Bellman Optimality Equation
optimal state-value function v(s) : 모든 policy에서 maximum state-value function
optimal action-value function q(s, a) : 모든 policy에서 maximun action-value function

Optimal Policy
value function을 최대로 만드는 policy
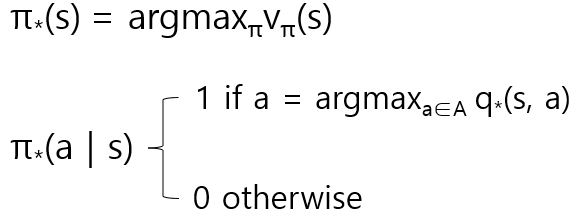
π*(a | s)에서 optimal a 일 때만 probability를 1로 하고 나머지를 0으로 만든다.
이 결과 각 state 마다 한 개의 action만 취하게 된다.
Value iteration & Policy iteration
Dynamic Programming (dp)의 원리로 두 값의 최적값을 찾는다.

초기 v(s) 값을 0으로 설정하고 iteration을 통해 v(s)를 update하며 optimal v를 찾는다.
초기 π(s) 값을 randomly initialize 한 후 iteration을 통해 π(s)를 update하며 optimal π를 찾는다.
글을 쓰면서도 완전히 이해가 되지 않는 부분들이 존재했다. 또한 Reinforcement Learning, Q-function, DQN 등의 내용은 더 연구한 뒤, 글을 남겨야 할 것 같다.

AI-Kid