GPT-1
다양한 special token들을 생성
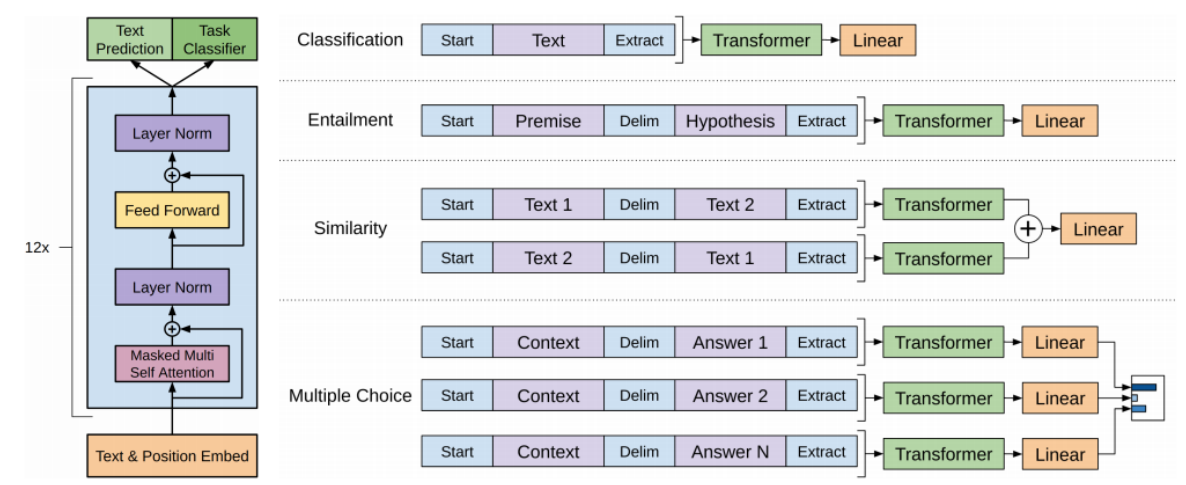
- 다음 단어를 예측하는 Text Prediction과 분류를 위한 Task Classifier를 동시에 도출, 학습
-
Classification
- Text에 Start, Extract token 삽입
- Extract token에 대한 Encoding output vector만 Linear layer를 통해 분류
-
Entailment
-
Premise가 참이면 Hypothesis도 참인 내포 관계가 존재
-
Premise와 Hypothesis를 연결하고 Delim token으로 구분
-
Extract의 linear transformation 결과에 따라 Premise와 Hypothesis가 내포인지, 모순인지 판별
-
Extract token
-
Self-Attention에서 Query로 사용
-
task에 필요로 하는 정보들을 입력 문장에서 추출
-
-
-
Fine-tuning
Pre-trained된 transformer encoder와 main task를 위한 추가적인 layer를 덧붙임
-
추가 layer은 weight randomly initialized
-
Pre-trained model에는 learning rate를 작게, 덧붙인 layer는 그대로 유지하며 전체 네트워크를 학습
Text Prediction은 Pre-trained model을 통해 별도 label 없이 다음 단어 예측 만으로 학습이 가능
- 대규모 데이터를 사용하며 self-supervised learning
main classification task는 labeled data를 필요로 하며, 상대적으로 데이터가 적음
대규모 데이터로부터 얻을 수 있는 지식을 소량 데이터가 존재하는 target task에 전이학습
GPT-1 model을 다양한 task에 fine-tuning한 result
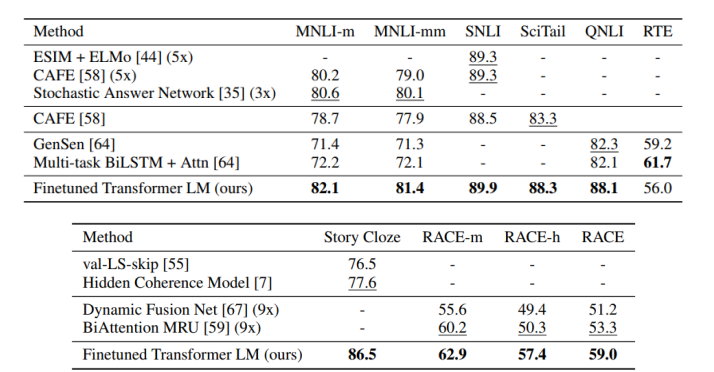
- task만을 위해 customized된 model보다 더 높은 성능을 보임
BERT
Motivation
이전 문장만 고려하는 것보다, 앞 뒤 문맥을 모두 활용하는 것이 좋음
Masked Language Model
문장의 몇 퍼센트를 mask로 치환할 것인가를 hyperparameter로 사용
- 너무 mask 비율이 높으면 예측하기에 충분하지 못함
- 너무 비율이 작으면 학습 효율 및 속도가 떨어짐
- 15%를 사용
Problem
Pre-trained Model이 masked된 문장에 익숙해져 있음
이 model을 다른 classification task 수행에 사용할 땐 mask token이 더 이상 등장X
main task 수행하기엔 차이점들이 학습을 방해할 수 있음
Solution
-
치환된 15% 내에서도 다른 형태로 단어를 변경
-
e.g., 100개 단어 중 15개의 단어를 치환할 때,
-
15개의 80%는 mask token으로 치환
-
10%는 random word로 치환하고, 그 단어가 원래 단어로 복원되도록 학습
-
