RNN Basic Structure
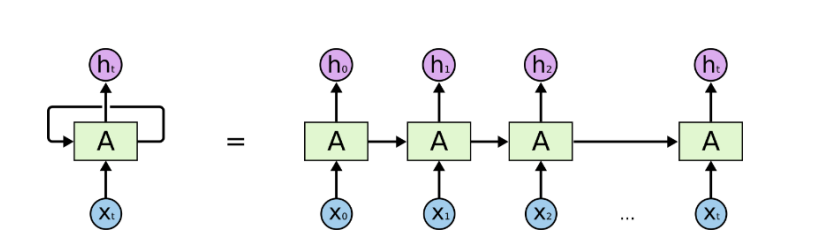
- 동일한 RNN 모듈 A가 매 time step마다 사용
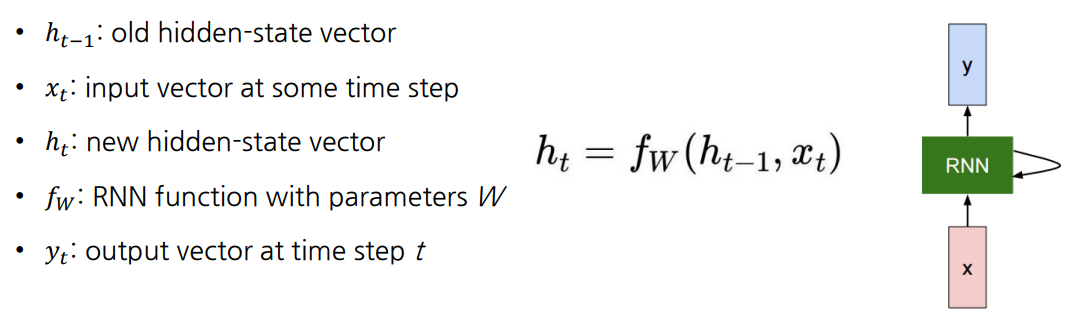
-
는 를 이용해 만들어짐
-
는 매 time step에서 필요할 수도, 또는 마지막 time step에서만 필요할 수도 있음
- e.g., 문장의 품사 / 문장의 긍·부정
-
-
parameter W는 모든 state에서 공유

-
h(hidden-state vector)의 dimension은 hyperparameter로, 여기선 의 차원을 2라고 가정
-
와 을 weight matrix W와 linear transformation을 하면 를 얻음
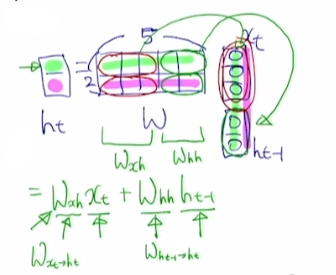
-
는 를 로 변환, 는 을 로 변환
-
위 계산을 통해 구한 값에 tanh 비선형 함수를 적용하면 를 구할 수 있음
-
추가적으로 를 구하고자 하면 로 구할 수 있음
-
binary classification 문제라면 가 1차원 scalar 값이 나와 sigmoid 함수를 적용
-
multi-label classification이라면 가 class 개수 차원의 vector로 나와 softmax 적용
-
Types of RNNs
One-to-one
- sequence data를 다루는 것이 아님
one-to-many
-
입력은 한 time step, 출력은 여러 time step
-
입력 시점 외 다른 시점에는 input과 동일한 size의 0-tensor를 input
many-to-one
-
최종 output을 마지막 time step의 hidden state에서 도출
-
감정 분석이 이에 해당
many-to-many
-
입력 출력이 모두 sequence 형태
-
machine translation
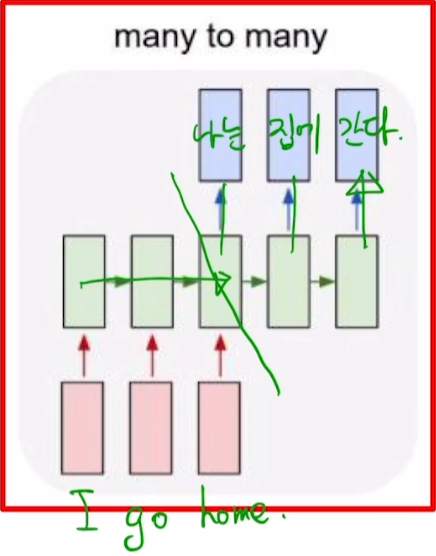
- 입력 문장을 끝까지 읽고 처리 (time step = 5)
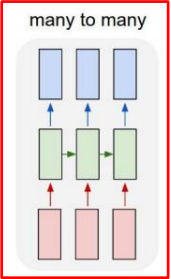
- 실시간성이 요구될 때 사용
- POS tagging과 같은 task에서 사용
Character-level language model
Language Model(언어 모델)
주어진 문자열, 단어 순서를 바탕으로 다음 단어를 맞히는 task
word-level, character-level 모두 가능
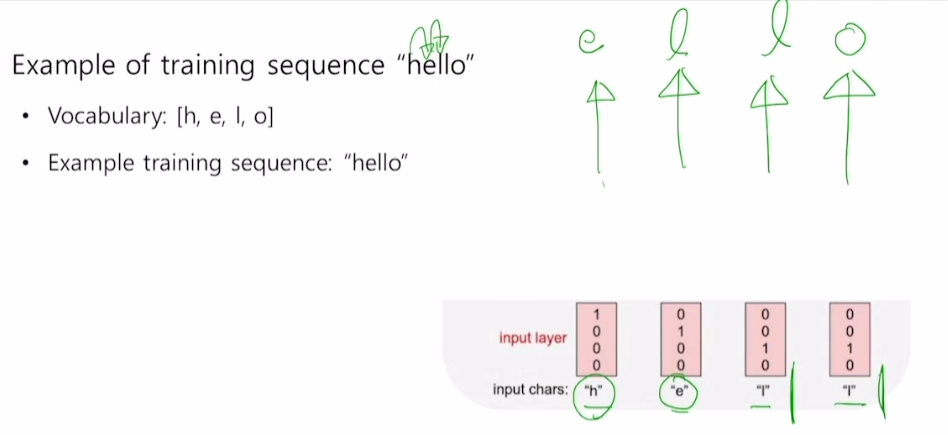
우리는 입력된 캐릭터의 다음 캐릭터를 예측해야 한다.
1) hello에 대한 vocab 구축
2) 각 character을 one-hot vector로 변환
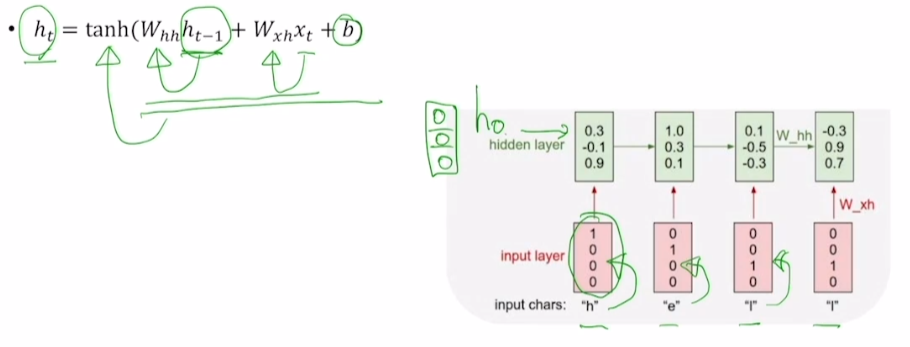
3) 이전 hidden state 과 현재 time step의 input을 와 를 통해 선형 결합 후 tanh 적용
- hidden dimension은 3으로 지정
- 이전 시점이 없으므로 은 [0, 0, 0]
- 는 정사각행렬
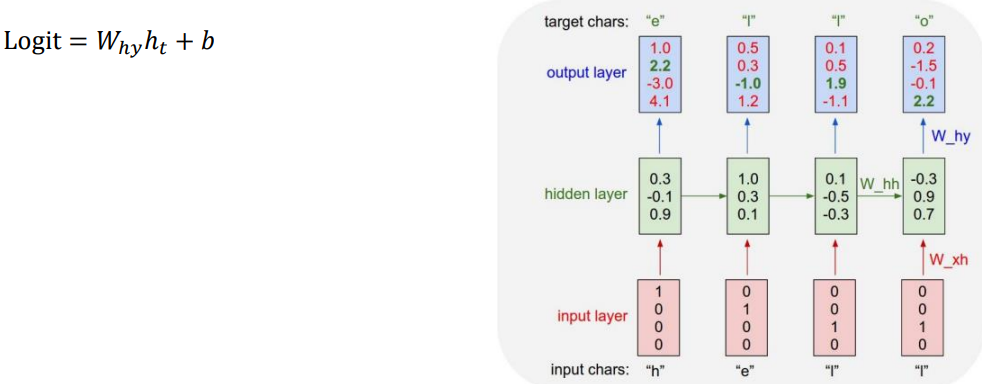
4) 앞서 구한 에 를 선형결합 한 뒤 bias term을 적용해 Logit 계산
- 현재 RNN 구조는 many-to-many이며, 각 time step마다 output을 도출
- Logit은 softmax의 input

-
해당 부분에서 target은 e [0 1 0 0]이나, output logit에선 마지막 class인 o가 가장 높은 값을 가짐
- target인 [0 1 0 0]과 인 [1. 2.2 -3. 4.1] 사이의 loss를 줄이도록 학습해야 함
Test time에서 Inference 과정
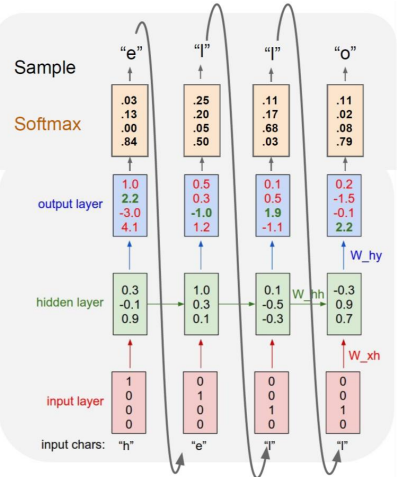
-
이전 time step의 output을 현재 time step의 input으로 넣어줌
-
공백, 줄바꿈 등도 하나의 특수문자로 처리해 vocab에 포함시킴
- 하나의 글을 한 sequence로 처리 가능
BPTT
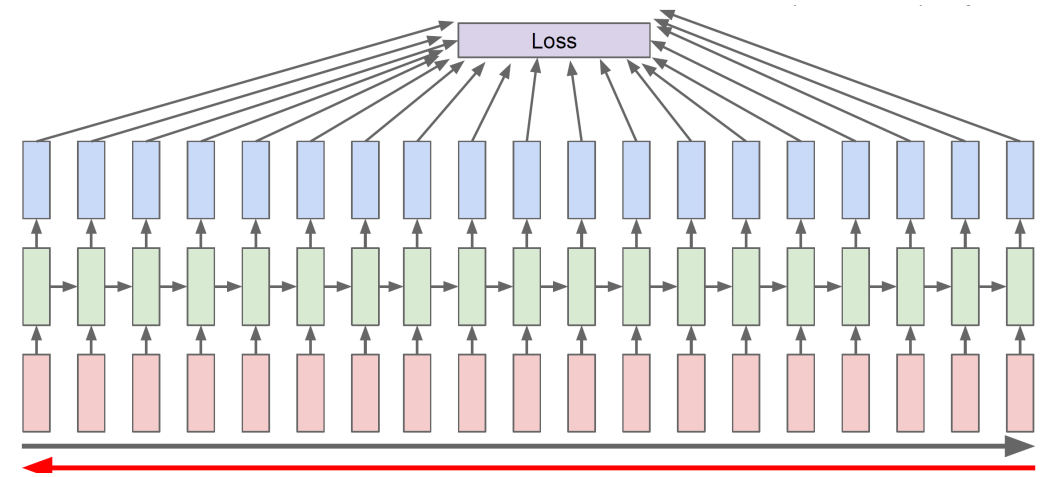
-
Loss에 대해 , , 를 update
-
sequence 길이가 너무 길면 resource가 많이 필요하기 때문에 truncated 구조로 이용
- truncated : sequence 길이에 제한을 둬 해당 길이까지만 처리
How RNN works
hidden state vector의 한 dimension을 고정하고 그 값이 어떻게 바뀌는지 관찰
- 값이 음으로 클수록 파란색, 양으로 클수록 빨간색

- 따옴표가 닫힌 후, 열리기 전 해당 dimension 값이 큰 것을 확인
- 따옴표를 감지하는 역할

- if 조건문이 시작되면 값이 커짐
- if절을 감지
Vanishing/Exploding Gradient Problem in RNN
- Vanilla RNN은 가 반복적으로 곱해지며, 그 값이 1보다 클 땐 exploding, 1보다 작으면 vanishing
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
