Data-Centric AI
AI Service 개발 사이클
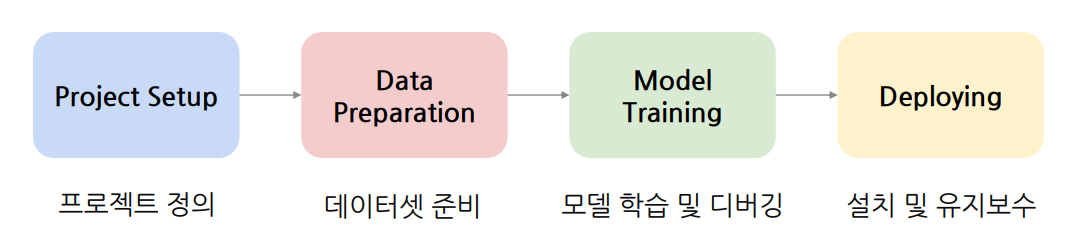
Data-Centric AI in Real-world
Data-Centric AI 정의
-
성능 향상을 위해 Data 관점에서 고민
-
Hold the Code / Algorithm fixed
-
새로운 데이터 수집, 데이터 증강, 데이터 필터링, 합성 데이터, 라벨링 방법 체계화, …
-
Data-Flywheel
- 데이터를 기반으로 모델 성능 및 데이터 quality까지 함께 향상하는 순환 생태계
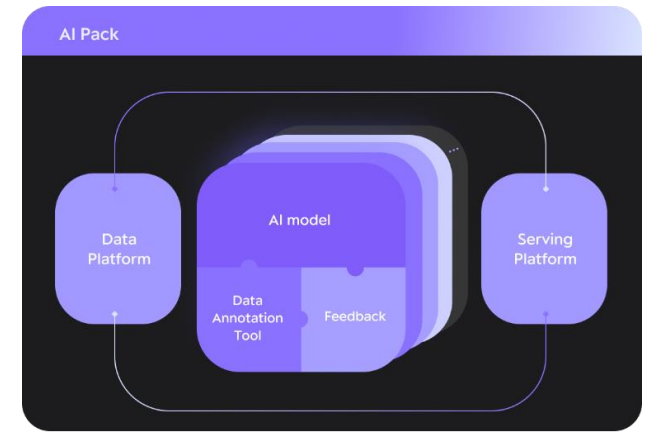
DMOps
-
Data Management Operations
-
Data Labeling Tool에 대한 연구도 진행
데이터가 고난도인 이유?
-
좋은 데이터를 많이 모으기 힘들고, 데이터는 아직 미지 영역
-
라벨링 작업에 대한 명확한 정답이 없고 비용이 큼
- label 작업자마다 가이드라인이 제공되어도 다르게 작업이 가능
-
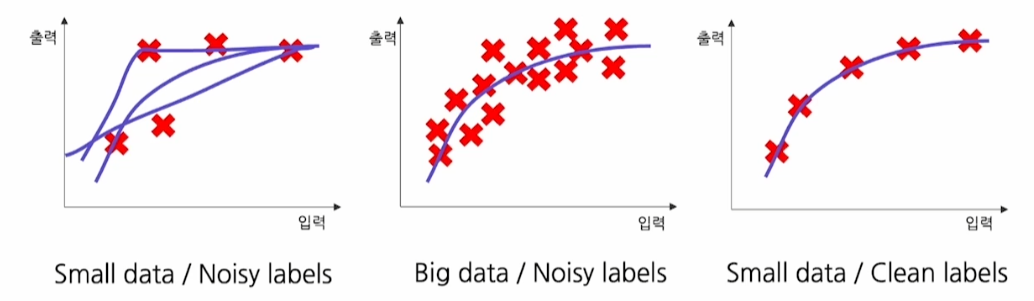
높은 품질의 데이터가 필요
- 적은 data여도 quality가 높으면 성능이 좋음
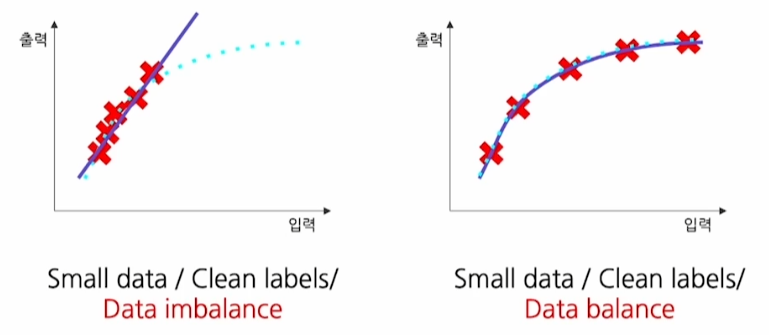
- 데이터 균형이 맞아야 함
- 적은 양이라도 데이터가 골고루 있어야 함
- 학계는 정해진 테스트셋 내에석 경쟁, 실세계에선 서비스 요구사항에 맞는 데이터가 필요
좋은 데이터란?
- 일관성 있게 라벨링 된 데이터
- annotator에게 가이드라인을 잘 제시하는 것이 매우 중요
- 중요 케이스가 포함된 데이터
- 예상치 못한 케이스까지 포함한 데이터
- 적절 크기 데이터
DataPerf
- ML 데이터 품질 향상을 위해 Data-Centric 파이프라인 주요 단계 벤치마크
- 데이터셋을 쉽고 반복 가능하게 유지 관리 및 평가
Data-Centric AI 핵심
DMOps
데이터 운영을 체계적으로 관리하며 고품질 데이터를 생성할 수 있게 하는 process
NLP 데이터 관리 프로세스에 따라 효과적으로 가이드하는 지침서 제안
일관성 있고 신뢰할 수 있는 데이터 생산 가능
절차
-
Establish the Project Goal
-
사업적 요구사항 분석
-
사용자 요구사항을 고려한 목표 설정
-
-
Secure Raw Data
-
원시 데이터 조사 및 수집
-
고객사에서 데이터 제공
-
자체적 크라우드 소싱
-
크롤링, 공공 데이터 활용
-
-
법무적 검토를 반드시 거쳐야 함
-
-
Data Pre-processing
-
원시 데이터 전처리를 통해 품질 향상
-
중복 제거, 특수문자 제거 등
-
비윤리적, 사생활 침해, 노이즈 데이터 필터링
-
-
데이터 사용에 있어 매우 중요한 작업
-
유의사항
-
구축 목적에 알맞은 데이터를 선별하기 위한 명확한 기준 수립
-
개인정보를 적절히 비식별화
-
중복성 방지
-
-
-
Design a Data Schema
-
데이터셋이 필요로 하는 정보를 모두 담을 수 있도록 주석 작업 설계
-
자동화할 수 있는 부분과 인간 입력이 필요한 부분(annotation) 분리
-
자연어처리 데이터 주석 유형
-
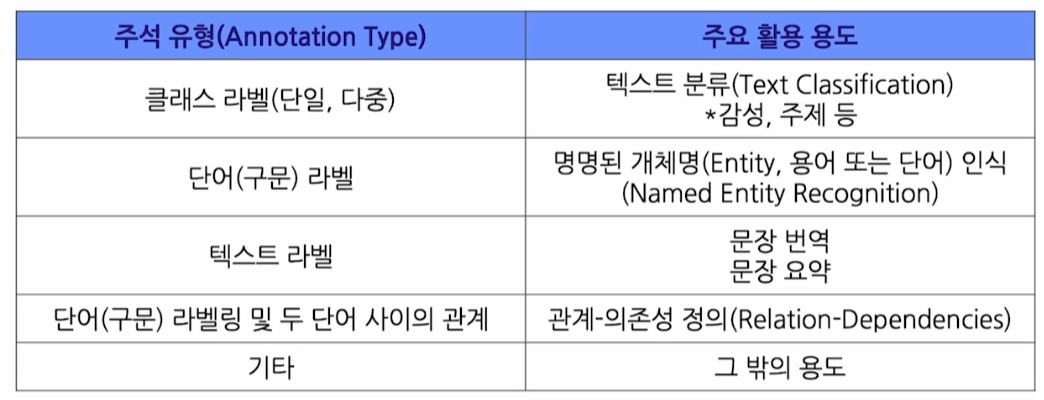
-
Prepare a Guideline
-
설계한 데이터 주석 체계를 작업자에게 전달하기 위한 문서화 작업
-
명확한 목적과 작업 방식을 담아 난이도 조율
-
-
Recruit Annotators
-
좋은 데이터셋을 만들기 위해 적합한 작업자 선정
-
작업자 특성 비교
-

-
Instruct Annotators
- 작성한 가이드라인을 작업자들과 공유
-
Data Annotation
-
실제 데이터 구축 단계
-
작업자의 직관을 데이터로 옮기는 과정
-
-
Data Inspection
-
데이터 고유 요소인 주석 자체에 대한 검증
-
Inter-annotator agreement(IAA)를 통한 데이터 일관성 확인
-
-
Data Verification
-
데이터 외재적 요소를 기반한 검증
-
전문가 평가 및 분석, 자동 평가 및 분석
-
-
Data Evaluation via Model Verification
-
실제 모델링을 통해 데이터 품질 평가
-
데이터 양을 늘려가며 데이터 효율성을 보는 실험
-
모델이 잘 추론하지 못하는 부분의 데이터를 수정하고, 더 좋은 퀄리티의 데이터로 변환
→ Data Flywheel
-
목적과 부합하지 않는 부분이 있다면 7단계부터 수정해야 함
-
-
Data Deliverables
- 데이터에 대한 정보를 모델팀 또는 유관부서에 전달
Data Annotation Tool
사람과 인공지능은 협업을 해야하는 관계 ↔ Data Annotation Tool은 둘 사이의 연결고리
- HMAT (Human Aided Machine Translation)
- 컴퓨터 시스템이 대부분 번역을 수행하고, 시스템이 번역에 어려움을 겪을 때 사람에게 도움 요청
- CAT (Computer Aided Translation)
- 사람이 대부분 작업을 수행하지만 주로 사전 및 맞춤법 검사기와 같은 리소스로 보조 컴퓨터 시스템 중 하나를 사용하는 번역 스타일
- Doccano
- 텍스트 분류, 시퀀스 라벨링, Seq2Seq task를 위한 annotation tool
Data Software Tool
CleanLab
- 데이터 일관성을 자동으로 캐치하는 오픈소스
Snorkel, Refinery, Great Expectations, ydata-profiling 등 존재
크라우드소싱
정의
- 언제 어디서든 누구나 온라인 플랫폼을 통해 데이터 작업에 참여할 수 있는 방식
과정
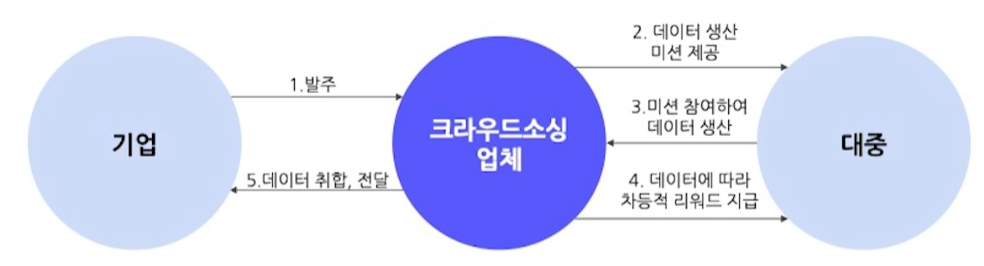
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