나머지 10%는 단어를 변형하지 않고, encoding 벡터가 해당 단어를 소신있게 유지하도록 학습
-
Next Sentence Prediction

- [SEP] token을 문장 끝에 삽입해 두 문장을 구분
- [CLS] token을 문장 맨 앞에 넣으며 classification 정보를 저장
- CLS token이 최종 Linear layer에 input으로 쓰이며, layer output이 classification result
- [MASK] token에 어떤 단어가 들어갈 지 예측
Bert Summary
구조
- transformer의 self-attention block을 그대로 사용
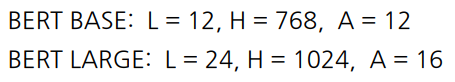
L : attention block 개수, H : encoding vector 차원, A : head 개수
Input Representation
-
입력 sequence를 word보다 더 작은 subword를 embedding
- e.g., pre-training → pre + training
-
Positional Embedding 자체도 학습
-
classification embedding token인 [CLS] 추가
-
Packed Sentence embedding token인 [SEP] token 추가
-
Segment Embedding
- 문장 레벨에서의 position을 반영한 embedding
- 문장 레벨에서의 position을 반영한 embedding
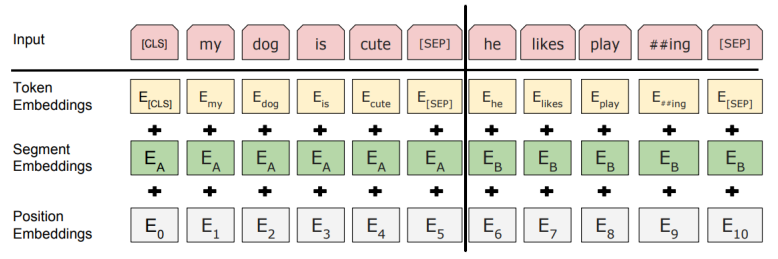
단어 ‘he’는 6번째 position이지만, B문장의 1번째 position이기도 함
이러한 정보를 위해 문장별 embedding vector인 segment embedding 정보 추가
같은 문장에 대해선 모두 같은 segment embedding을 더해줌High-level View
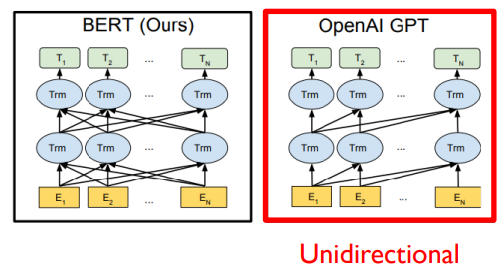
-
GPT의 경우 특정 time step에서 이후 time step에 나타나는 단어에 접근이 불가능
- 따라서 GPT는 masked self-attention 사용
-
BERT는 매 time step에서 모든 time step의 단어에 접근 허용
Fine-tuning Process
1) Sentence Pair Classification Task
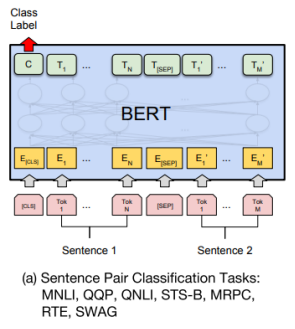
- 문장을 [SEP] token으로 구분해 하나의 sequence로 BERT에 Encoding
- 각 word들에 대한 Encoding vector를 얻음
- [CLS] token에 대한 encoding vector를 output layer의 입력으로 줌
→ 다수 문장에 대한 예측
2) Single Sentence Classification Task
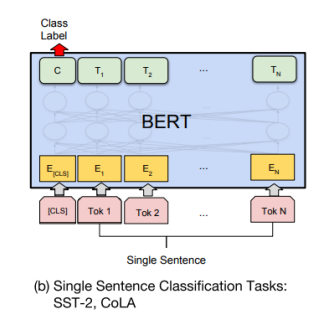
- 입력 문장이 한 개
- 다수 문장과 똑같이 [CLS] token을 output layer로
3) Single Sentence Tagging Task
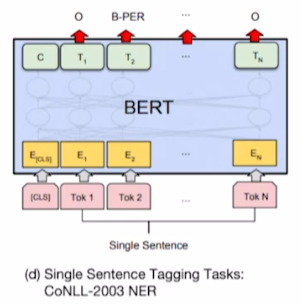
- 모든 word에 대해 tagging
- [CLS] token을 포함한 word encoding vector를 모두 동일한 output layer를 통과
BERT v.s GPT-1
| data size | tokens | batch-size | Task-specific fine-tuning | |
|---|---|---|---|---|
| BERT | 2,500M words | [SEP], [CLS] | 128,000 words | 각 task 별로 다른 learning rate |
| GPT-1 | 800M words | [EXTRACT] | 32,000 words | 모든 task에 같은 learning rate |
- batch-size가 클수록 더 좋은 학습 효과
- 추가로 BERT는 Segment Embedding 사용
Machine Reading Comprehension(MRC), Question Answering

- 주어진 지문을 이해하고, 질문에 대한 대답을 그에 맞게 제공
SQuAD 1.1 (Stanford Question Answering Dataset)
- wikipedia에서 random으로 글을 가져와 질문에 대한 정답을 직접 labeling한 dataset
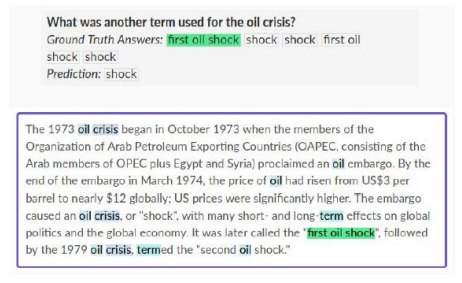
-
BERT의 입력으로 질문과 지문을 [SEP] token을 이용해 concat후 하나의 sequence를 encoding
-
만약 지문의 단어가 124개라면, 124개의 encoding output vector를 얻음
-
모든 단어를 FC layer를 통과해 124개의 scalar 값을 얻음
-
softmax 함수를 적용해 정답의 첫 번째 단어를 예측 (first oil shock의 ‘first’)
-
마지막 단어 예측을 위해 새로운 FC layer 통과
-
softmax 함수를 적용해 ending word를 예측 (shock)
-
softmax loss를 통해 FC-layer를 역전파 학습
SQuAD 2.0
SQuAD 1.1에서 정답이 없는 dataset까지 추가
model은 답이 있는지 없는지를 먼저 판단하고, 있으면 SQuAD 1.1 예측 task와 동일
정답 존재 여부는 [CLS] token을 이용해서 판단
- 문장과 지문을 concat 후 output layer에 [CLS] token을 input으로 해 binary classification
On SWAG
- 뒤에 올 문장을 선택하는 task

- 주어진 문장과 (i), (ii), (iii), (iv) 문장을 하나씩 concat해 4개의 경우를 고려
- [CLS] token을 이용해 모든 경우의 scalar 값을 뽑아냄
- 4개의 scalar 값에 softmax를 적용하고, 정답 문장을 100% 확률로 만들어줌
- 위 과정을 통해 softmax loss를 이용해 역전파 학습
BERT는 모델 size를 키울수록 성능이 끝없이 올라감
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
