Hyperparameter Tuning
- OPTUNA, RAY, tune, W&B 같은 tool 존재
WandB
-
하이퍼파라미터 튜닝
-
결과 시각화 대시보드 제공
-
dataset, 모델 버전 관리
WandB Sweep
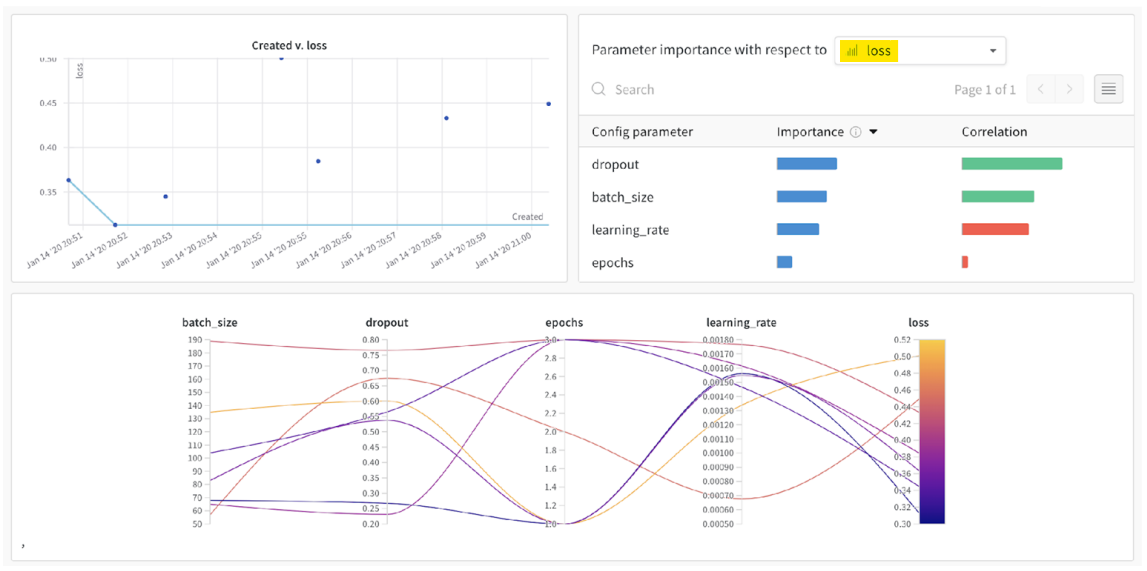
-
원하는 최적화 값을 넣으면 영향을 미치는 하이퍼파라미터와 관계를 시각화
-
그래프를 통해 낮은 loss를 구하기 위해 어떤 하이퍼파라미터를 어떻게 조정해야 할지 확인 가능

- Learning rate의 최대, 최소값 및 분포 설정
실습
Model
class Model(pl.LightningModule):
def __init__(self, tokenizer):
super().__init__()
self.save_hyperparameters()
self.tokenizer = tokenizer
# 페이스북 bart-base 모델의 설정값 불러오기
self.config = transformers.BartConfig.from_pretrained('facebook/bart-base')
# 불러온 설정값을 토대로 AutoModelForSeq2SeqLM(BART) 모델 생성
self.encoder_decoder = transformers.AutoModelForSeq2SeqLM.from_config(self.config)- pre_trained model은 활용하지 않고, 아키텍처만 가져와서 사용
def forward(self, x, y):
outputs = self.encoder_decoder(input_ids=x, labels=y)
return outputs.loss, outputs.logits
def training_step(self, batch, batch_idx):
x, y = batch
# loss 측정
loss, logits = self(x, y)
self.log("train_loss", loss)- encoder-decoder에 x, y를 동시에 넣음
# 훈련/검증 단계 때는 LOSS 등만 확인하지만,
# 최종 예측은 beam search 를 통해 수행되기 때문에
# 훈련 중간 중간의 결과물을 확인하기 위해서 아래 코드를 사용할 수 있습니다.
# (일반적으로는 속도가 매우 느려지기 때문에 훈련단계에서는 포함하지 않습니다)
# 예측값과 정답값이 일치하는지 비교하기 위해 예측 토큰 생성
# Beam search의 N=3으로, 3개의 문장을 생성하고, 가장 좋은 1개의 문장을 받아옴
pred_ids = self.encoder_decoder.generate(x, num_beams=3, min_length=0, max_length=16, num_return_sequences=1)
# 토큰 -> 텍스트 변환
pred = self.tokenizer.batch_decode(pred_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
target = self.tokenizer.batch_decode(y, skip_special_tokens=True, clean_up_tokenization_spaces=False)
# 예측값과 정답값이 일치하는지 측정
accuracy = []
for p, t in zip(pred, target):
if p == t:
accuracy.append(1)
else:
accuracy.append(0)
accuracy = sum(accuracy) / len(accuracy)-
Cross Entropy Loss만 확인해서 학습이 잘 되는지 확인이 어려움
-
self.encoder_decoder.generate- beam_search를 통해 3개의 문장을 생성하고, 가장 좋은 문장 1개를 받음
-
prediction과 beam search 결과를 비교해 accuracy 측정
-
self.log()에 저장한 이름으로 wandb에서 시각화
WandB logging
wandb_logger = WandbLogger(project="date")
trainer = pl.Trainer(accelerator="gpu", devices=1, max_epochs=max_epoch, logger=wandb_logger, callbacks=[checkpoint_callback], log_every_n_steps=1)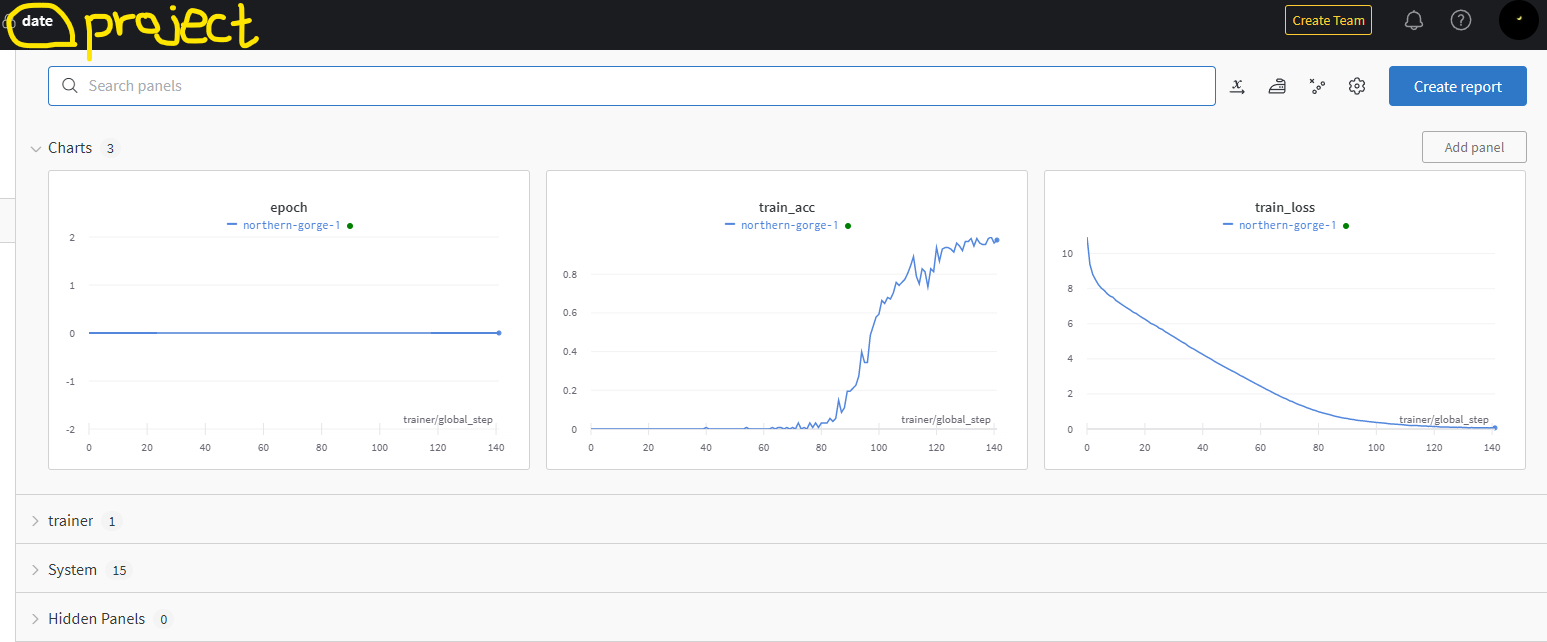
- 상단에 project 이름이 명시되어 있으며, 모델에서 self.log를 통해 넣은 값들을 확인 가능
%%html
<iframe src="주소" width="900" height="1000"></iframe>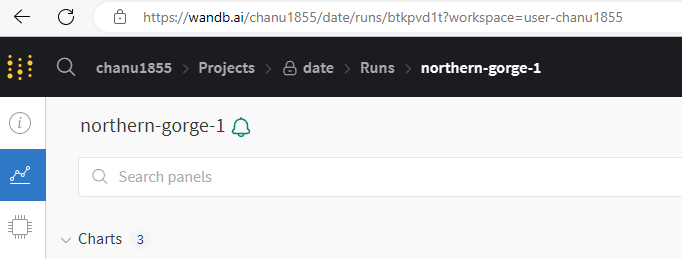
- 주소에 다음과 같이 date/runs/~ 로 시작하는 주소를 입력하면 웹으로 접속하지 않고 주피터에서 볼 수 있음
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid