Positional Encoding
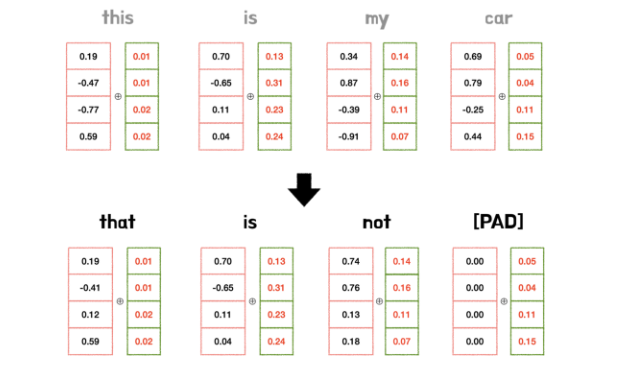
- 모든 위치값은 sequence의 길이나 input에 상관없이 모두 동일
- 예시에서 두 문장은 길이도 구성 단어도 다르지만, 위치 벡터는 모두 동일
Sin & Cos 함수
위치 벡터는 의미 정보가 변질되지 않도록 너무 큰 값을 가지면 안된다.
- Sin, Cos 함수는 -1 ~ 1 사이값을 가지며 조건을 만족
두 함수는 주기 함수이므로 토큰의 위치 벡터가 같아질 수 있다?
- positional encoding은 스칼라 값이 아닌, 벡터 값이다.
- 위치 벡터값이 같아지는 문제를 해결하기 위해, 다양한 주기의 sin & cos 함수를 동시에 사용
왜 Sin, Cos을 둘 다 사용할까?
- 한 함수만 사용한다면 단어 벡터들 사이의 차이가 매우 미미할 것이다.
- 서로 다른 frequency를 갖는 sin, cos 함수를 번갈아 이용해 충분히 다른 PE값을 갖게 함
Masking
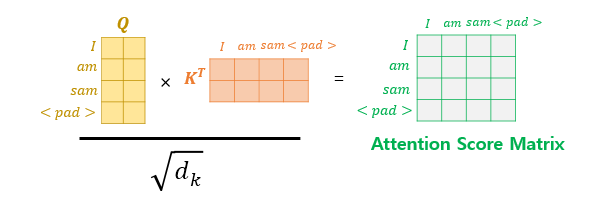
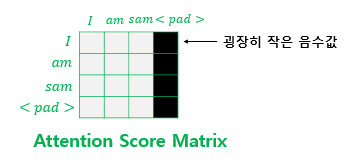
- 입력 문장에 토큰이 있는 경우 신경 쓰지 않기 위해 적용
- softmax 후 해당 값이 0으로 되며 단어간 유사도에 영향을 미치지 않게 함
look-ahead mask
디코더의 첫 번째 서브층(masked multi-head self-attention)에서 일어남
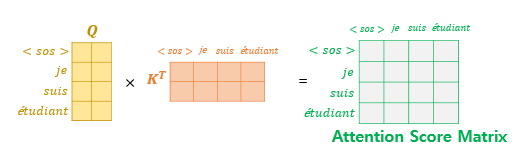
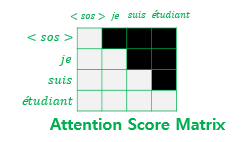
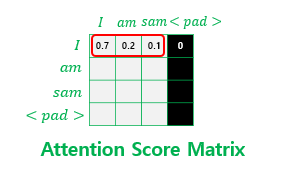
- 마스킹 된 후의 어텐션 스코어 행렬의 각 행을 보면 자기 자신과 그 이전 단어들만을 참고할 수 있음
💡 트랜스포머에는 총 세 가지 어텐션이 존재하며, 모두 multi-head attention을 수행하고,
multi-head attention 함수 내부에서 scaled dot-product attention 함수를 호출하는데 각 어텐션 시 함수에 전달하는 마스킹
1) 인코더의 self-attention : padding mask를 전달
2) 디코더의 첫번째 서브층인 masked self-attention : look-ahead mask를 전달
3) 디코더의 두번째 서브층인 encoder-decoder attention : padding mask를 전달

AI-Kid