Transformer
재귀적인 구조가 없고 attention 구조에 기반
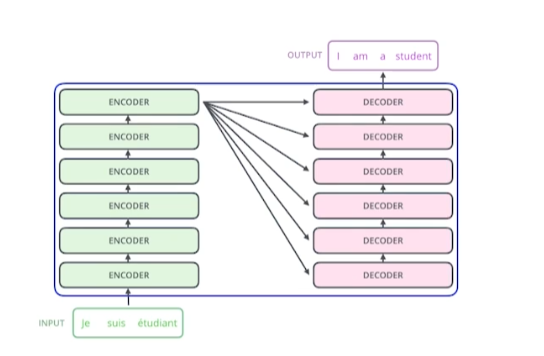
- Encoder에서는 한 번에 n개의 단어를 처리할 수 있음
Self-Attention
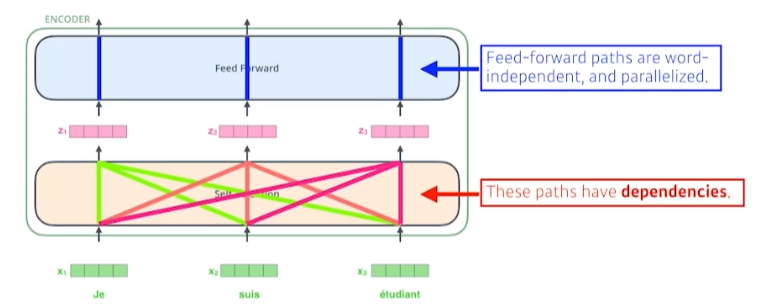
- Self-Attention에서는 에서 로 변환할 때 다른 x들을 모두 고려
- Feed-Forward는 독립적
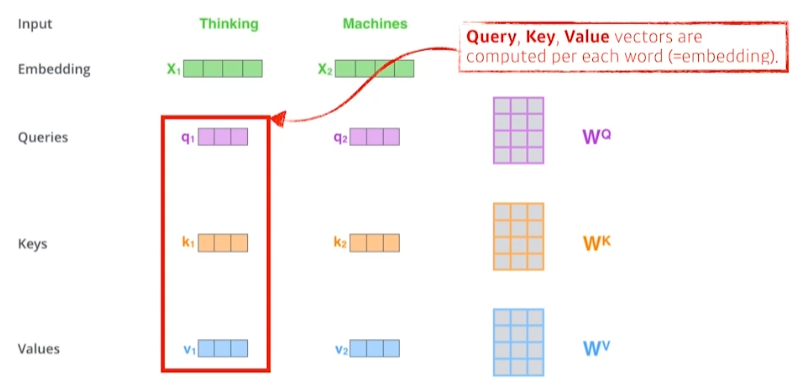
- 모든 단어에 대해 Q, K, V 벡터 생성
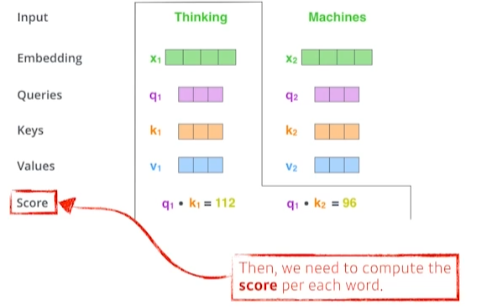
- Score 벡터 생성 (내적)
- Thinking이라는 단어가 다른 단어와 얼마나 유사한지 유사도를 구하는 것
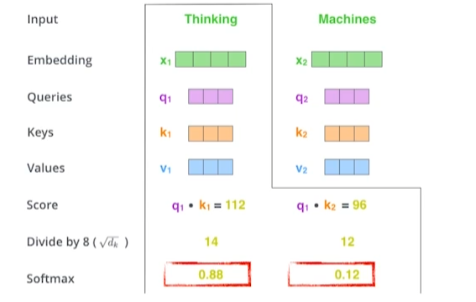
- Score 벡터를 로 나눠줌
- 값이 너무 커지지 않게 scaling
- 나눈 score 벡터에 softmax 적용
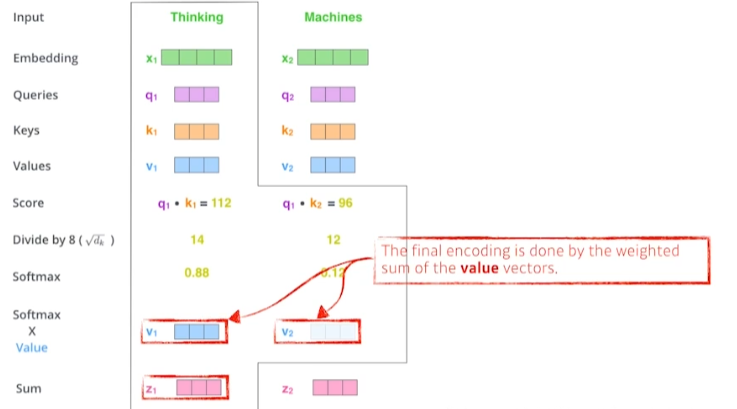
- value 벡터와 softmax 함수 값 weighted sum
- 주의해야 할 것은 Query 벡터와 Key 벡터는 차원이 같아야 한다. (내적을 해야하기 때문)
- Value 벡터는 가중합을 하기 때문에 차원이 다를 수 있음
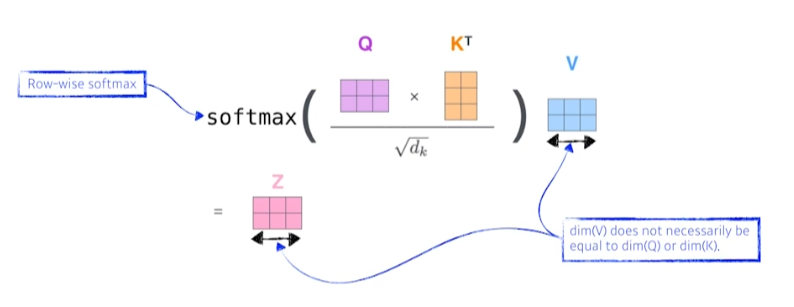
- 단어들을 나누지 않고 문장 단위의 행렬로 연산 가능
Transformer은 n개의 입력에 대해 연산을 해야하므로 computational cost가 크다.
Multi-head Attention
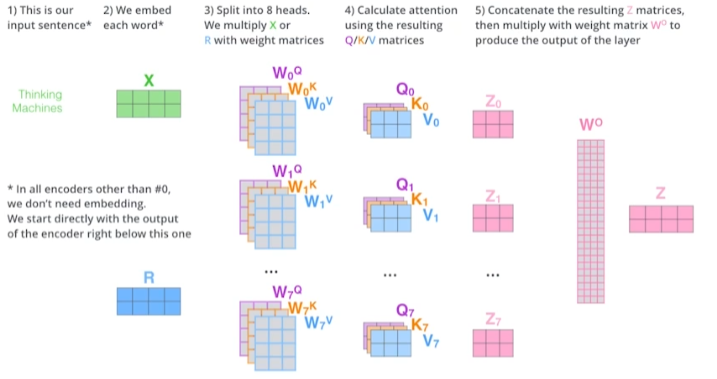
- head 개수만큼 나눠서 처리 후 마지막에 를 곱해 Z 벡터 도출
Positional Encoding
Transformer은 문장 순서에 대해서는 independent
문장의 position 정보를 더해줌 (bias)
Decoder
Encoder에서 Key, Value Matrix를 받음
학습 단계에선 masking을 사용해 이전 단어들만 고려
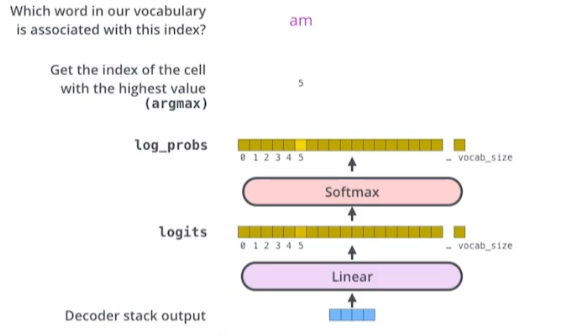
- 단어들의 분포를 만들어 최종 output 도출
※ 모든 이미지의 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid