N2N
Sequence Labeling
문장 전체를 살피고, 특정 part의 의미나 역할 분석에 사용
POS tagging (형태소 분석), NER (개체명 추출)에 이용
text에 대해 동일한 길이의 label sequence 출력
N21, N2M으로 해결하는데는 어려움이 있음
Process
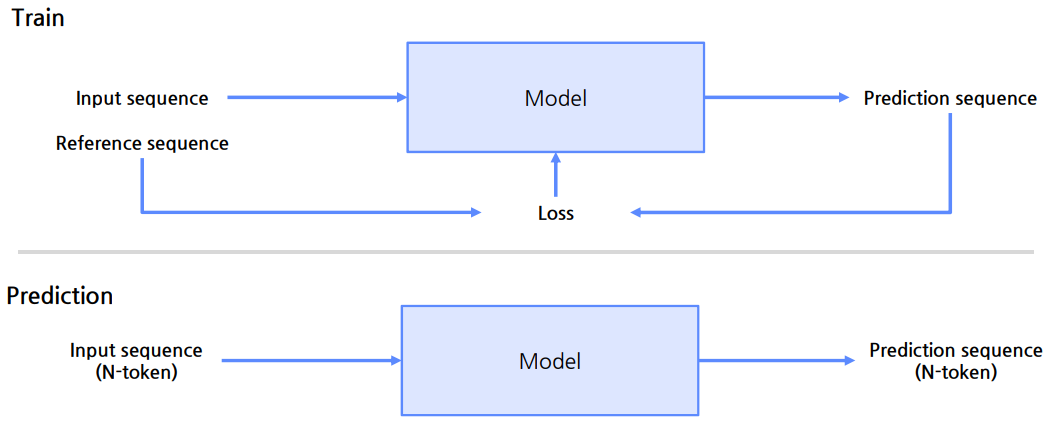
HuggingFace N2N
TokenClassification을 활용해 간단히 훈련 가능
데이터 표현
입력 형태
character, word, subword 방식 등 다양한 토큰화 이용
- 주로 subword를 많이 이용
출력 형태
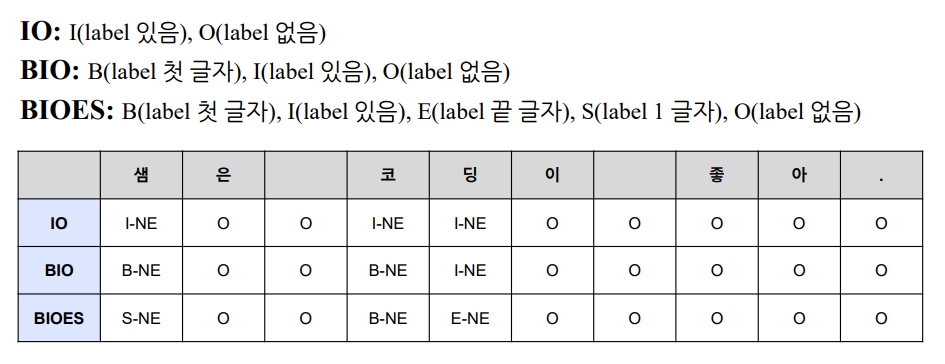
-
주로 BIO를 사용
- ‘코딩이’ 에서 코는 첫 글자이므로 B-NE, 딩은 첫 글자가 아니고 라벨이 있으므로 I-NE
※ NE : Named Entity (개체명)
