Word Embedding
Word Embedding
단어와 좌표를 사전 학습
각 단어를 vector로 변환해주는 기법
- 유사한 단어는 short distance, 유사하지 않은 단어는 far distance로 mapping
Word2Vec
인접한 단어는 유사한 의미를 가질 것이라는 가정
문장 내에서 주변 단어를 가지고 학습
모델 구조
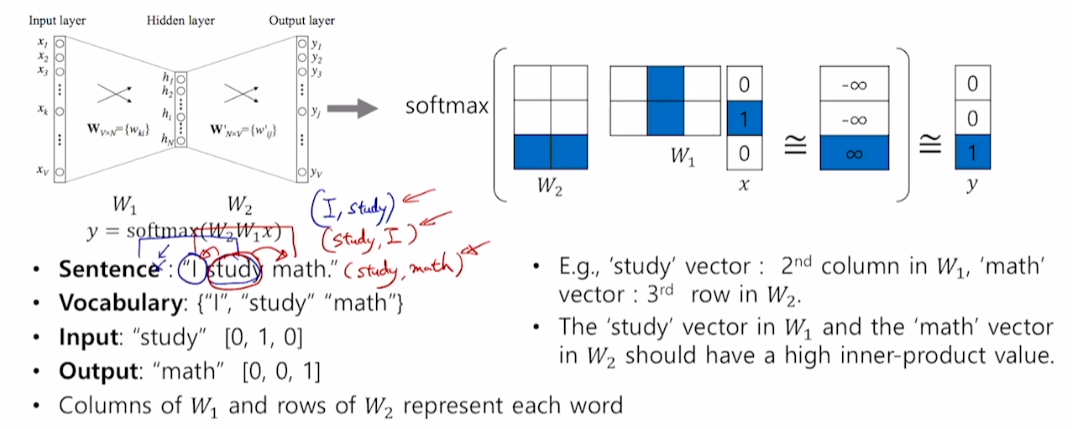
-
모델은 2-layer architecture
-
학습 데이터 구성
-
입력 문장이 I study math이고, window-size=3으로 지정하면
-
중심단어 양 옆 한 개 씩을 가져와 입·출력 단어 쌍을 만든다.
-
중심 단어가 I일 땐 (I, study)
-
중심 단어가 study일 땐 (study, I), (study, math)
-
이러한 방식을 sliding window라고 함
-
-
-
그림에서는 embedding dimension을 2로 설정
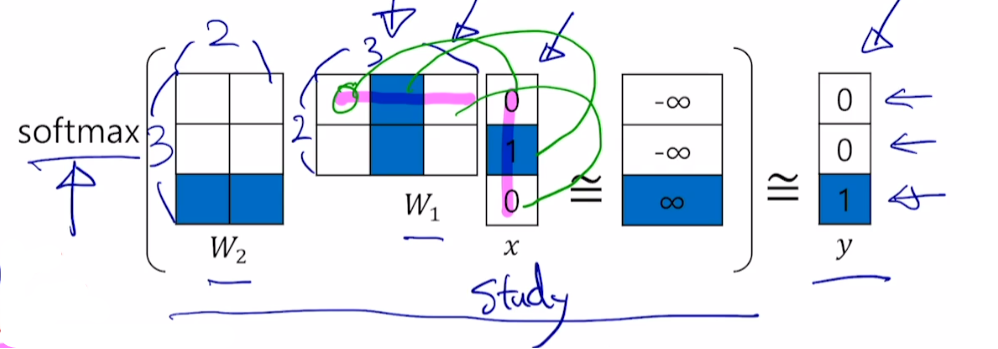
-
x = study, y = math
-
은 input 단어를 hidden layer로 mapping
- 크기는 (embedding layer, 단어 벡터 차원=vocab size) 이다.
-
은 hidden layer에서 output layer로 mapping
- 크기는 (단어 벡터 차원=vocab size, embedding layer) 이다.
-
input으로 (study, math) 단어쌍이 입력됐다고 할 때,
-
study의 one-hot vector은 [0, 1, 0]이며 one-hot vector index가 1이다.
-
과 내적을 진행하면 에서 index번째 (1번째) 열벡터를 뽑아냄
- 실제 연산에선 내적을 진행하지 않고 인덱스만 뽑음
-
-
hidden layer output vector와 를 내적
-
ground truth인 math [0, 0, 1]과 가장 유사하게 나타나려면
-
가장 이상적은 logit값은 위 사진처럼 (-, -, )
- ※ logit : softmax의 input 값
-
ground truth인 math를 제외한 나머지 단어는 최대한 작은 유사도를 갖게끔 학습
-
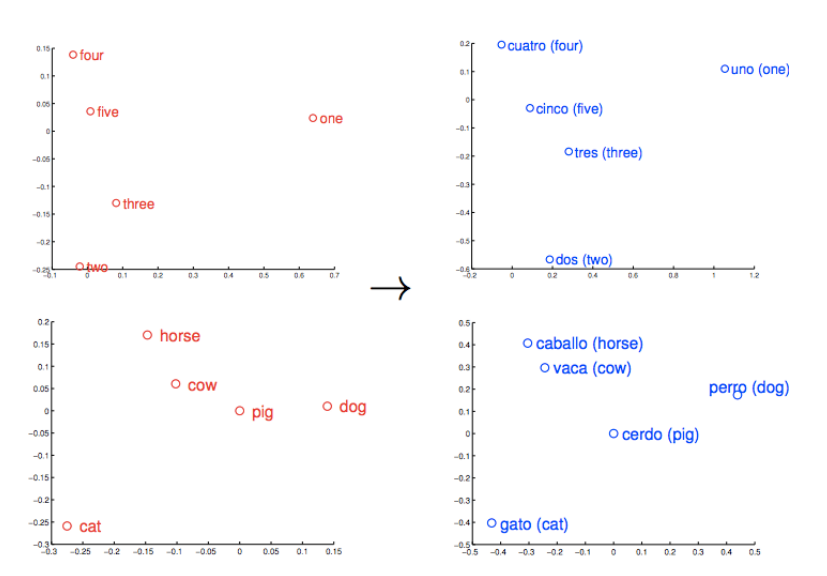
Property of Word2Vec
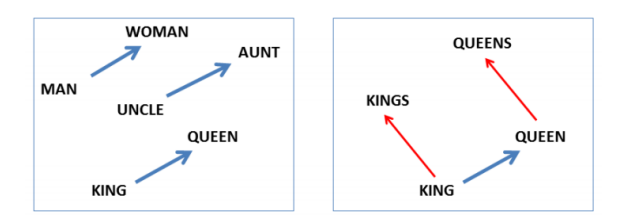
-
동일한 관계는 동일한 벡터를 갖는다.
- Man-Woman, Uncle-Aunt, King-Queen은 모두 동일한 관계(동일한 벡터)
-
Word Intrusion Detection
-
여러 단어들 중 의미가 다른 단어를 찾아내는 과정
-
한 단어와 각 단어의 유클리디언 거리 평균을 취해 가장 큰 값을 구함
-
e.g., math shopping reading science
-
math, shopping, reading, science에 대해 모두 나머지 단어들과의 평균 거리를 구함
-
-
Application of Word2Vec
- 감정 분석 (Sentiment Analysis)
- Image Captioning
- Machine Translation
Glove
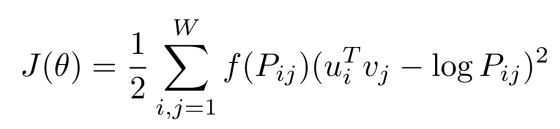
Word2Vec과의 차이점
-
입·출력 단어 쌍에 대해 두 단어가 window 내에서 총 동시 등장 횟수를 사전에 계산
-
에서 은 중심 단어 i의 임베딩 벡터, 은 주변 단어 j의 임베딩 벡터
-
는 중심 단어 i와 주변 단어 j의 동시 등장 확률
-
임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의
동시 등장 확률이 되도록 만드는 것이 목표 -
학습이 빠름
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
