Recent Work in Dta-Centric NLP
Recent Work in Data Augmentation
Iterative Back-Translation for NMT
- Re-back translation을 제시
Task-Agnostic Data Augmentation
- BT, EDA 같은 task-agnostic 기법은 RNN, LSTM 같은 model에선 효과가 있었으나, BERT 같은 pre-trained model에는 효과가 없었음
ChatAug: Leveraging ChatGPT
- ChatGPT를 이용한 data augmentation
Recent Work in Data Filtering
병렬 말뭉치 필터링
-
Rule Based, Statistic Based, NMT Based
- Rule과 NMT based가 주로 사용됨

- Rule과 NMT based가 주로 사용됨
Recent Work in Synthetic Data
PromptBase
- 효과적인 Generative AI 사용을 위한 prompt를 사고 파는 웹 사이트
Pre-train, Prompt, and Predict
-
Survey 논문
-
언어 모델에게 입력으로 주어지는 템플릿 글을 Prompt라고 함
-
최근 NLP 모델에선 Model-Fine tuning과 더불어 Prompt Tuning이 필요
Prompt Programming for LLM
-
Metaprompt
- Prompt를 생성하기 위한 Prompt
음성인식 후처리기 연구를 위한 합성 데이터
-
음성인식 결과에 특수문자 생략, 숫자 변환 등 오류가 일어 날 수 있음
-
병렬 말뭉치 구축
-
네이버 뉴스 기사는 띄어쓰기, 맞춤법 등 오류가 없음
-
이런 데이터를 TTS → STT를 거쳐 오류가 포함된 문장 생성
-
원문-변환 문장의 병렬 말뭉치를 구축
-
Recent Work in Data Measurement
Measuring Annotator Agreement
-
Krippendorff’s Alpha는 복잡한 task에 적용이 어려움
- 또한 적절한 distance function을 고르기 어렵고 결과 해석에 명확한 기준이 없음
-
해당 논문에선 새로운 IAA measure를 제안
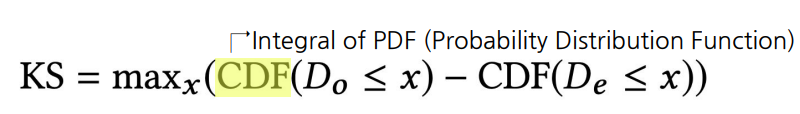
Everyone’s Voice Matters
-
인구통계학적 정보를 바탕으로 annotator 간 불일치 정도 예측기를 학습
- 외부 resource를 사용해 예측 정확도를 높임
-
annotator의 정보가 공개된 데이터로 학습
Etc.
Cross Lingual Transfer Learning
-
영어로 만든 BERT를 한국어 BERT로 변환
-
과정
-
영어 BERT의 Encoding weight를 freeze하고 encoding layer 앞 뒤로 adaptation layer를 추가
-
Freeze 풀고 전체에 대해 학습
-
Future of Data-Centric NLP
Multi-Modal AI
정의
-
텍스트, 이미지, 비디오 등 데이터를 함께 처리하여 더 정확하고 효과적인 모델 구축
-
Uni-Modal data를 확장하는 dataset 이용
-
Dataset
- 텍스트, 이미지, 음성, 비디오 등 여러 모달들이 융합
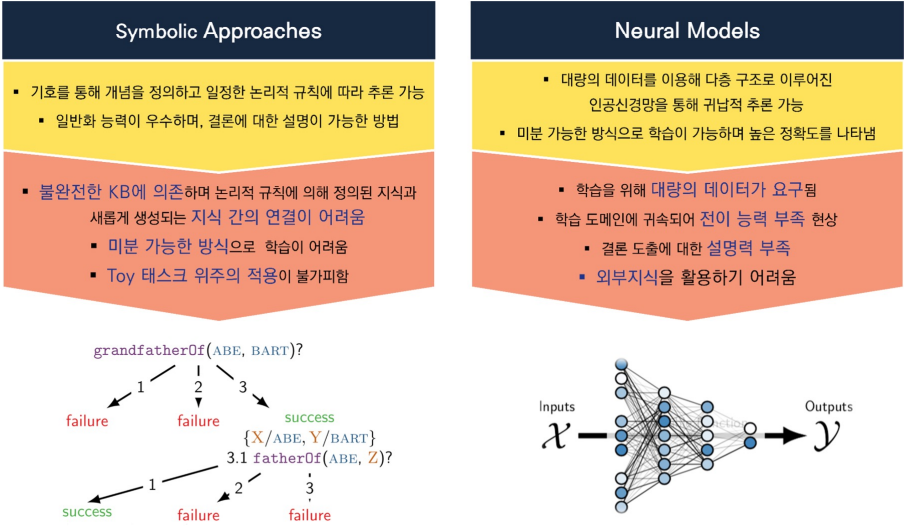
Neuro-Symbolic AI
등장배경
-
Symbolic AI와 Neural Network를 결합해 새로운 종류의 AI 모델 생성
-
Symbolic AI는 기호적인 표현을 이용해 문제 해결
- 추론, 논리적 추론, 추론 엔진 및 NLP에 주로 사용
-
정의
-
Neuro Symbolic은 Neural Network에 외부 상식을 주입
-
외부 Graph 구조의 knowledge를 Embedding 시켜 같이 Neural Net에 injection
활용분야
- NLP에서 ML 모델이 자연어 문장을 이해하고, 중간 계층이 이를 분석해 논리적 구조로 변환한 뒤, Symbolic 모델이 이를 바탕으로 추론 및 자연어 생성
작동방식
- Neural Network가 받는 표현을 바탕으로 Symbolic AI가 사용하는 추론 엔진을 사용해 문제 해결
RLHF
기본 용어
-
agent = LM
-
policy = LM parameters
-
environment = LM input, 즉 prompt
-
action = token 생성 및 sequence 생성
-
reward = RM output
등장배경
-
Cross Entropy는 한계가 존재
-
인간의 피드백을 성능의 척도로 사용하고, 이 피드백을 loss로 사용
작동방식
-
Pre-train language model
-
Gathering data and training a reward model
-
Fine tune language model with reinforcement learning
ChatGPT
-
GPT-3를 크라우드소싱한 data에 대해 지도 학습
-
인간이 Model의 output 품질에 대한 ranking
-
rank를 바탕으로 reward model 학습
-
지도 학습된 GPT에게 여러 유저의 input을 주고 reward model을 함께 interaction하며 강화학습
-
GPT model이 답변 생성을 하면 이를 reward model을 통해 좋은지 아닌지 평가
GPT-4
-
LLM + MultiModal + RLHF
-
Visual Input
-
Longer Context
-
Creativity
한계점
-
hallucination
-
데이터 update 2021년
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