- ‘코딩이’ 에서 코는 첫 글자이므로 B-NE, 딩은 첫 글자가 아니고 라벨이 있으므로 I-NE
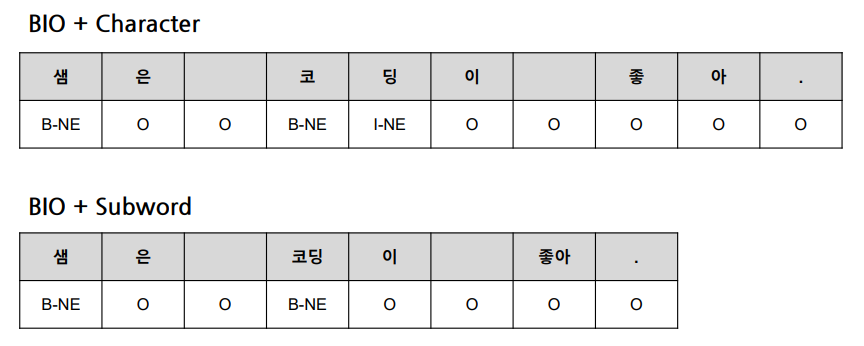
-
입력 토큰 개수에 맞게 출력 토큰 개수도 맞춰줘야 함
-
Subword에서 ‘코’, ‘딩’을 하나로 묶어 B-NE로 만듦
Loss Function
Cross Entropy Loss 사용
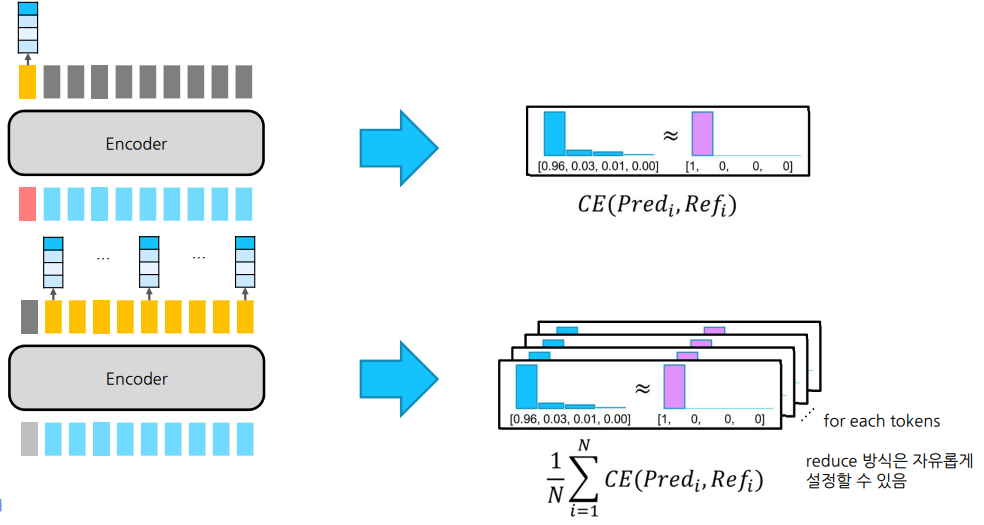
-
N21은 한 번만 계산
-
N2N은 토큰 개수인 N번 계산해서 mean 적용
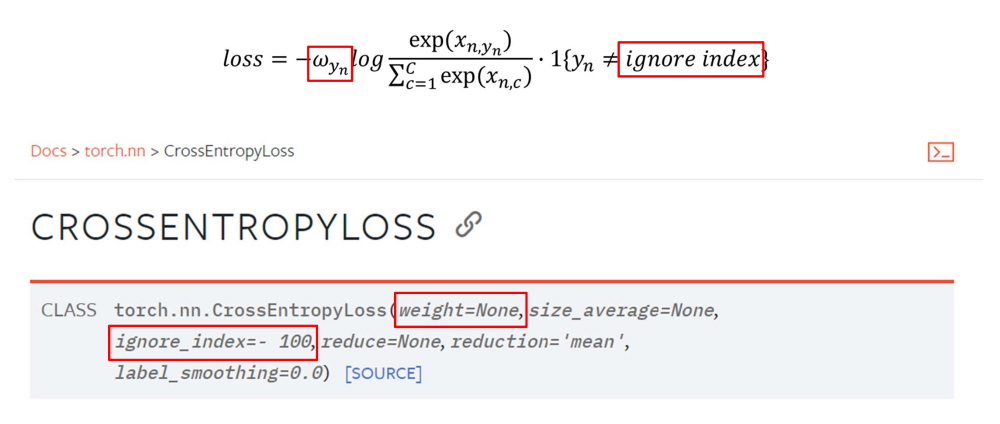
-
위 수식은 Cross Entropy Loss 수식
-
ignore index는 cross entropy를 계산할 때 무시하는 index
-
torch에선 -100 class로 reserve
-
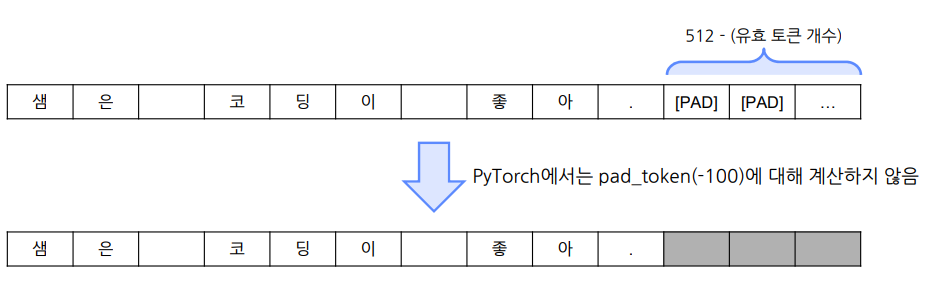
- loss의 weight를 조정해 loss 값을 강화시키거나 왜곡시킬 수 있음
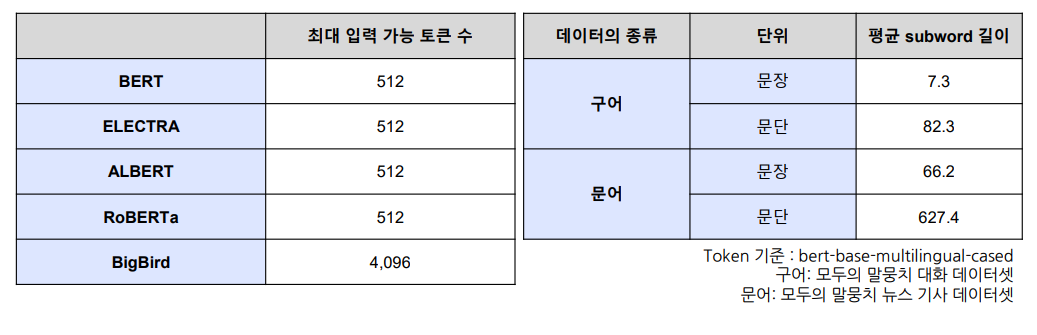
Transformer 모델의 최대 입력 길이
입력 시 max length를 넘는 text는 배제하기 때문에, 잘 고려해야 함
평가
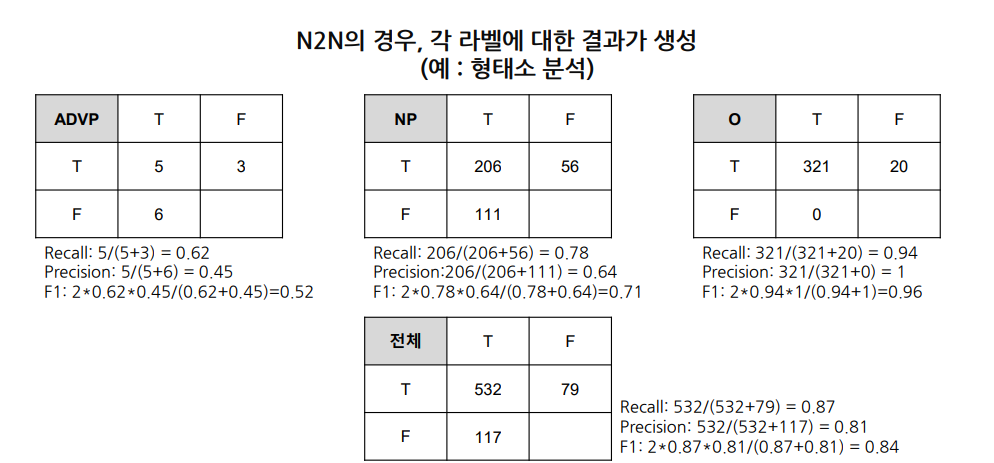
- 모든 token의 classification 결과를 합산해서 계산
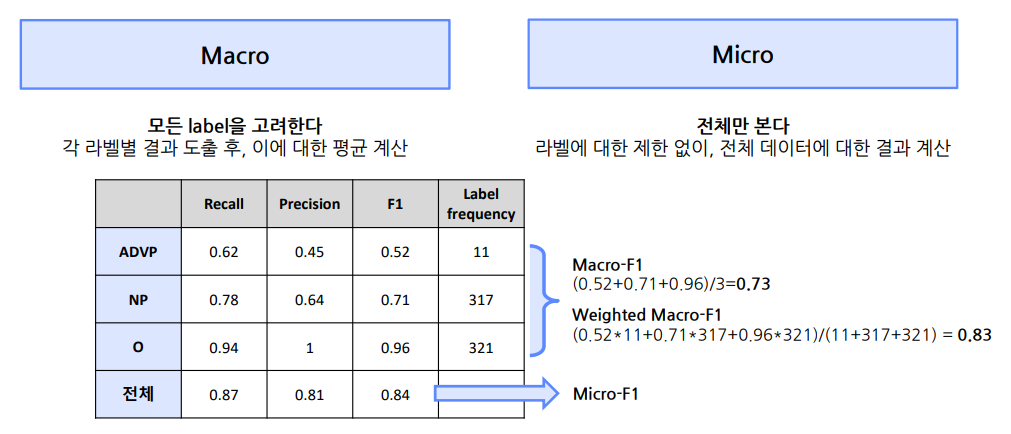
Macro & Micro F1
Conlleval-2000
- sequence labeling measure
- accuracy, micro-f1, macro-f1 등 자동 계산
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid