GPT-2
GPT-1과 구조는 동일하나 더 많은 학습 data를 사용하고 layer를 깊게 쌓음
Datasets
특정 웹사이트의 지지도가 높은 게시물을 크롤링
Preprocess: Byte Pair Encoding(BPE)
Model
Layer가 위로 갈수록 weight를 0에 가깝게 초기화
- 상위 layer의 중요도를 적게 고려
GPT-3
GPT-2와 비교해 월등히 많은 parameter 수, layers, batch-size를 사용

Zero-shot
- task에 바로 GPT-3 모델 적용해 예측
One-shot
- task와 그에 맞는 예시를 한 개 보여주고, 예측
Few-shot
- task와 그에 맞는 예시를 몇 개 보여주고, 예측
⇒ Zero, One, Few-shot 모두 fine-tuning을 사용하는 것이 아닌,
inference 과정에서 example의 패턴을 동적으로 학습하고 예측
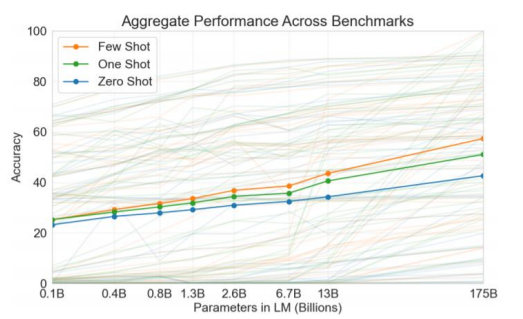
- parameter 개수가 많을수록 성능이 좋아지며, Few-shot이 제일 좋은 성능을 보임
ALBERT
경량화된 BERT
Factorized Embedding Parameterization
embedding vector의 차원을 줄임
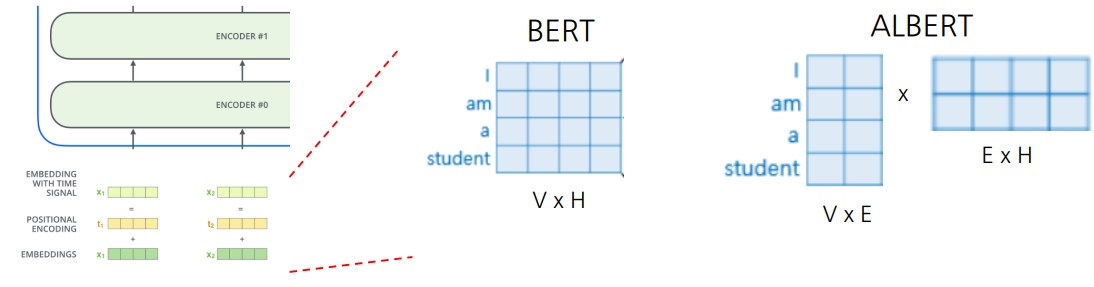
- ALBERT에선 word embedding을 E×H의 가중치 행렬을 이용
- 만약 V = 500, H = 100, E = 15라면, 500 100개의 파라미터를 (500 15 + 15 * 100)개로 파라미터 수와 연산량을 줄여줌
Cross-layer Parameter Sharing
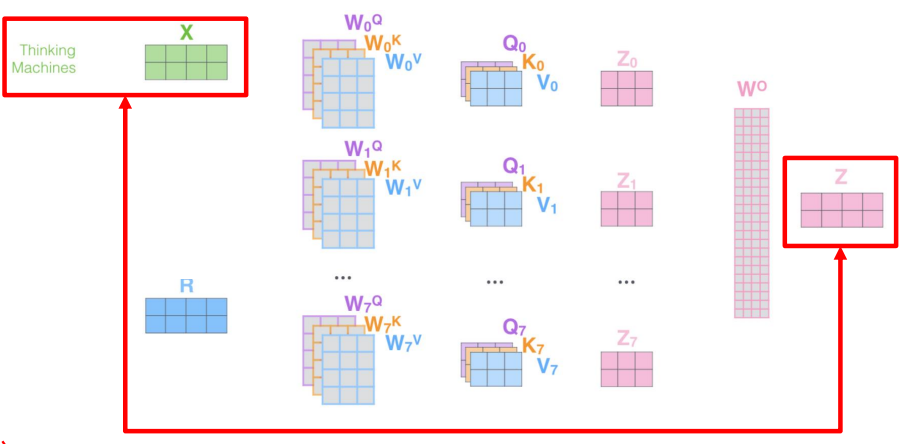
-
학습해야 할 파라미터는 , , ,
-
Shared-FFN : Output layer에 해당하는 FFN layer parameter를 layers에서 모두 공유
-
Shared-attention : , , , 들을 layers에서 모두 공유
-
All-Shared : FFN, attention 파라미터를 모두 공유
Sentence Order Prediction
-
BERT 모델에서 다음 문장이 맞는지 아닌지 예측하는 것은 너무 쉽다.
-
정순서를 유지하는 두 문장의 순서를 역으로 바꾸고, 정방향인지 역방향인지 예측
- 무작위로 두 문장을 추출해 순서를 유지하는 것은 쉽지만, 기존에 연속적인 두 문장의 순서를 바꿔 정순인지 역순인지 예측하는 것은 어려움
- 무작위로 두 문장을 추출해 순서를 유지하는 것은 쉽지만, 기존에 연속적인 두 문장의 순서를 바꿔 정순인지 역순인지 예측하는 것은 어려움
ALBERT는 GLUE Results에서도 좋은 성능을 보임
ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately
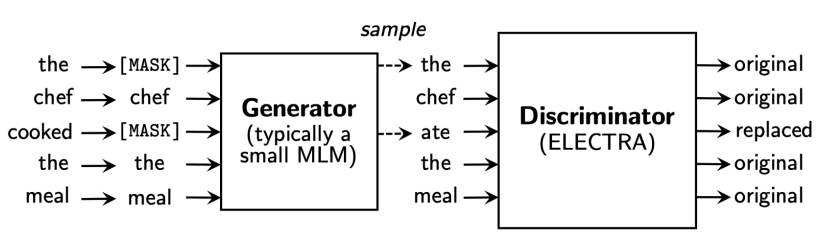
-
Language Modeling을 통해 단어를 복원해주는 Generator,
복원된 각각의 단어가 기존 단어인지, replaced된 단어인지 예측하는 Discriminator
-
Generator는 masked된 문장을 받아 mask를 예측하는 기존 BERT 모델과 유사
-
Discrimator도 transformer block을 쌓아 만듦
-
Pre-trained model로는 Generator가 아닌 Discriminator를 사용
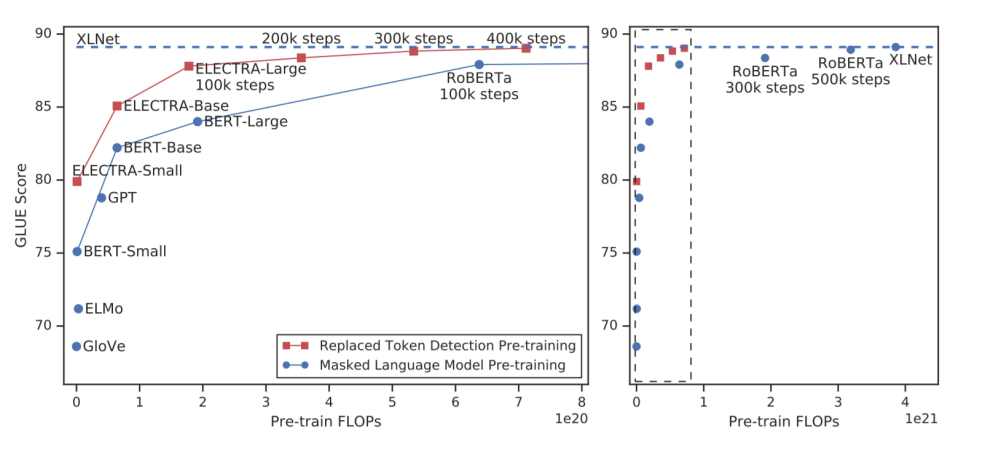
ELECTRA v.s. BERT
Light-weight Models
경량화 모델은 크기가 큰 모델의 성능은 최대한 유지하되, 휴대폰과 같은 소형 device에서도 모델을 load해서 쓸 수 있을 정도로 light하게 하는 것이 목표
DistillBERT
Hugging Face에서 제작
teacher - student model
-
teacher model은 large model이고, student model은 light-weight model
-
student model은 teacher model의 output인 softmax distribution을 최대한 유사하게 학습
TinyBERT
DistillBERT와 동일하게 output distribution을 유사하게 학습할 뿐만 아니라,
중간 결과물(Hidden states vector, embedding 등)들도 유사하게 학습
Knowledge graph
주어진 문서 외에 필요한 지식
- e.g., 꽃을 심기 위해 땅을 팠다. → 필요 도구 : 삽
집을 짓기 위해 땅을 팠다. → 필요 도구 : 포크레인
BERT는 외부 지식이 필요한 문서에는 취약점을 보임
- Knowledge graph를 잘 정의하고 BERT에 잘 결합하는 것이 중요
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
