BERT 이후 Language Model
BERT는 [MASK] token을 예측하는 task로, token 사이의 관계 학습이 불가능
- Embedding length의 한계로 semgent간 관계 학습 불가능
GPT-2는 단일 방향성으로 학습
→ XLNet 등장
XLNet
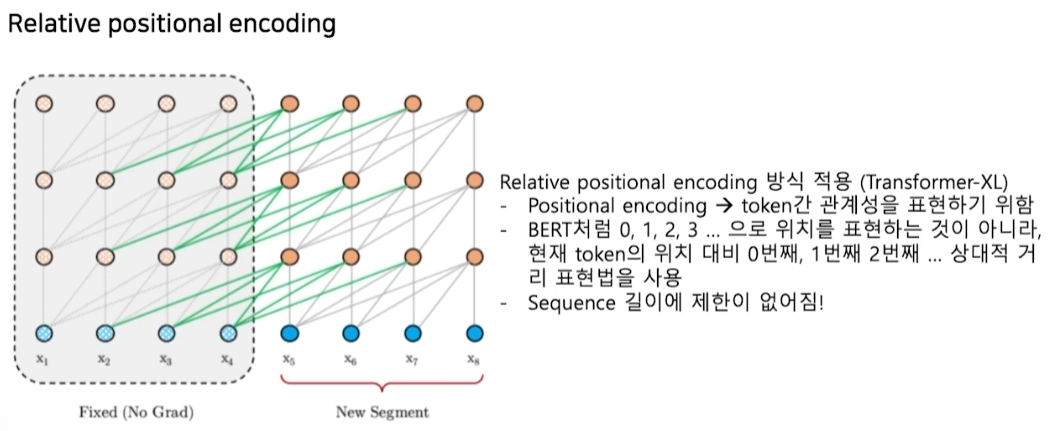
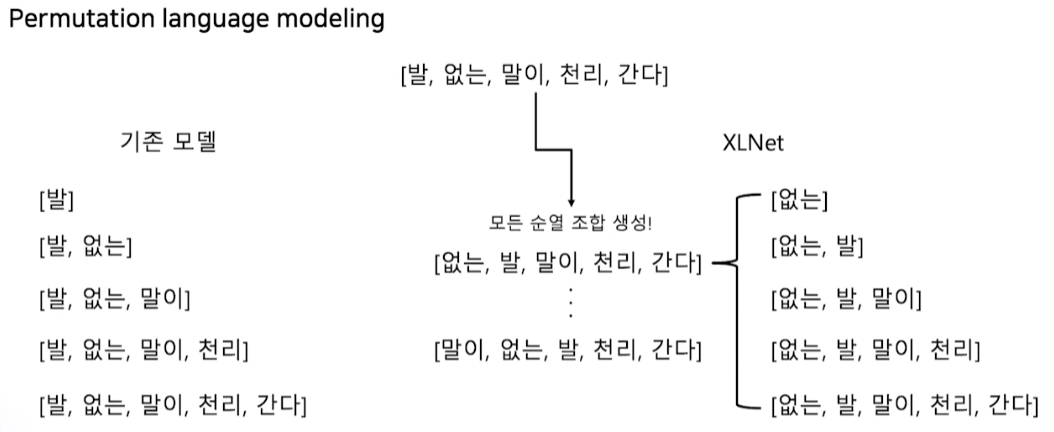
- 문장을 섞기 때문에 단방향 문제 해결
RoBERTa
BERT 구조에서 학습 방법을 다르게
-
NSP 제거
- NSP가 너무 쉬운 문제라 성능 하락 야기
-
longer sentence 추가
-
Dynamic masking
- 똑같은 텍스트 데이터에 대해 masking을 다르게 10번 적용해 학습
BART
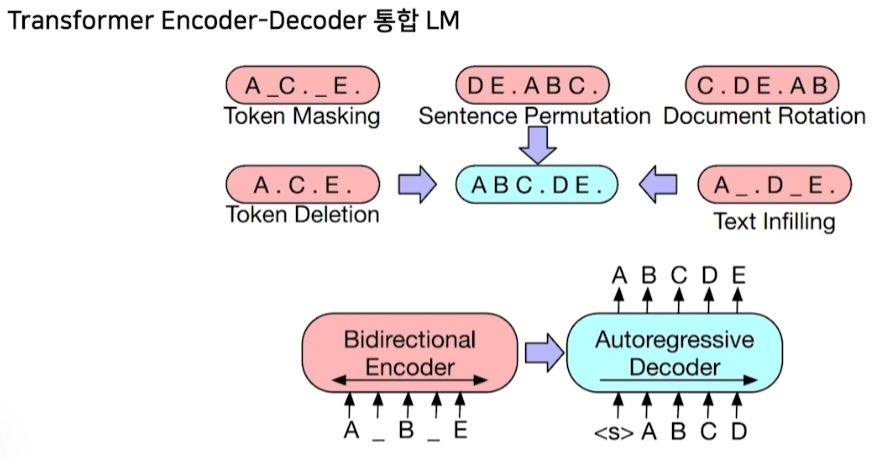
- 복잡하고 어려운 task를 한 번에 맞출 수 있도록 학습
T-5
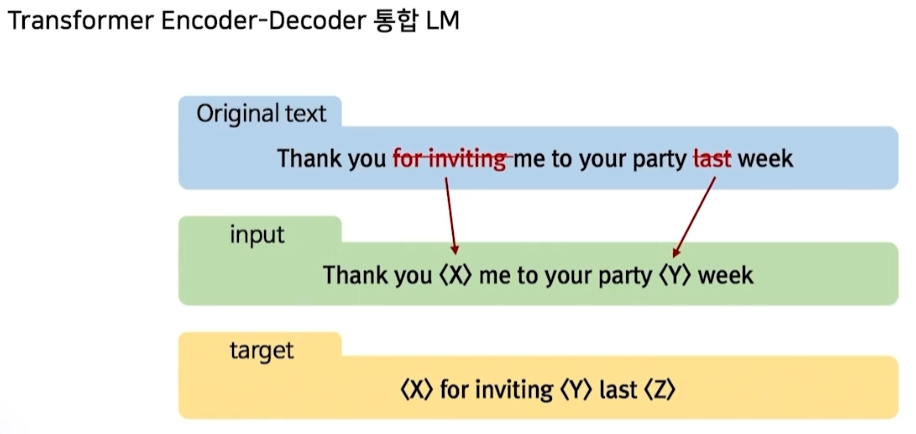
-
여러 어절을 Mask token으로 치환
-
여러 문장을 동시에 복원하도록 학습
Meena
대화 모델을 위한 LM
챗봇 평가를 위한 새로운 Metric인 SSA를 제시
-
SSA (Sensibleness and Specificity Average)
-
Sensibleness : 진행 중인 대화에 가장 적절한 답변을 했는가에 대한 점수
-
Specificity : 얼마나 구체적으로 답변을 했는가에 대한 점수
-
Controllable LM
Plug and Play Language Model (PPLM)
-
일반적인 LM은 다음 단어의 등장 확률분포를 보고 선택
-
PPLM은 내가 원하는 단어들의 확률이 최대가 되도록 이전 vector 수정
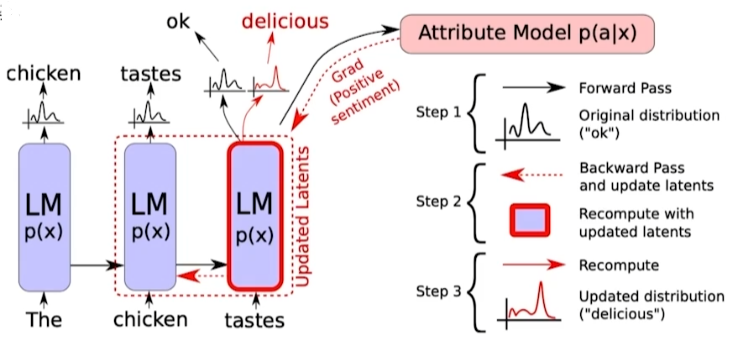
-
tastes 다음에 나올 확률이 높은 단어는 ‘ok’지만, ‘delicious’가 나오길 바라는 상황
-
‘tastes’의 vector를 의도적으로 수정해 ‘delicious’가 나오도록 유도
- gradient update가 되는 것이 아닌 vector 수정
-
확률 분포를 사용하기 때문에 중첩도 가능 (e.g., 기쁨 + 놀람 + 게임)
Multi-modal language model
Grandmother cell (할머니 세포)
이 세포는 1개의 단일 세포가 어떤 개념(concept)에 대해 반응 (e.g. 할머니, 어머니)
- 이 개념과 관련된 사진 외에도 text, 음성 등에 모두 반응
→ 우리 뇌는 multi-modal로 객체를 인지
LXMERT
이미지와 자연어를 동시 학습

ViLBERT (BERT for vision and language)
Dall-e
자연어로부터 이미지 생성
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
