국내 NLP 데이터 구축 프로젝트
국내 언어 데이터 구축 흐름
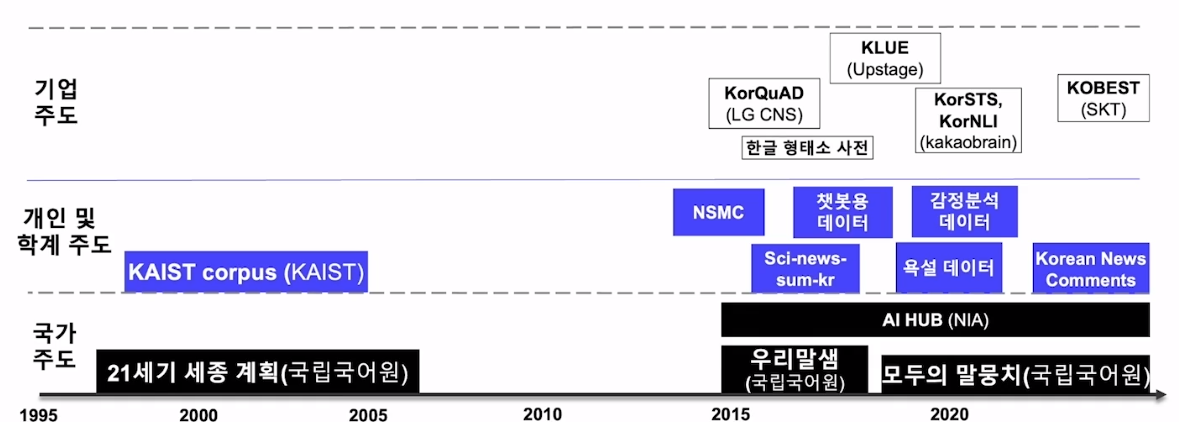
국가주도
엑소브레인
-
내 몸 바깥에 있는 인공 두뇌
-
3단계로 진행
모두의 말뭉치
- 누구나 말뭉치 개선 의견 제안 가능
우리말샘
- 누구나 자유롭게 제작, 이용하는 국어 사전
AI 허브
- 데이터터별로 데이터 설명서, 구축 활용 가이드 제공
데이터 댐
- 7개 사업으로 이루어짐
기업주도
KorQuAD (LG CNS)
- 기계독해를 위한 한국어 질의응답 데이터셋
KLUE
한국어 이해 능력 평가를 위한 벤치마크
- KLUE TC
- 뉴스 헤드라인에서 정치, 경제, 사회, 문화 등 7개 주제 분류 task
- KLUE DP
- 문장 내 의존 관계 파악 task
- KLUE NLI
- 전제가 주어졌을 때, 두 문장 유사도를 통해 가설의 참, 거짓, 중립을 결정
- KLUE NER
- 문장 내 Entity 추출 task
- KLUE RE
- 문장 내 개체 관계 추론 task
- KLUE MRC
- 질문이 주어졌을 때 답을 찾는 task
KorNLU (kakao brain)
KOBEST (SKT)
개인 및 학계 주도
NSMC
- Naver Sentiment Movie Corpus
- Naver 영화에서 크롤링한 데이터를 활용한 감정분석 데이터셋
Korean Comment Corpus
- 온라인 뉴스에서 댓글과 대댓글 수집
BEEP
- 욕설 데이터
UWordMap
- 단어의 중의성을 해석에 주로 사용
해외 NLP 벤치마크 데이터
NLP (Natural Language Processing)
NLU (Natural Language Understanding) + NLG (Natural Language Generation)
NLU는 보통 Encoder 기반, NLG는 Decoder 또는 Encoder-Decoder 기반 모델 사용
데이터셋
SNLI
- 주어진 문장들의 관계를 구분
CoNLL
- 영어로 독일어로 구성된 개체명 인식 데이터셋
TACRED
- 관계 추출 task를 위한 데이터
WMT
- 기계 번역 학회에서 공개한 다국어 번역 데이터셋
Wizard-of-Oz
- 대화 시스템
DSTC
- Dialog System Technology Challenges
- 대화 시스템 경진대회
CNN/Daily Mail
- 문서 요약 말뭉치
SQuAD, SQuAD2.0
- 기계 독해 및 질의응답 데이터
GLUE Benchmark
- 가장 유명한 영어 dataset
- 다양한 task 데이터 포함
SuperGLUE Benchmark
Gem Benchmark
- Generation dataset
Big Benchmark dataset
- 200개 이상 task를 수행하도록 하는 benchmark
- LLM 평가에 사용
Multilingual Benchmark 데이터
Timeline


NLLB
-
다양한 low resource language 포함
-
Low resource와 high resource 간의 성능 격차를 줄이기 위함
※ 영어와 같이 사용량이 많은 언어가 high resource, 네팔어처럼 사용량이 상대적으로 적은 언어가 low resource에 해당
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid