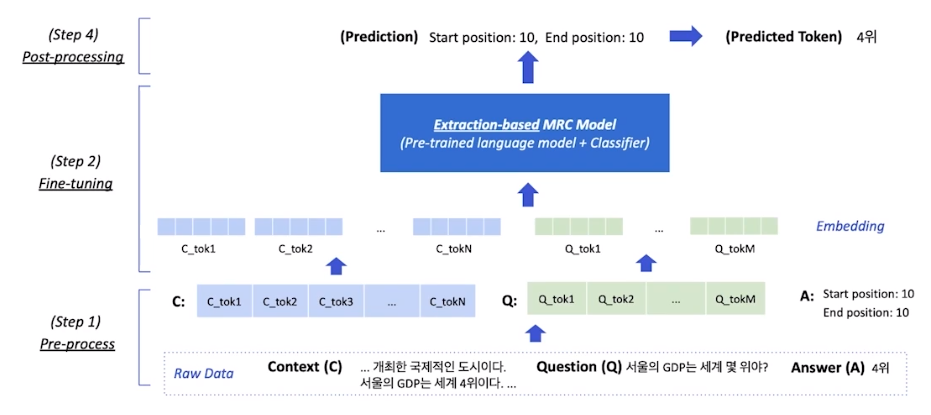
Extraction-based MRC
문제 정의
-
질문의 답변이 항상 주어진 지문 내에 span으로 존재
-
HuggingFace datasets에서 관련 dataset 다운로드 가능
F1 Score
-
nervous breakdown이 유일한 정답이고, 예측이nervous일 때 F1 score 값은?-
-
breakdowntoken이 ground tokens에 포함되므로 2로 나눔
-
-
Overview
Pre-processing
Special Tokens
-
[CLS], [SEP] token 사용
-
[CLS] Question tokens [SEP] Context tokens 형태
Attention Mask
- [PAD] token처럼 해석이 필요없는 token 구분
Token Type IDs
- 입력이 2개 이상일 때(질문&지문), 각각 ID를 부여해 모델이 구분하도록
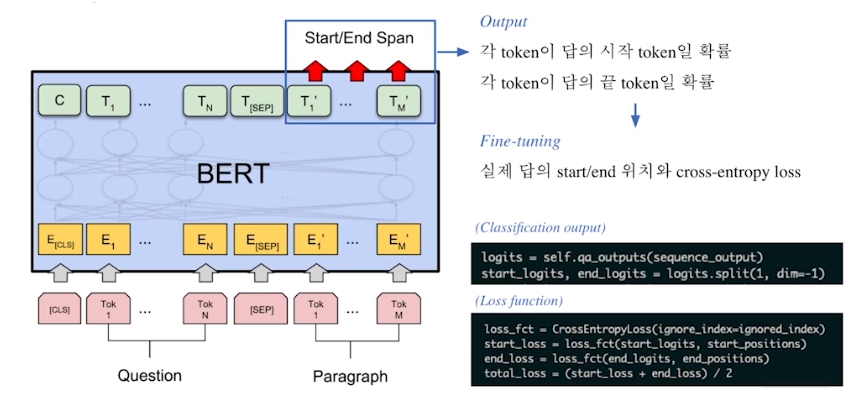
모델 출력 값
- Extraction-based에선 답안을 생성하기 보다, 시작 위치와 끝 위치를 예측하도록 학습
Fine-tuning
Fine-tuning BERT
Post-processing
불가능한 답 제거하기
- End position이 start position보다 앞에 있는 경우
- 예측한 위치가 context를 벗어난 경우
- max answer length보다 긴 경우
최적의 답안 찾기

실습
데이터 및 metric 로드
from datasets import load_dataset
from datasets import load_metric
datasets = load_dataset("squad_kor_v1")
metric = load_metric('squad')prepare_train_features
-
주어진 텍스트를 토크나이징
-
이 때 텍스트의 길이가 max_seq_length를 넘으면 stride만큼 슬라이딩하며 여러 개로 쪼갬
※ doc_stride parameter
-
컨텍스트가 너무 길어서 나눴을 때 오버랩되는 sequence 길이
-
만약
max_seq_length=384,doc_stride=128,context_length=500이라 하면,
context_length를 둘로 나눔 length=(384, 500-384+128 = 244)각 문서에서 답을 찾고, 더 확률이 높은 답변을 가져가는 방식
-
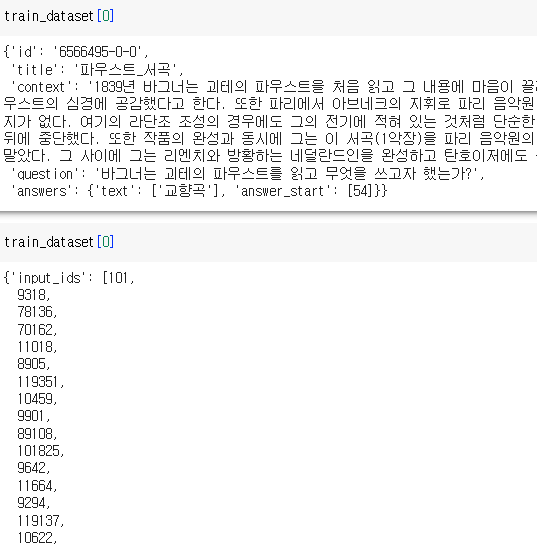
전처리 전/후 비교
-
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid