[cs231n] Lecture 6 | Training Neural Networks I 리뷰
이전 강의들에서는 Neural Network의 근간을 이루는 내용들과 CNN에 대해 배워보았습니다. 이번 강의에서는 이 Neural Network를 어떻게 학습시키는지에 대해 다뤄보도록 하겠습니다.

Training 과정에 대한 Overview입니다. 이번 강의와 다음 강의를 모두 학습하시고 난 뒤 보시면 Training에 대한 전체적인 그림이 그려질 것입니다.

이번 강의는 다음과 같은 내용들을 다룰 예정이고, 다음 강의에서는 parameter update 방법 및 model ensemble 등에 대해 다룰 예정입니다.
Activation Functions

activation function은 이전에도 말씀드렸다시피, cell body에서의 계산 값을 입력으로 받아 비선형성(non-linearity)를 추가해주는 함수를 의미합니다. 이 non-linearity는 왜 필요한 걸까요?
FC layer가 여러 겹 쌓인 Neural Network를 한 번 생각해봅시다. FC layer의 출력값은 input matrix와 weight matrix간의 dot product를 수행한 값을 output으로 출력했었죠? 즉 layer에서 수행되는 연산 함수는 기본적으로 linear function이라는 의미입니다. 이 linear function을 몇 겹씩 쌓아 Network를 만들면 좋은 성능을 기대할 수 없습니다.
선형 함수들 을 가지고 아무리 합성 함수 를 만들어봤자, 이는 라는 하나의 선형 함수로 치환 가능하기 때문입니다. 이 부분이 이해가 잘 안 가신다면 linearity의 정의에 대해 검색해보고 읽어보시길 바랍니다.
아무튼 이는 Network의 비용 측면에서도 비효율적이고, Network의 layer를 아무리 쌓아봤자 성능을 향상시키기 어렵다는 한계를 만들기도 합니다.
그렇기에 우리는 layer의 출력값에 activation function을 통해 non-linearity를 추가해줌으로써, Network의 깊이가 깊어짐에 따라 더욱 복잡한 수식을 표현할 수 있도록 설계할 수 있습니다.

대표적인 Activation function들로는 다음과 같은 함수들이 있습니다. 각각에 대해 한 번 알아볼까요?
Sigmoid function
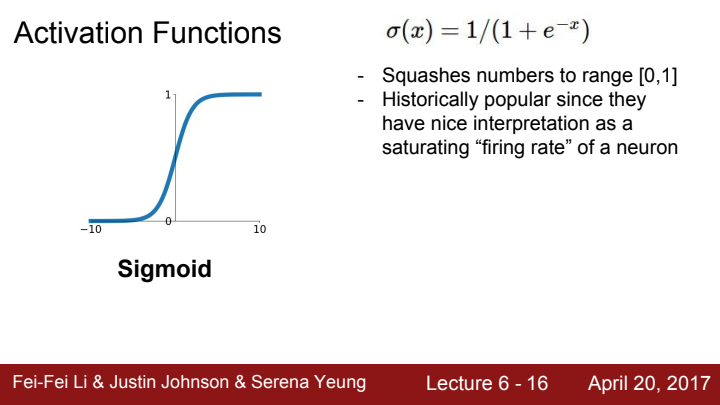
먼저 Sigmoid입니다. 이전 강의에서 backpropagation을 배울 때 우리는 이 식을 가진 sigmoid gate를 한 번 본 적이 있었습니다. sigmoid function은 그래프에서 볼 수 있다시피 치역의 범위가 0부터 1사이에 존재합니다.
역사적으로 이 s자 모양의 graph는 뉴런의 firing rate가 saturating하는 것에 대해 직관적인 이해를 도와주는 모양이라 인기있었다고 합니다. 하지만 현재 우리는 실제 딥러닝 모델을 운용할 때 activation function로 이 sigmoid를 사용할 일이 없습니다. 왜냐면 3가지의 치명적인 단점이 존재하기 때문입니다.
1. It kills the gradient
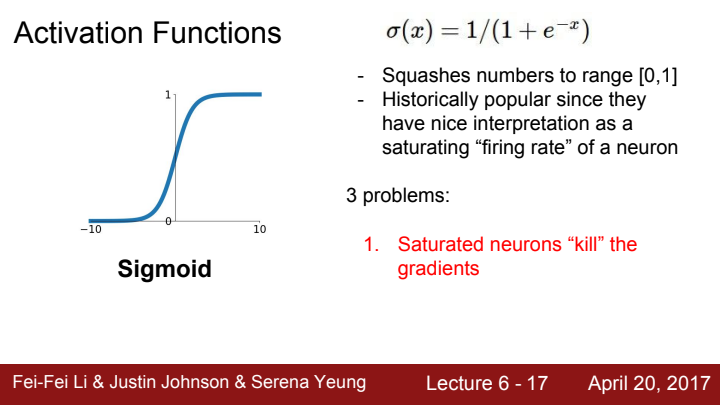
우선 첫 번째 단점으로, sigmoid function이 saturated되는 구간의 경우 gradient를 말 그대로 죽여버리는 문제가 발생하게 됩니다. 이게 무슨 말일까요?
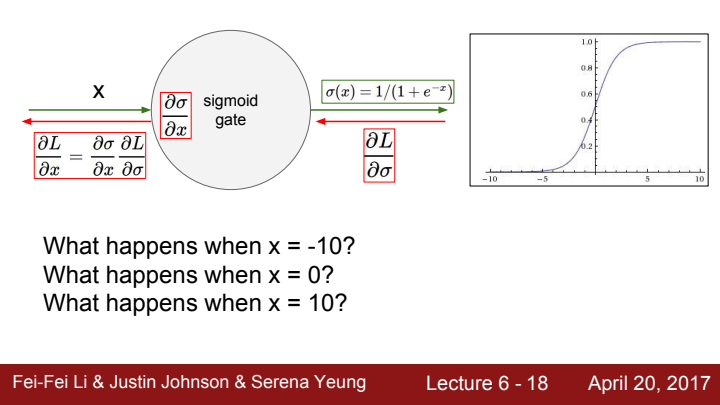
sigmoid function의 입력이 10일 때의 기울기를 한 번 생각해봅시다. 공식을 활용해도 되겠지만, 그냥 얼핏 graph만 확인을 해보더라도 기울기가 0에 근사한다는 사실을 확인할 수 있습니다.
x=-10일 때도 마찬가지로 기울기가 0에 가까운 모습이 보이네요.
이와 같이 sigmoid function은 input값이 일정 범위를 넘어가게 되면 saturated하게 되어 local gradient가 0에 가까워집니다. 이는 즉, backpropagation 과정에서 해당 sigmoid gate 이전의 gate들의 gradient값이 쭉 0에 가까운 값이 될 것이라는 의미지요. 가장 final output부터 시작해 sigmoid gate까지의 local gradient을 chain rule에 따라 곱해준 값이 upstream gradient가 될 것이고, 이 upstream gradient에 0에 가까운 값이 곱해졌으니 전체 upstream gradient 값이 0에 수렴할 것이기 때문입니다.
2. Sigmoid outputs are not zero-centered
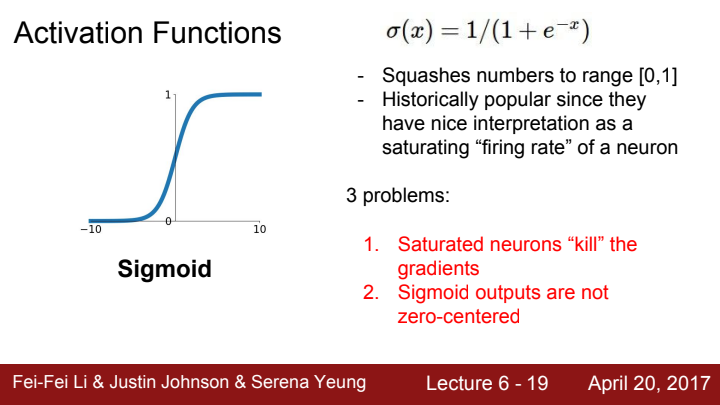
두 번째 단점은, Sigmoid function의 output은 zero-centered하지 않습니다. 고등학교 수학 스타일로 이야기해보자면, 그래프가 기함수같지 않다..? 라고 생각하셔도 될 거 같습니다. 이게 왜 문제가 될까요?

만약 뉴런으로 들어오는 모든 input의 값이 양수라고 가정해봅시다. 그렇다면 해당 뉴런의 가중치에 대한 gradient는 어떻게 될까요?
우선 뉴런의 activation function까지의 upstream gradient의 부호는 (+) 또는 (-) 둘 중 하나였겠지요? (물론 0일수도 있겠지만... 이해를 돕기 위한 예시니 일단 저 두 경우만 생각해봅시다)
가중치에 대한 local gradient를 한 번 생각해봅시다. activation function을 거치기 전 cell body에서의 연산은 단순히 weight과 input의 dot product라고 생각할 수 있습니다. 즉 mul gate 하나라고 생각할 수 있다는 거죠.
우리가 backpropagation을 공부했을 때, mul gate는 gradient switch이고, input과 weight이 1개 변수가 아닌 vector, matrix 형태일 때엔 switch된 또 다른 입력 변수의 transposed matrix가 local gradient가 된다 말했었죠?
위 수식에서 에 대한 total gradient를 구하는 과정에 가 사용될 것입니다. 근데 우리가 처음에 이 input의 element가 모두 positive하다고 가정했었죠?
그렇다면 해당 뉴런까지의 total gradient의 부호는, upstream gradient의 부호가 무엇이었는지에 따라 늘 (+), 또는 늘 (-)의 값을 가지게 될 것입니다.

위 그림은 weight이 2개의 element를 가진다고 가정했을 때의 모습입니다. 두 weight 모두 둘 다 (+) 방향으로 update 되거나, 둘 다 (-) 방향으로 update될 수 밖에 없습니다. 4사분면에서 1사분면, 3사분면 방향으로의 기울기를 가질 순 있지만, 2사분면, 4사분면 방향의 기울기는 절대 가질 수 없다는 거죠.
위 그림에서 우리가 원하는 이상적인 gradient의 update방향을 파란색 선이라고 쳐봅시다. 그냥 4사분면 방향으로의 update가 가능하다면 참 좋겠지만, 우리는 그게 안 되기 때문에 update 진행이 저렇게 zig-zag한 behavior를 가질 수 밖에 없습니다.
지금은 element가 2개 뿐이라 저 zig-zag가 그렇게 문제될 일인가 생각하실 수 있지만, weight matrix의 element는 보통 수 개, 수십 개, 많으면 수백 수천개에 달하죠? 그렇게 되면 이 zig-zag behavior를 가지고 최적의 방향으로 update를 control하는 게 훨씬 어려워질 겁니다.
우리가 activation function을 sigmoid function을 사용하게 되어 output 값이 0~1 사이의 '양수' 값으로 부호가 고정된다면, 다음 neuron에서 weight의 update가 저렇게 비효율적으로 zig-zag path를 가지게 될 수 있겠죠?
이는 activation function의 output이 zero-mean을 가지는 것이 좋은 이유이기도 하지만, input data가 zero-mean을 가져야 할 이유가 되기도 합니다. 이를 잘 기억해두세요! 우리가 Data preprocessing을 해야만 하는 중요한 이유 중 하나가 됩니다.
3. Exponential function is a bit compute expensive

마지막으로, sigmoid function에는 exponential 연산이 포함되어 있습니다. 이는 계산 비용이 단순 사칙연산에 비해 너무 비쌉니다.
에게? 고작 exponential 연산이 뭐가 그렇게 어렵다고? 싶으실 수도 있지만, 우리는 딥 러닝 모델에 쓰이는 연산의 개수가 한 두개가 아니라는 걸 늘 인지하셔야 합니다... 한 번 forward를 하는 데 하게 되는 연산의 수가 보통 수백 만개는 거뜬히 넘고, 많은 경우 억 단위를 넘기는 것도 볼 수 있거든요. 당연히 1억 번 더하기 빼기 계산만 하는 것보다 1억 번 지수함수 계산을 하는 게 비용이 훨씬 많이 들겠죠?
언급한 3가지 단점이 너무 치명적이기에, sigmoid function은 교육용으로나 볼 수 있지 실제 논문 코드나 프로젝트에서는 activation function으로 사용하지 않습니다.
그렇다면 다른 함수들을 살펴보고 어떤 함수가 많이 사용되는지 확인해볼까요?
tanh
다음으로 살펴 볼 activation function은 하이퍼볼릭 탄젠트 함수, tanh 입니다.
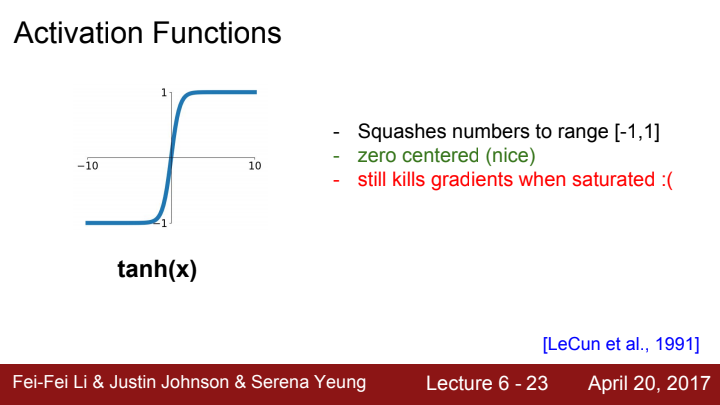
output은 -1~1 범위의 값을 가지고, 당연히 그래프 자체가 기함수이기 때문에 output이 zero-centric합니다. 나이스!
하지만 여전히 input값이 일정 범위를 넘어서면 saturated되어 gradient가 죽어버리는 현상이 발생합니다. 다른 activation function을 생각해봐야겠네요.
ReLU
다음은 그 동안 강의에서 몇 번씩 언급된 적이 있었죠? activation function 중 현재까지도 가장 많이 사용되는 ReLU에 대해 알아보도록 하겠습니다.
ReLU는 Rectified Linear Unit의 약자로, 이름만 들으면 거창해 보이지만 사실 max(0,x)입니다.
양수 입력과 음수 입력에 대한 출력값이 각각 다른 piecewise function이죠.
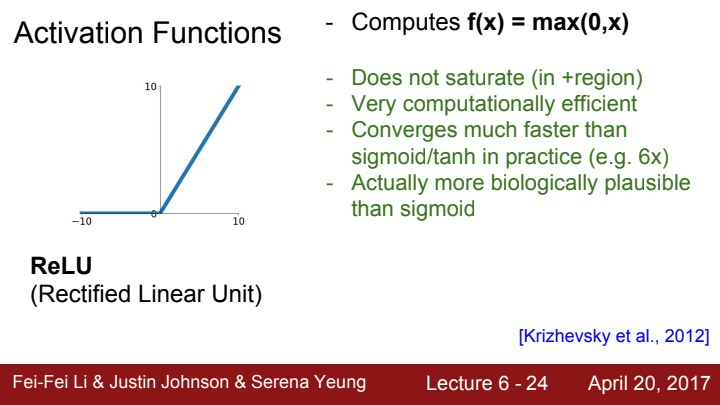
일단 input의 부호가 (+)인 영역에서 saturate가 절대 발생하지 않는다는 장점이 있습니다.
또한 함수 자체가 간단해서 계산 효율이 다른 함수들에 비해 월등하구요, sigmoid/tanh 함수들에 비해 수렴 속도가 대략 6배 정도 빠르다고 합니다.
마지막으로, 실제 뉴런과 비교했을 때 가장 비슷하고 말이 되는 activation function의 형태가 바로 이 ReLU라고 하네요.
참고로, x=0인 지점에서 그래프의 모양이 매끄럽지 않기 때문에 엄밀하게는 미분 불가능한 점이지만, ReLU 함수를 가지고 backpropagation을 할 때, 이 경우는 기울기를 그냥 0으로 계산합니다. (수학 좋아하시는 분들은 불편하시겠네요...)

간단하고 효율적이며, 가장 많이 사용되는 activation function이라지만, 그래프의 모양을 딱 봐도 단점들이 많이 보이죠?
우선 앞서 설명한 sigmoid의 세 가지 단점 중, output이 zero-centric하지 않다는 단점을 ReLU 또한 그대로 계승하고 있습니다.
그리고 두 번째로, Dead ReLU라고 하는 현상이 발생할 수 있다는 문제점이 있습니다.
Dead ReLU

만약 ReLU의 입력이 x=10일 때의 gradient값은 얼마일까요? 가 될 테니 1이 될 것입니다.
그렇다면 입력이 0이거나 음수인 경우는 어떨까요? 둘 다 이 될 테니 gradient가 0이 될 것입니다. 이는 즉 backpropagation에서, 이 ReLU gate 이전에 위치해 있는 모든 weight에 대한 total gradient가 0이 될 것이란 뜻이고, 이는 즉 ReLU gate보다 앞에 위치한 모든 weight들의 update가 중단될 것이란 의미입니다.
이렇게 ReLU 함수로 인해 gradient가 죽어버리는 현상을 Dead ReLU라고 부릅니다.
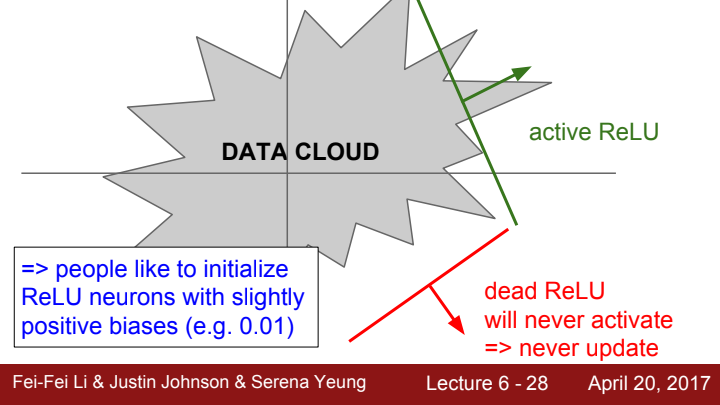
위 그림에서 Data Cloud를 ReLU 함수의 input으로 들어오는, Network의 ReLU gate 이전까지를 거쳐온 data들이라고 치고, 각 초록색 선과 빨간색 선을 ReLU의 경계선이라 생각해봅시다.
초록색 선의 경우, data의 일부가 선을 넘어 ReLU 함수를 활성화시키고 dead되지 않을 수도 있고, 일부는 선을 넘지 않아 활성화되지 않을 수도 있습니다. 이는 곧 활성화 된 일부 data들에 대한 update가 이뤄지고, 활성화되지 않은 일부 data에 대한 update는 이뤄지지 않을 것이라는 의미가 됩니다.
Q. data의 일부라 할지라도 activate되지 않아 update되지 않는다면 안 좋은 거 아닌가요?
A. 그렇긴 한데... 무조건 나쁘다! 라고 딱 잘라 말 할 수는 없을 거 같네요. 모델을 최적에 가깝게 학습시킨 결과 가 일부 data에 한해 activate를 하지 않는 것일 수도 있습니다. 효율성을 향상시키는 결과가 될 수도 있어요. 모델로 하여금 '쓸 데 없는' 정보는 무시하라고 가르치는 거랄까요?
하지만 dead ReLU가 발생한 data가 사실은 모델에게 있어 중요한 data였을 경우 말이 달라지죠. 이 경우에 해당 dead ReLU 현상은 매우 치명적입니다. 이 점 때문에 dead ReLU 현상이 큰 문제인 것입니다.
제 결론은 "data의 일부에 대해 dead ReLU현상이 일어나는 게 때론 '오히려 좋아!' 가 될 수도 있다" 입니다.
(보통 나쁜 현상이라 생각하는 게 맞긴 합니다! dead가 발생한 data가 실제로 중요한 data일지 쓸 데 없는 data인지 학습 단계에선 판단하기 어렵기에...)
이와 반대로 빨간색 선의 경우 Data Cloud와 아예 접촉하지 않기 때문에, 입력으로 들어오는 모든 data들에 대해 gradient가 소실되는 dead ReLU 현상이 발생하게 됩니다. 이 ReLU는 activate되지 못했기에 해당 Data Cloud들은 update가 되지 못하게 되었습니다.
이건 그냥 100% 문제죠. 책 펴놓고 열심히 공부시켰더니 이 모델 놈이 머리에 남은 게 하나도 없다네요. 열심히 시간 들여 노력 들여 학습시킨 보람이 없죠?
dead ReLU 현상이 발생하는 이유는 크게 두 가지,
- 가중치 초기화를 잘못 해 ReLU와 Data Cloud가 멀리 떨어진 경우
- learning rate를 너무 크게 잡아 weight을 update 하다가 어느 순간 Data Cloud와 ReLU가 멀어져버린 경우
가 있습니다.
첫 번째 경우는 학습의 처음부터 dead ReLU 현상이 발생하게 될 것이고, 두 번째의 경우 학습 초기에는 학습이 잘 되다가 어느 순간 dead ReLU 현상이 발생하게 될 것입니다.
실제로 ReLU를 activation function으로 사용할 경우 매 학습 때마다 약 10~20%의 data가 dead ReLU현상이 발생해 update가 freeze된다고 합니다. 하지만 이 정도는 학습에 크게 지장이 되진 않는다네요.
학습 너무 초기부터 dead ReLU 현상이 발생하는 것을 방지하기 위해, ReLU 뉴런에 아주 약간의 양수 bias를 추가해주는 방법도 있다 합니다.
참고로 dead ReLU를 처음 배울 때 많이 제 개인적으로 헷갈렸던 부분이, 한 input에 대해 dead ReLU가 한 번 발생했다고 해서 다른 input에 대해서도 쭉 dead ReLU가 발생한다는 법은 없습니다! input data의 정보가 달라졌으니 여러 layer를 거쳐 ReLU gate에 도달하기 직전까지의 Data Cloud도 이전과 달라져있겠죠? 이건 그냥 제가 바보라 헷갈린 거 같습니다...
ReLU Family
다음으로는 ReLU 함수와 결을 함께 하는 ReLU family들에 대해 알아보도록 하겠습니다. 모두 dead ReLU 현상을 해결하기 위해 제시된 녀석들입니다.
Leaky ReLU / PReLU
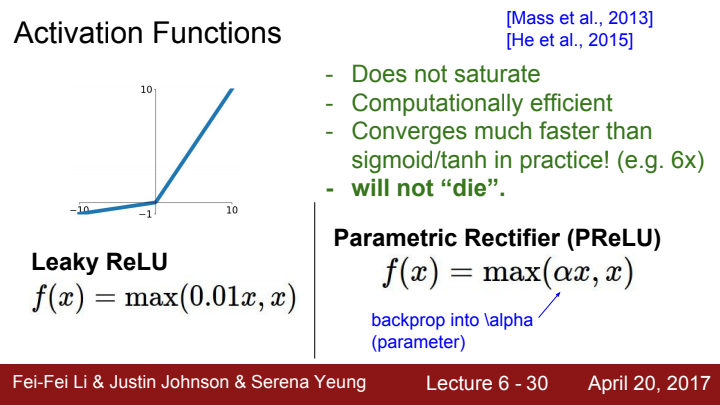
Leaky ReLU와 Parametric Rectifier(PReLU)입니다. 둘 다 input의 값이 음수가 되는 지점에서 dead ReLU가 발생한다는 문제를 해결하기 위해, 음수 부분에 임의의 기울기를 추가해 dead 문제를 해결하는 것이 목표인 녀석들입니다.
다만 둘의 차이점이라면, Leaky ReLU의 음수 부분의 기울기는 사용자가 직접 설정하는 hyperparameter이고, PReLU의 음수 부분 기울기 alpha는 학습을 통해 값이 update되는 parameter라는 점입니다.
ELU
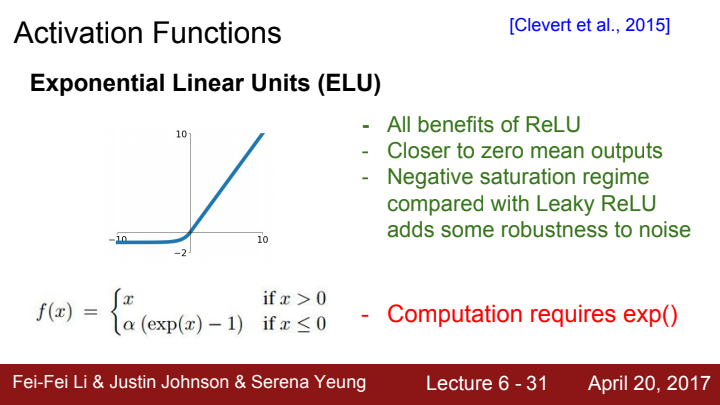
다음으로는 Exponential Linear Unit, ELU에 대해 알아보겠습니다. 입력 범위가 양수일 때엔 ReLU와 동일하지만, 입력이 0 또는 음수인 경우,
라는 함수 값을 가지게 됩니다.
일단 ReLU의 모든 장점을 계승한 바 있구요, dead ReLU 현상이 발생하지 않는다는 점과 output의 분포가 zero-mean에 가깝다는 점은 오히려 ReLU보다 낫습니다.
또한 음수 영역에서 saturation regime이 존재하는데, 이 regime의 존재로 인해 Leaky ReLU에 비해 noise에 대해 더욱 강건하다고 합니다.
다만, exp() 함수가 포함되어 있기에 계산 비용이 늘어난다는 단점이 존재합니다.
Maxout

다음은 Maxout이란 함수입니다. 일반적인 dot product의 형태를 가지고 있지 않기 때문에, nonlinear하다고 볼 수 있습니다.
input x와 dot product하는 가중치 행렬과 bias를 2개 준비한 뒤, 각 dot proudct 연산을 시행한 결과를 비교해 둘 중 더 큰 값을 output으로 삼습니다. 이로 인해 선형적인 지역이 나타나므로 뉴런이 포화되지 않고 그래디언트도 죽지 않습니다. 그러나 뉴런당 파라미터가 2배가 된다는 단점이 있습니다.

지금까지 다룬 activation function들 중 보통 어떤 함수를 사용해야 할지에 대한 정리본입니다.
일단은 learning rate를 잘 조정해준 뒤 ReLU함수를 사용해봅니다. 가장 연산이 편리하고, 생물학적으로도 가장 합리적인 activation function이기 때문입니다.
그러나 learning rate을 아무리 잘 조정해도 성능이 개선되지 않는다면, ReLU family의 함수들을 시도해 볼 만 합니다.
이것마저 성능이 좋지 않게 나온다면, tanh를 사용해봅니다. 하지만 위에 언급한 함수들이 잘 작동하지 않는다면 tanh 또한 크게 다를 바가 없을 확률이 높으니 큰 기대는 하지 마시길 바랍니다.
절대! sigmoid는 사용하는 거 아닙니다!
Data Preprocessing
다음으로는 데이터 전처리 과정(Data preprocessing)에 대해 알아보도록 하겠습니다.
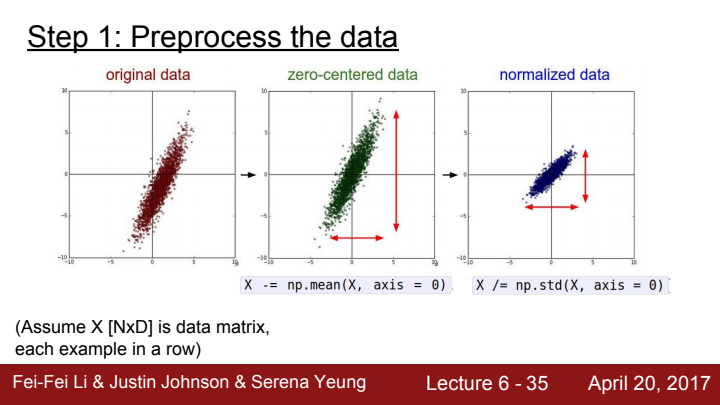
우리가 수행해볼 수 있는 가장 간단한 전처리 과정은, input data를 zero-centric, normalized하게 processing해주는 것입니다.

앞서 activation function 이야기를 했을 때, input의 data 분포가 zero-centric하지 않는다면 자칫 비효율적으로 가중치가 업데이트 될 수 있었다고 언급했었죠? 이는 activation function을 지나 다음 layer로 들어가는 data뿐 아니라, 가장 처음 Network의 입력으로 들어오는 input또한 마찬가지입니다.
zero-center의 중요성은 이제 잘 이해하셨을 것이라 믿습니다..!
앞선 페이지에선 data를 전처리할 때 보통 normalize시켜 줄 수도 있다고 했지만, 우리는 Computer Vision을 공부하는 입장으로써 image를 input으로 받기 때문에 입장이 조금 달라집니다. 이미지라 함은 이미 그 자체가 이미 기본적으로 normalize가 되어 있습니다. 어두운 밤에 찍은 사진은 보통 대부분 어두운 색을 띄고, 밝은 대낮에 찍은 사진에는 보통 비춰지는 모든 배경이 밝은 색을 띄죠?
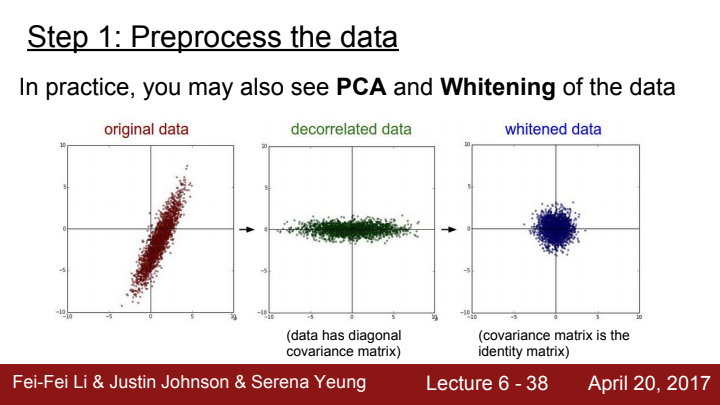

뿐만 아니라, PCA(주성분 분석)나 whitening 등의 전처리 과정을 data에 수행할 수 있다고는 하지만...
실제로는 zero-center화 시켜주는 작업만 보통 수행한다고 생각하시면 된다고 하네요.
zero-center화 시켜주기 위한 방법으로는,
- 3채널 image의 모든 element들에 대한 평균값을 구해 빼주기
- 각 채널에서의 element들에 대한 평균값을 구해 빼주기
등을 떠올려 볼 수 있습니다.
PCA와 whitening이 무엇인지는 본 강의에서도 다루지 않고 있고, 너무나 통계학적인 내용이기 때문에 본 포스트에서도 자세히 설명하지 않겠습니다. 궁금하신 분들은 검색을 통해 궁금증을 해결하시길 바랍니다 !
Weight Initialization
다음으로는 모델의 가중치를 초기화시키는 방법론에 대해 다뤄보겠습니다.
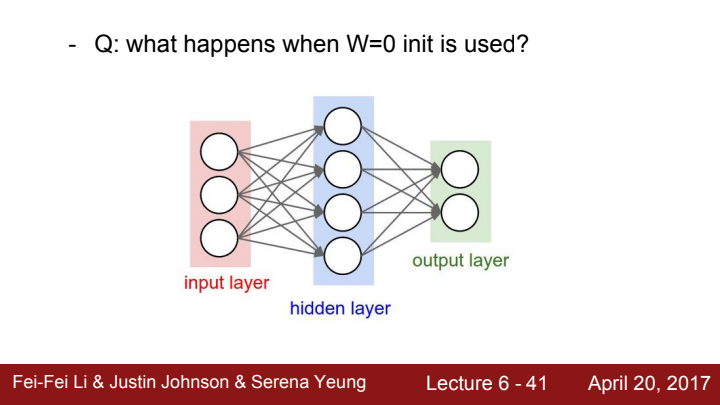
만약 모델의 모든 가중치가 0으로 초기화되었다면 어떤 일이 발생할까요? 어떤 입력이 들어오든, 같은 값을 늘 출력할 것입니다. 출력값도 모두 같고 gradient도 모두 같은 값을 가져 가중치 행렬의 모든 값이 같은 값으로 update될 것입니다. 하지만 이는 우리가 바라는 바가 아니죠? 우리는 가중치 행렬의 값이 적절하게 다른 값들로 분포되길 원해야 합니다.

이를 해결하기 위한 첫 번째 아이디어로는 정규분포를 가지는 임의의 랜덤한 작은 수들로 가중치 행렬을 초기화하는 것입니다. 이는 작은 Network에서는 잘 통하지만, 깊이가 깊어질수록 문제가 발생합니다.
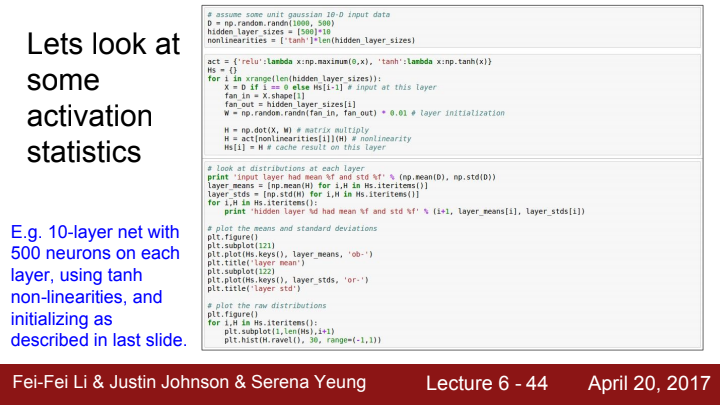
다음과 같이 10층의 layer, 500개의 뉴런으로 이루어진 tanh를 activation function으로 사용하는 모델이 있다 가정해봅시다.
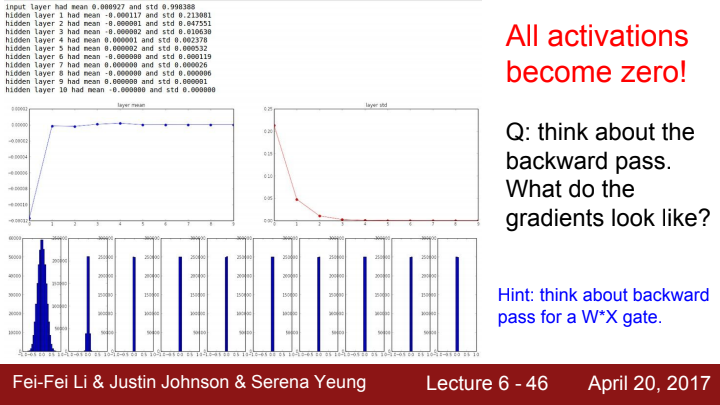
만약 앞서 말한대로, 작은 랜덤한 수로 가중치를 초기화한다면, 층이 깊어질수록 activation function의 값이 대부분 0에 수렴하게 될 것입니다. tanh는 zero-centric한 함수다 이야기 한 적이 있지요? layer의 계산은 단순히 가중치 행렬과 input의 dot product입니다. 가중치가 만약 아주 작은 값으로 초기화되었다면, layer를 거친 출력값이 tanh를 거쳐 0에 가까운 값이 될 것이고, 이 값이 다음 layer로 들어가면 아주 작은 수의 가중치 원소들과 곱해져 더 작은 값이 되고, 이게 tanh를 타고 더 작아지고... 이를 반복하다보면 최종 output의 값이 전부 0에 수렴하게 될 것입니다.
forward pass에서의 문제점을 이야기해봤으니, 이젠 backpropagation 과정에서 생기는 문제점을 이야기 해볼까요?
gate의 가중치에 대한 total gradient는 와 upstream gradient의 matrix multiplication이라고 이야기했었습니다. 아까 forward pass하는 과정에서, layer를 통과할수록 그 layer의 output이 0에 가까워진다고 이야기했었죠? 마지막 layer에서의 의 값은 그 원소들이 0에 매우 가까운 값일 것입니다. 전체 gradient의 시작 부분부터 이렇게 작은 값을 가져버리니, backpropagation을 하는 과정에서도 layer의 시작 부분으로 갈수록 gradient가 다 죽어버리는 불상사가 발생할 수 있겠네요.
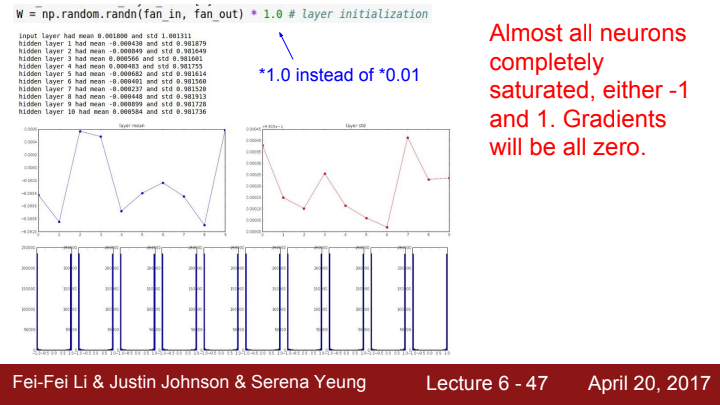
그렇다면 가중치를 작은 수가 아닌 큰 수로 초기화시킨다면 어떻게 될까요? 우리는 아까 이 모델의 activation function으로 tanh를 사용한다고 말했었습니다. 의 절대값이 만약 너무 커버린다면, saturated되어 gradient가 죽는 현상이 자주 발생하겠네요. 학습이 불가능할 것입니다.
그렇다면 어떻게 해야 가중치를 효과적으로 초기화할 수 있을까요?
Xavier initialization
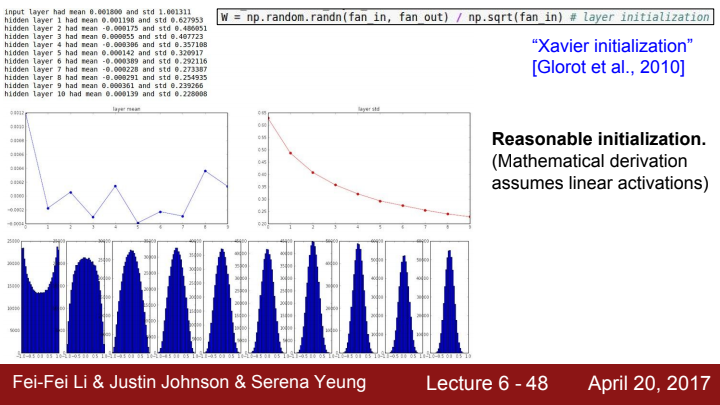
Xavier initialization은 가중치를 효과적으로 초기화시키는 좋은 방법 중 하나입니다. 정규 분포를 이루는 임의의 수로 이루어진 가중치 행렬의 원소들을, 입력으로 들어오는 수(fan-in)의 제곱근으로 나누어 scailing을 해주면 됩니다.
즉, 가중치의 적절한 분포를 찾기 위해, 앞 계층의 노드가 n 개일 때 가중치 초깃값을 표준편차가 1/√n 인 정규분포를 갖도록 설정하는 것입니다.
fan-in 값에 따라 가중치의 scailing이 결정되기 때문에, 만약 fan-in이 큰 값을 가진다면 가중치의 폭이 좁아질 것이고, fan-in 값이 작다면 가중치가 큰 폭을 가지게 됩니다.
그림을 보면 각 layer의 출력 결과가 전형적인 정규 분포의 모양을 따르는 것을 볼 수 있습니다(엎어놓은 종 모양). 즉 Xavier initialization은 각 layer의 결과가 unit gaussian이길 바랄 때 유용한 방법입니다. 물론 이러한 이상적인 결과를 얻기 위해선 linear activation이라는 가정을 만족해야 하는데요. activation function의 결과값이 linear에 가까워야 한다는 뜻입니다. layer의 output이 unit gaussian 분포를 따르기 때문에 data의 분포가 0을 중심으로 밀집해 tanh의 linear한 영역에 몰려있어 output의 형태가 linear해지는 것이죠.
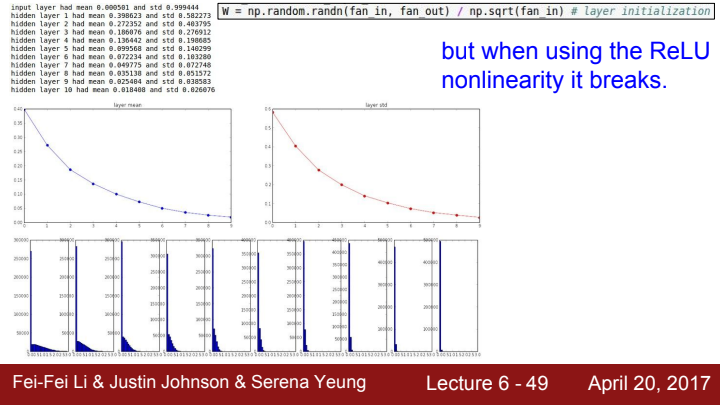
그렇기에 만약 ReLU를 activation function으로 사용한다면 dead ReLU가 발생해버립니다. 각 layer의 출력이 unit gaussian분포를 따르기에, activation function을 한 번 거칠 때마다 절반씩 값이 죽어버립니다. 이는 곧 출력값의 분산이 입력 값의 분산의 절반이 되어버린다는 의미이고, 이것이 반복되면 최종적으로 Network의 출력이 deactivate 되어버릴 것입니다.
사실 분산과 분포 등에 대한 내용은 제가 아직 확률통계에 대한 공부가 부족하기 때문에, 부끄럽지만 저 또한 완벽히 이해하지는 못했습니다. 차후 확률분포에 대한 내용을 공부하고 이 블로그에 포스트하도록 하겠습니다.
He initialization
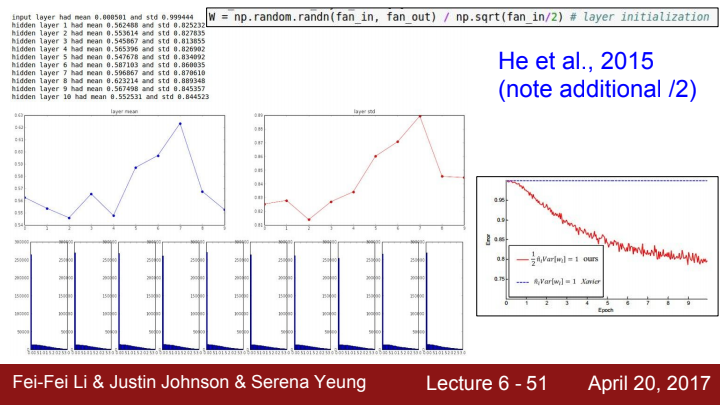
이러한 문제점을 개선하기 위한 He initialization이라는 방법이 존재합니다. 뉴런의 절반(음수 부분)이 사라지는 것을 고려하여 입력데이터의 개수를 2로 나누는 것을 Xavier initialization에 추가한 것입니다. 얼핏 보면 이게 무슨 큰 도움이 될까 싶지만, 이는 매우 견고하여 좋은 결과값을 도출해내는 것을 볼 수 있습니다.

지금까지 배운 내용들에 비해 조금 난해하고 이해하기 어려운 부분이죠? 그렇기에 강연자 분께서도 이 weight initialization은 활발히 연구되고 있는 분야라고 말씀하셨습니다. (물론 2017년 강의인지라 오래된 이야기이긴 합니다만... 지금도 꾸준히 연구되고 있을 것입니다)
Batch Normalization
배치 정규화(Batch Normalization)이란 말 그대로 각 mini batch를 unit gaussian화 시키는 것을 의미합니다. 이 unit gaussian화 된 정보들을 activation function에 태우는 것을 원할 때 사용하는 방법이죠.
각 뉴런에서 평균과 분산을 구하는 function을 이용해서 batch마다 normalization을 해주는 것인데, 이는 미분가능한 함수라서 backpropagation 과정에도 전혀 문제가 발생하지 않습니다.
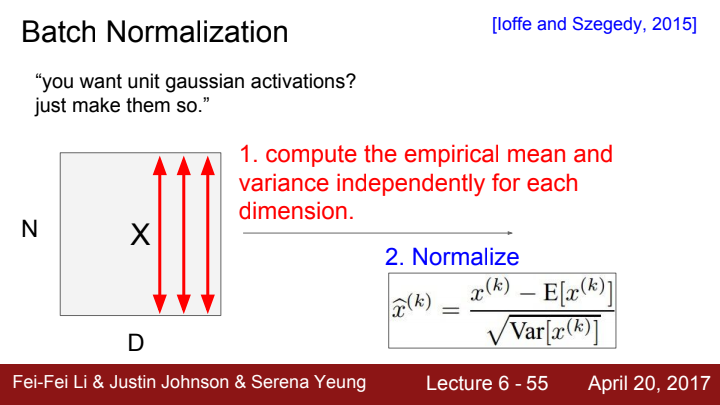
N개의 데이터를 가진 D 차원의 minibatch가 있다고 가정해봅시다
(여기선 데이터 각각이 vector라서 이렇게 표현한 거 같은데, 입력 데이터가 만약 이미지라면 4차원 데이터가 되겠지요? 실제로 torch를 가지고 image를 처리하려면 (batch size, row, col, channel) 4차원 정보를 입력해주어야 합니다)
아무튼 minibatch 속 각 data들의 평균과 표준편차를 구해준 뒤 이 값을 가지고 2번의 수식을 통해 unit gaussian화 시켜주면 됩니다.

우리는 이 BN(Batch Normalization) 과정을 FC layer나 Conv layer를 거치고 난 후, activation function을 거치기 전 사이에 진행해주면 됩니다.
FC layer나 Conv layer를 거친 값은 가중치 값에 따라 때론 나쁜 scailing이 되어있을 수 있습니다. 특정 위치의 값이 너무 튀어버린다던가 너무 죽어버린다던가 하는 식으로 말이죠. 만약 그렇게 된다면 데이터들 간의 범위가 너무 커져버려 데이터 안에서 중요한 feature가 무엇인지 파악하기 어려울 수 있습니다. 그래서 우리는 BN을 통해 그 나쁜 scailing을 없던 것으로 만들어 줌으로써 데이터 간의 분포를 줄여 중요한 feature를 더욱 잘 탐색할 수 있도록 해줍니다.
또한, 각 layer의 activation 값들이 만약 분포가 각각 제각기라면 학습이 잘 되지 않을 수 있습니다. 각 layer에서의 gradient가 예측 불가능하게 되어버려 gradient exploding이나 vanishing이 발생할 수 있다는 건데요. 이를 해결하기 위해 BN을 함으로써 각 layer를 거친 값들의 분포가 동일한 unit gaussian 분포를 가지도록 통일시켜 줄 수 있다는 것입니다.
FC layer나 Conv layer 이후 모두 BN을 사용할 수 있지만 그 형태가 조금은 다른데요, FC layer는 전체 데이터 structure가 어떠했는지 상관없이 모두 flatten시켜 vector로 만들어준 뒤 weight과 mat mul을 수행했었죠? 그래서 FC layer를 거친 후의 BN은 전체 training example을 가지고 평균과 분산을 구해 정규화 시켜줍니다.
반면 Conv layer의 경우, spatial structure를 잘 유지하는 것이 목적이기 때문에 각 activation map의 채널 단위로 독립적으로 평균과 분산을 계산하여, 각 activation map 내에서만 정규화를 시켜줍니다. activation map이 만약 6개라면, 각 activation map마다 한 번씩 총 6번 정규화 과정을 거쳐야 하는 것이죠.
위 그림에서 보면, FC layer 이후 BN을 거치고 activation function으로 tanh를 사용하고 있습니다. BN을 거친 값들의 분포는 평균이 0이고 표준편차가 1이기 때문에 input이 tanh의 linear regime에 존재한다고 생각할 수 있죠. 근데 우리는 여기서 의문이 하나 생깁니다.
꼭 tanh의 linear regime으로 input을 제한시켜야만 하는 건가요? saturation되는 것을 원할 수도 있는 것 아닌가요?
맞는 말입니다. 매 layer마다 activation function의 input이 linear regime을 통과한다하면, 그럴거면 activation function을 왜 쓰겠습니까... 우리는 모든 activation function의 input이 linear regime에 있기를 바라는 것이 아니라, 원하는 값이 잘 나올 수 있도록 saturation을 잘 control하는 것을 원합니다.

그 말은 즉슨, 모든 layer마다 Batch Normalization되는 것이 무조건 좋은 결과를 도출한다고 보기 힘들다는거죠. 그렇다고 어느 layer에선 BN을 하고, 어느 layer에선 BN을 안 하고를 manual하게 조절하는 것은 어렵기 때문에, 우리는 BN의 출력 에 대해 라는 scailing parameter를 곱해주고 라는 shift parameter를 더해주어 각 layer마다 BN을 할지 안할지를 학습시켜줍니다. 즉 저 둘은 하이퍼파라미터가 아닌 파라미터라는 것이죠!
위 그림에서 설명하고 있듯이 가 로 update되고, 가 로 update됨으로써 우리는 Batch normalization을 완전히 없던 일로 되돌릴 수도 있습니다.
어떤 layer에는 정규화를, 어떤 layer에는 identity를 부여함으로써 모델이 flexibility를 가지도록 해주는 것입니다.
에 정규화를 시켜주는 것, 그리고 에 scailing과 shifting을 해주는 것이 data의 structure를 파괴하는 것이 아니냐는 질문을 할 수도 있는데, 이 두 과정 모두 linear transformation에 해당하기 때문에 data의 structure가 변화하는 일은 일어나지 않습니다. 차후 로보트공학이나 영상처리 관련 포스팅을 하게 되면, 이 transformation을 해주더라도 유지되는 성질들을 invariance라고 하는데 기회가 된다면 나중에 다른 포스트에서 설명드리도록 하겠습니다(지금 당장 궁금하신 분들은 변환, 불변성 이라는 키워드로 검색해보시는 걸 추천드려요).

training 과정에서의 Batch Normalization을 표현하는 간단한 수도코드입니다. 우리는 BN을 통해 gradient flow가 향상하고, 더 높은 learning rate가 허용되며, 초기화에 대한 강한 의존을 줄일 수 있다는 효과들을 기대할 수 있습니다.
또한 이 BN은 일종의 regularization으로 작동할 수도 있습니다. 각 layer의 output은 뿐만 아니라 batch 내에 존재하는 다른 모든 example들의 output이라고 생각할 수 있습니다. 전체 example들을 대상으로 평균과 분산을 구해 정규화해주었기 때문이죠.
이는 output이 batch 전체에 대한 결과로 구속됨을 의미하고, 이로 인해 단 하나의 example에 대한 overfitting을 어느 정도 방지할 수 있게 됩니다.

test time에서의 Batch Normalization은 train time에서의 BN과 조금 다릅니다.
test time에는 각 batch에 대한 평균과 분산을 일일히 계산하지 않습니다. 대신에, train time에 사용되었던 empirical한 평균값을 사용하여 batch normalization을 수행해줍니다.
training 동안 사용되었던 평균과 표준편차들의 평균값을 사용한다고 생각하면 되겠습니다.
Babysitting the Learning Process
다음은 학습 프로세스를 babysitting하는 법에 대해 알아보겠습니다.
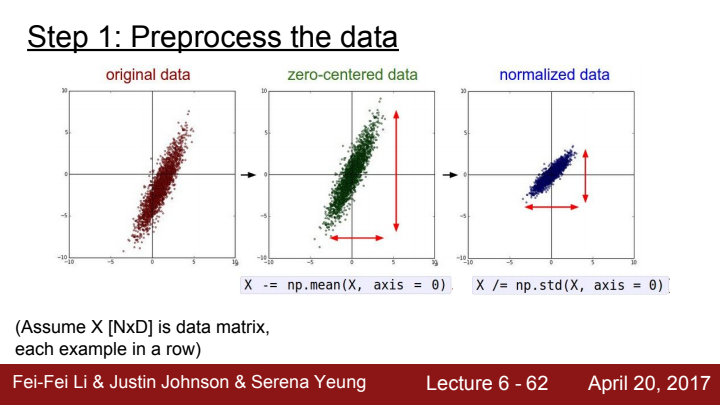
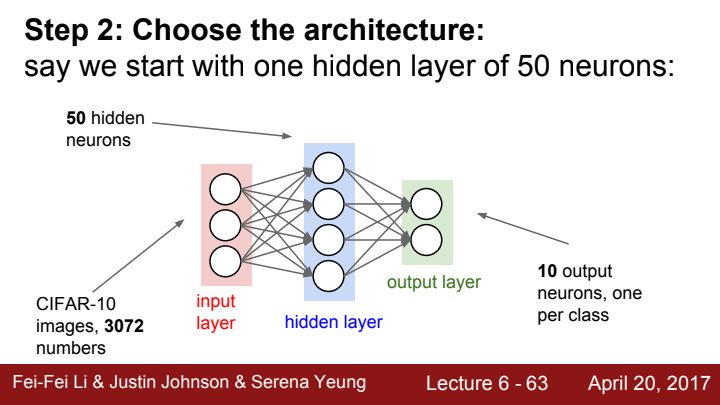

전체적인 프로세스는 다음과 같습니다:
- Data preprocessing을 해준다(image data의 경우 zero-center만)
- model의 architecture를 결정해준다.
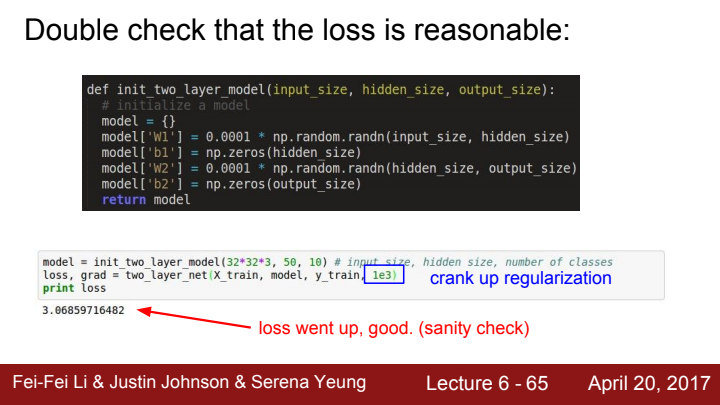
- 설정해준 loss가 reasonable한지 double check해준다.
(regularization을 설정해주지 않았을 때의 loss값에 비해, regularization term을 추가해준 모델의 loss값이 상승했다는 점에서 sanity check가 잘 되었다는 것을 볼 수 있습니다.)
- 설정해준 loss가 reasonable한지 double check해준다.
위 과정을 잘 통과했다면, train을 한 번 시도해봅시다.

일단은 아주 작은 수의 data를 가지고 모델을 학습시켜봄으로써, 해당 dataset에 대해 완벽하게 overfitting이 되는지를 확인해봅시다. epoch이 증가함에 따라 모델의 train set에 대한 performance measure 값이 매우 좋아지는 경우(Ex. Accuracy가 100%가 되는 경우), 이 모델은 학습할 준비가 되어있다고 볼 수 있습니다.

그 뒤로 작은 regularization을 설정해주고, loss값이 잘 내려갈 수 있도록 해주는 적절한 learning rate값을 실험적으로 찾아줍니다. 위 그림에서는 epoch이 진행됨에도 cost(loss)값이 크게 내려가지 않는 모습을 보여줍니다. 이는 learning rate, 즉 step의 보폭이 너무 작다고 생각할 수 있는 것이죠.

우리는 위 그림에서 무언가 이상한 점을 발견할 수 있습니다. epoch이 진행되도 cost값은 거의 변하지 않은 반면, train set과 val set에 대한 accuracy값이 20%까지 증가했다는 점인데요. 어떻게 이게 가능한 것일까요?
우리는 classification task에서 softmax classifier를 사용하고, loss function으로 Cross entrophy를 사용했던 것을 기억하실 겁니다.
j번째 클래스의 Softmax =
(s: 각 클래스의 score function, K: 클래스의 개수)
Cross Entrophy
Loss function을 계산해 backpropagation을 할 때엔 정답 클래스와 오답 클래스의 score의 절대적인 값이 중요합니다. 하지만 accuracy를 판단할 땐 각 클래스의 softmax 값들 중 가장 큰 값을 가지고 판단하기 때문에 이런 결과가 발생할 수 있는 것입니다. 확률 분포가 diffuse되어있어 loss가 잘 변하지 않지만, 모든 확률들이 조금씩 right direction(올바른 방향)으로 shift되어가고 있기 때문에 정확도가 jump한 것입니다.
예를 들어 한 이미지에 대한 10개 클래스의 softmax function의 결과값들이 [0.11 ,0.1, 0.1 ... 0.1, 0.09]였다고 가정해봅시다. '1'(1번 element)이 해당 이미지의 label이라고 치구요.
절대적인 값으로 보았을 때 정답일 확률을 고작 11퍼센트로 예측하는 모델은 학습이 많이 부족한 상태입니다. 우리의 목표는 이 모델이 해당 element에 대한 확률을 100퍼센트에 가깝게 맞출 수 있는 능력을 가지도록 하는 것입니다. 그렇기 때문에 loss function의 값이 현재 매우 높은 상태이고, 학습을 거쳐 cost 값이 낮아지도록 학습시켜야 합니다.
반면, 모델의 Accuracy를 따질 때는 어떻게 해야 할까요? softmax 결과값들 중 가장 큰 값이 모델의 prediction이라고 할 수 있습니다. 11퍼센트라는 낮은 확률로 답을 골랐지만 어쨌든 답이 맞긴 맞았다는 것이죠. 그래서 loss값이 큰 변화가 없더라도 train set/val set에 대한 정확도는 상승할 수 있습니다.

이전에는 learning rate를 1e-6으로 설정했었으니, 이번에는 1e6로 설정해보도록 합니다. 일단 딱 봐도 값이 너무 극단적으로 크죠?

역시나 값이 너무 크니 loss exploding이 발생해 cost 값이 NaN이 나와버리네요. cost 값이 NaN이 나온다는 것은 거의 항상 learning rate값이 너무 크다는 의미를 가집니다.

이번에는 나름 합리적인 값인 3e-3을 learning rate로 설정해보았습니다. 그러나 이번에도 cost 값이 explode해버리네요. 이 값도 learning rate로써 적절하지 못한 크기임을 알 수 있습니다.
이와 같이 learning rate의 값을 manual하게 범위를 좁혀가며 적절한 learning rate 값을 찾아나갈 수 있습니다...만 현재는 wandb를 통해 각 parameter의 gradient update 현황을 손 쉽게 파악하고 Sweep을 통해 hyperparameter의 최적값을 손쉽게 찾을 수 있습니다! wandb를 사용하는 법에 대해선 나중에 기회가 되면 한 번 포스팅해보도록 하겠습니다.
Hyperparameter Optimization

앞서 learning rate 조절할 때 말씀드렸던 내용들이라고 보시면 됩니다.
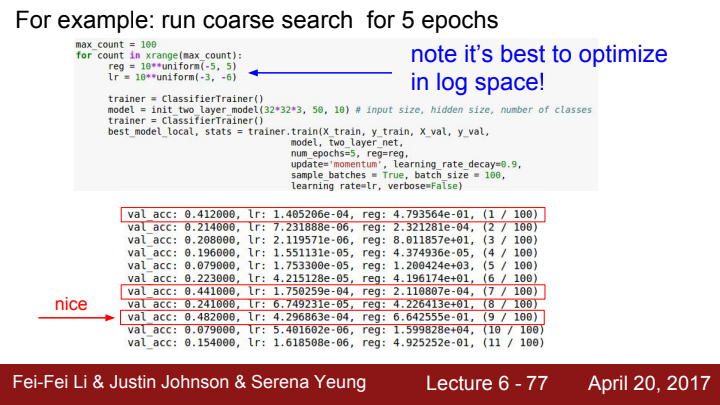
참고로 하이퍼파라미터 값을 설정할 때는 log space로 설정해주는 것이 좋습니다. 예를 들어 learning rate의 값을 ~ 으로 설정하기보다 (-3, -5)라는 10의 차수를 가지고 설정해주는 것이죠. 이러면 hyperparameter 최적화를 위해 고려해줘야 할 경우의 수가 훨씬 줄어들겠죠?

이렇게 점점 하이퍼파라미터 값의 range를 조정해가며 최적의 값을 탐색하는 것입니다.

전전 page의 48.2%라는 val acc에 비해 현재 val acc 값은 53%로 상대적으로 더 나은 성능을 보임을 확인할 수 있습니다. 하지만 이 값은 best cross-validation 결과라고 보기 어렵습니다. 왜일까요?
왜냐면 가장 높은 acc 값을 나오게 만든 lr과 reg 값이 우리가 정한 range의 거의 끝자락에 걸쳐있기 때문입니다. lr의 범위를 , reg의 범위를 으로 설정해 주었는데 lr과 reg 값이 해당 범위의 거의 끝부분에 해당하는 것이 보이시죠?
이는 해당 range에서 조금만 범위를 shift해주면 더 최적의 값을 찾을 수도 있을지 모른다는 의미가 됩니다. 우리가 지향해야 할 range는 최적값이 우리가 정해준 범위의 중간 정도에 위치해야 합니다. 그래야 확실히 이 값이 가장 최적의 하이퍼파라미터임을 확신할 수 있기 때문이죠.
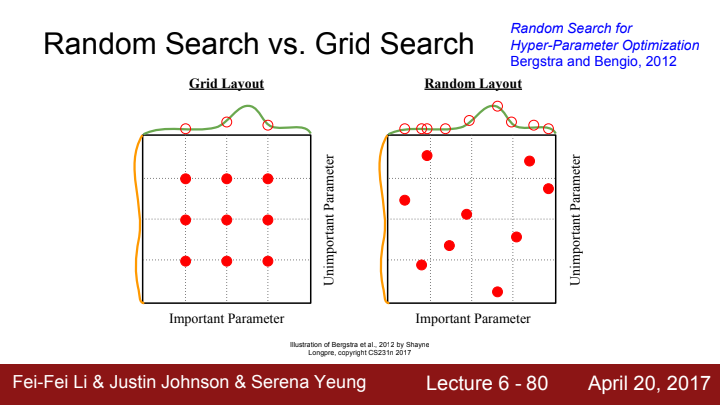
최적의 hyperparamet set을 찾는 방법에는 크게 Random search와 Grid search가 있습니다. 위의 그림에서 빨간색 점은 hyperparameter set의 sampling입니다.
왼쪽의 Grid search의 경우 sampling을 하기가 쉽지만, 점들이 일정한 간격으로만 배치되어있기 때문에 이 set이 얼마나 important한지 아닌지를 나타내주는 graph(초록색, 노란색 graph)의 정확하고 복잡한 shape을 알기 어렵습니다.
반면 오른쪽의 Random search의 경우 sampling을 말 그대로 random한 위치에 하기 때문에 green 함수의 복잡한 graph를 파악하기가 더 쉬워집니다. 즉 Random search가 Grid search에 비해 더 나은 sampling이라는 거죠.
이 이외에도 Bayes search 등의 방법도 존재합니다. Wandb에선 제가 알기론 이 3가지 방법 중 사용자가 결정해서 Sweep을 통해 최적의 hyperparameter 값들을 찾을 수 있는 것으로 알고 있습니다.

epoch이 진행되어감에 따라 loss 값이 어떻게 변화하는지를 loss curve를 시각화함으로써 판단할 수 있습니다. 오른쪽 그림에서와 같이 가장 좋은 learning rate의 경우 loss curve가 처음에는 steep하다가 점점 plateau해지는 shape을 가지게 됩니다. 이는 적절한 보폭으로 loss의 최저값에 다가가고 있음을 의미하죠.
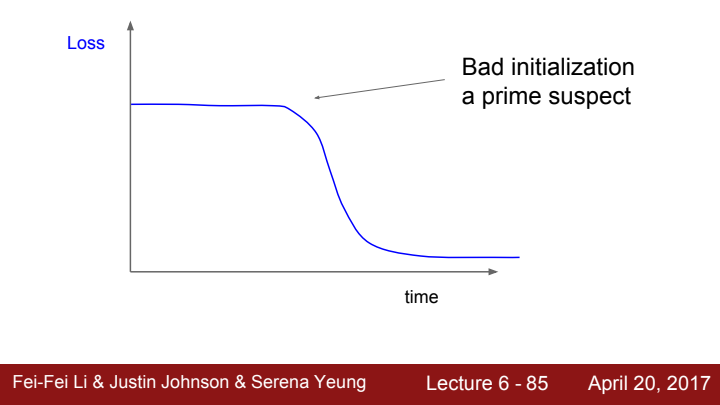
위의 그림처럼 처음에 가중치의 초기값이 좋지 않게 설정되었다면 초반 epoch에는 loss 값의 update가 거의 없다가 어느 순간 suddenly update하는 거동을 보일 수 있습니다.
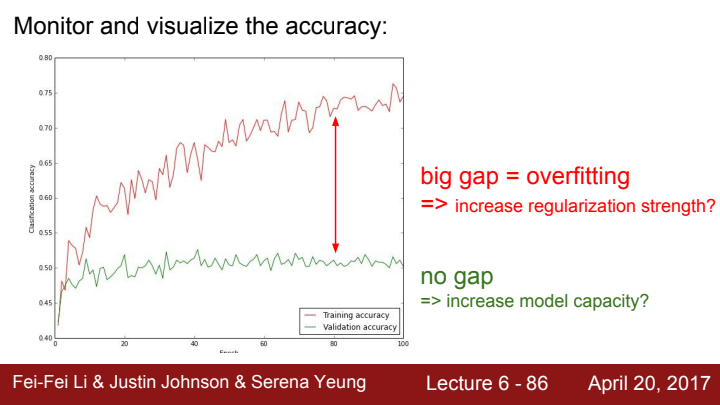
train/val set Accuracy에 대한 그래프를 시각화함으로써도 모델의 성능이나 overfitting 여부를 판단할 수 있습니다. train set과 val set의 accuracy 차이가 큰 gap을 보인다면 이는 점점 모델이 train set에 대해 overfitting이 되어가고 있다고 해석할 수 있습니다. 이 경우엔 regularization을 사용하거나 dropout, early stopping등의 방법을 사용할 수 있습니다.
반대로 train set과 val set의 accuracy에 gap이 없다면 어떨까요? 이는 모델이 지금 아주 general하게 학습이 잘 되어있는 것일 수도 있겠지만, 아직 모델의 능력이 최대치로 끌어나지 않았다는 뜻일수도 있습니다. 즉 학습을 통해 더 좋은 성능을 가질 수 있는 여지가 있다는 것이죠. early stopping이 바로 이 개념을 활용한 기술입니다. train set과 val set 간의 accuracy의 gap이 몇 epoch 이상 꾸준히 벌어지기 시작할 때 강제로 train을 멈추는 것입니다. 이렇게 해준다면 general하면서도 좋은 capacity를 가진 model을 얻을 수 있겠죠?
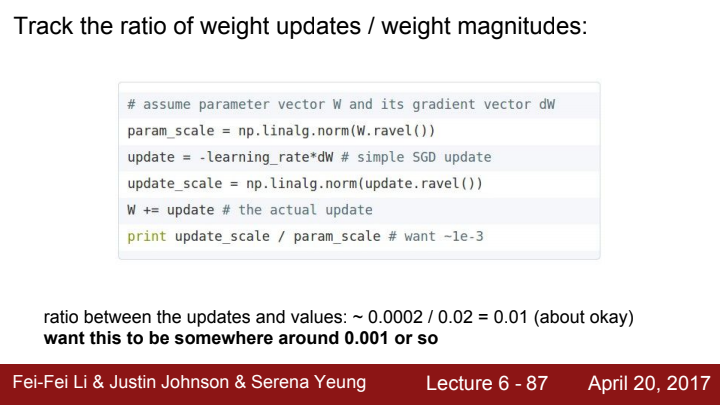
가중치의 크기에 대한 가중치 업데이트의 비율에 대해서도 따져보는 것이 좋습니다. 가중치 행렬의 norm값을 구해준 뒤 각 element들의 update해줘야 할 값들에 대한 norm을 구해 나눠줌으로써 그 비율을 계산해줍니다. 본 강의에서는 그 값이 대략 0.001정도가 좋다고 이야기하고 있는데요, 이 과정을 통해 업데이트 값의 크기가 지나치게 크거나 작은지 판단 가능하고, 디버깅에도 활용할 수 있습니다.

이번 강의에 대한 정말 간단한 요약입니다. 드디어 6강 정리가 끝났네요... 양이 너무 많아서 정리하다 멘탈이 나가버렸습니다. ㅠㅠ
다음 강의에선 Neural Network를 훈련시키는 방법에 대해 추가적으로 정리하도록 하겠습니다.
