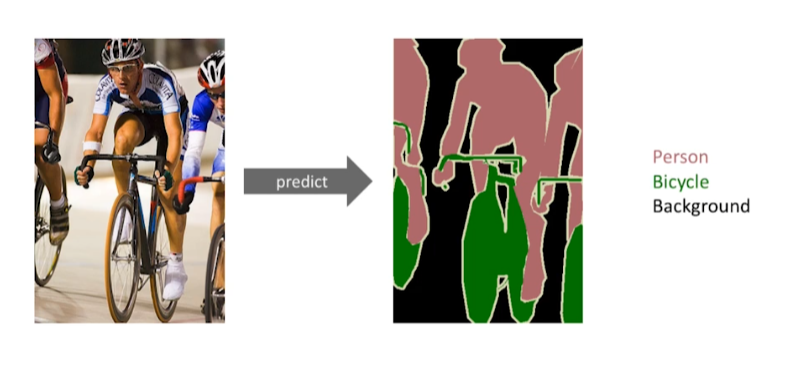
Semantic Segmentation
이미지의 모든 픽셀이 어떤 분류에 속하는지 판단
Fully Convolutional Network
- Dense layer를 없애고 convolution layer만 사용
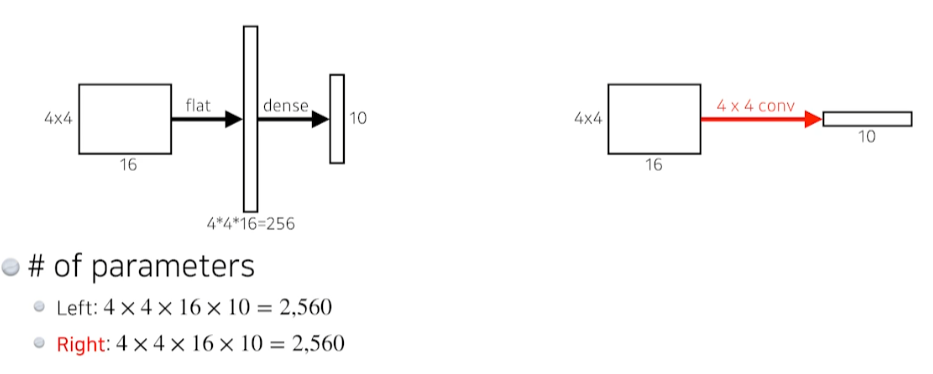
- input size와 동일한 크기의 convolution을 이용해 flatten 시킴
Convolutionalization
- 이미지가 커지면 fully convolutional network를 이용해(convolutionalzation) 단순 classification 뿐만 아니라 semantic segmentation이 가능
- coarse(드문드문한) heatmap을 얻을 수 있음
- output dimension이 줄어들어 원래의 dense pixel로 늘리는 과정이 필요
Deconvolution (convolution transpose)
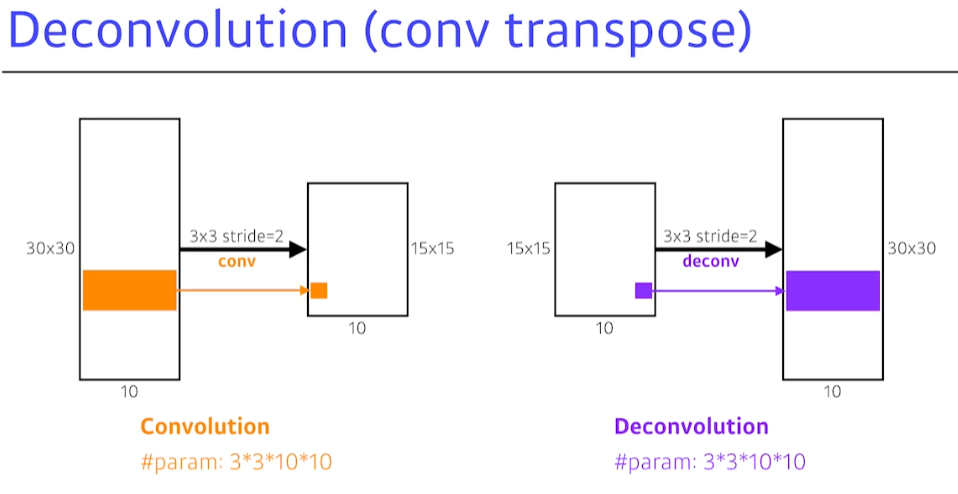
- 엄밀히 convolution의 역은 아니지만, parameter의 수와 in/output size 관점에선 역임
Detection
→ 물체의 위치를 bounding box로 뽑아냄
-
R-CNN : AlexNet을 2000번 수행해서 feature map extract
-
SPPNet : CNN을 1번 수행
-
Fast R-CNN : SPPNet과 유사
-
Faster R-CNN : bounding box를 뽑는 방법을 network 학습
-
Region proposal : bounding box에 물체가 있을 것 같음을 판단
Region proposal Network
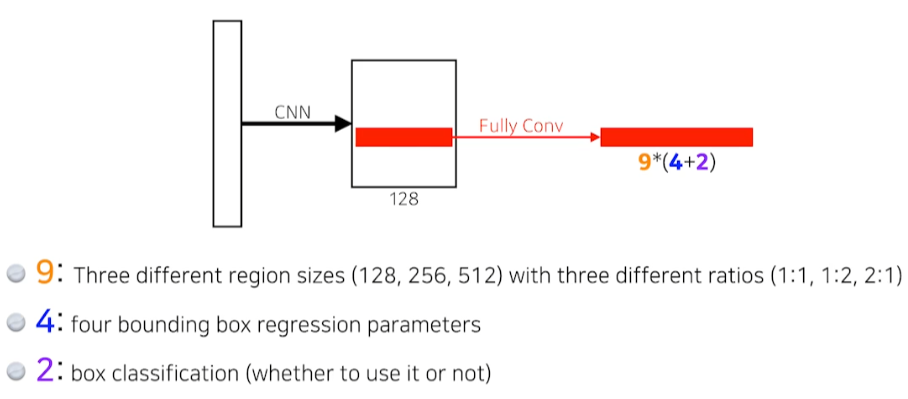
- 해당 영역에서 어떤 bounding box를 사용할 것인지, 안 할 것인지를 판단
YOLO
→ bounding box 추출과 class 예측을 동시에 해 매우 빠름

- image안에 내가 찾고 싶은 물체의 중앙이 해당 grid안에 들어가면, 그 grid cell이 해당 물체에 대한 bounding box와 물체가 무엇인지 같이 예측

- 각 cell은 B개의 bounding box를 예측
- B개의 bounding box의 x, y, width, height와 confidence(쓸모있는지, 없는지)를 예측
- B개의 bounding box의 x, y, width, height와 confidence(쓸모있는지, 없는지)를 예측

- 동시에 각각의 grid cell의 중점에 속하는 object가 어떤 class인지 예측
- Faster-CNN에서는 bounding box를 찾은 후 network에 넣어 무엇인지 예측
- Faster-CNN에서는 bounding box를 찾은 후 network에 넣어 무엇인지 예측

- 각각의 channel에 맞는 정보가 끼워 들어갈 수 있도록 학습이 됨
※ 모든 이미지의 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid