Greedy Search
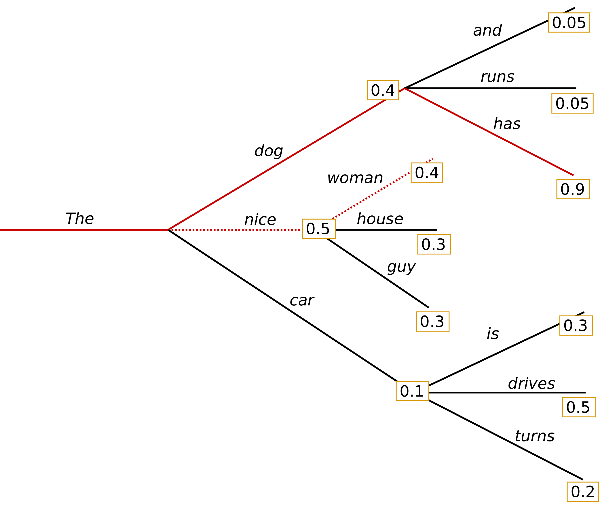
- 가장 높은 확률의 다음 단어 선택

- 그냥 generate 함수를 사용하면 greedy search
Output:
----------------------------------------------------------------------------------------------------
이순신은 조선 중기의 무신이다.</s><s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s
><s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s>
<s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s>
<s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s>
<s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s>
<s> 이 목록은 해당 앨범의 부클릿에서 발췌하였다.</s><s> 이 목록은 해당 앨범의 부클릿-
결과를 보면 무한 반복되는 양상
-
토큰 다음에 오는 가장 높은 확률의 토큰이 고정적이라 해당 문제 발생
Beam Search
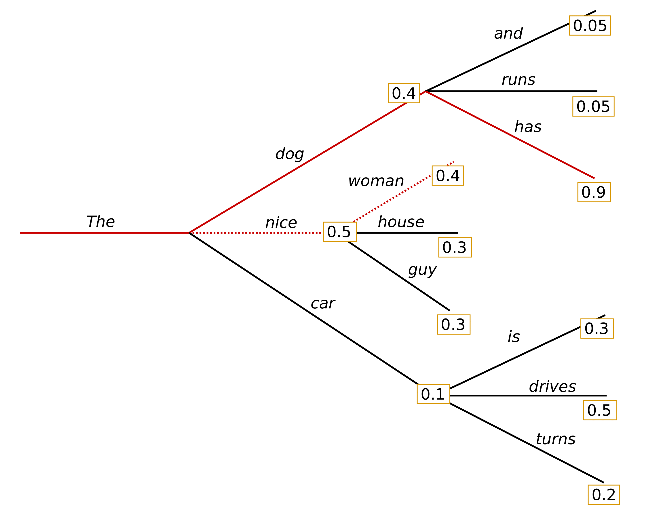
-
그 때 가장 높은 확률이 아닌 전체 확률을 따짐
-
다른 길을 파악해야 돼서 inference 시간이 오래 걸리게 됨

- generate에 num_beams 추가
Output:
----------------------------------------------------------------------------------------------------
이순신은 조선 중기의 무신이다.</s><s> 그 후, 그 후, 그 후, 그 후, 그 후, 그 후,
그 후, 그 후, 그 후, 그 후, 그 후, 그 후, 그 후, 그 후- 반복 단어들이 나타남 → n-gram penalty 적용
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2, # 2-gram이 두 번 나타나는 것을 방지
early_stopping=True
)-
n-gram penalty는 신중히 사용해야 함
- 고유명사같은 단어가 여러 번 나타나는 것이 방지될 때가 있음
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5, # 5개의 sequence 반환
early_stopping=True
)- 사용자가 5개 중 원하는 문장을 선택 가능
Sampling
완벽한 문장을 생성하려고 하면 똑같은 문장만 생성이 될 것임
노이즈 추가를 위해 단어를 무작위로 선택
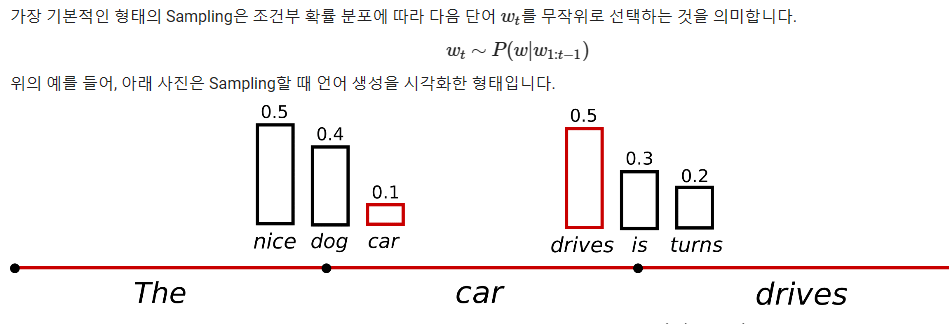
sample_output = model.generate(
input_ids,
do_sample=True, # 완전 random sampling
max_length=50,
top_k=0 # w/o top_k 추출
)-
top_k는 가장 높은 확률 k개 중 랜덤으로 추출
- 0이면 모든 단어에서 랜덤 추출
temperature
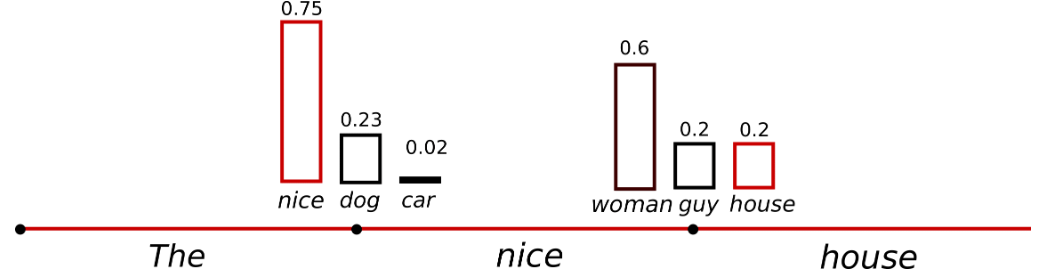
- 높은 확률의 단어는 높은 확률로 선택되고, 낮은 확률의 단어는 낮은 확률로 선택되게 조정
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)Output:
----------------------------------------------------------------------------------------------------
이순신은 조선 중기의 무신이다.</s>
<s> 이에 대해 일본 내 시민단체인 일본시민연맹(RSO)은 '한국인을 모욕하는 행위'라고 비난하였다.</s>
<s> 일본 외무성은 "일본의 정상적인 외교 활동이며 한일 관계를 악화시키는 것을- 꽤 그럴듯 함
Top-K sampling
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)- top_k 추가
Top-p sampling
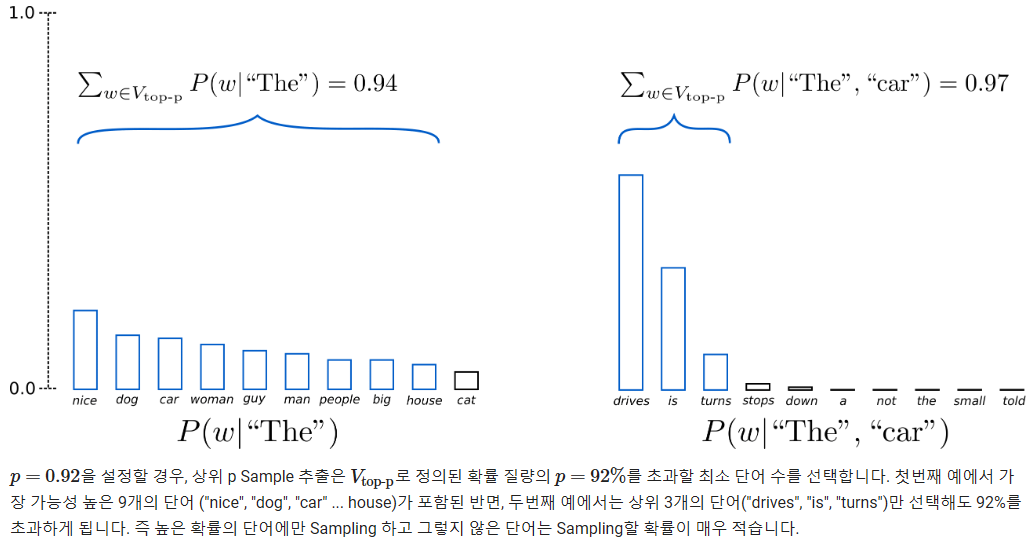
- 누적 확률이 p 이상인 단어만 채택
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)-
top_k와 top_p 같이 사용 가능
-
매우 낮은 순위의 단어를 피하면서도 일부 동적 선택을 허용
-
top_k = 0으로 하면 top_p만 적용
-
실습 - Zero shot & Few shot

-
eos_token_id를 명시하면 early_stopping이 가능해짐
- 토큰을 만나면 생성 stop

- one-shot learning으로 감정 분류
실습 - KoGPT2 기반 챗봇
tokenizer
tokenizer.enable_padding(pad_id=pad_id, pad_token="<pad>")
tokenizer.enable_truncation(max_length=128)- padding과 truncation을 true로 해주는 과정
generate
bad_words_ids=[[unk]]
-
리스트 안에 단어가 나오면 다른 단어를 고르도록 설정
- unknown 토큰 출현 방지
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid