[cs231n] Lecture 5 | Convolutional Neural Networks 리뷰
이번 강의에서는 Convolution Neural Network에 대해 배워보도록 하겠습니다.
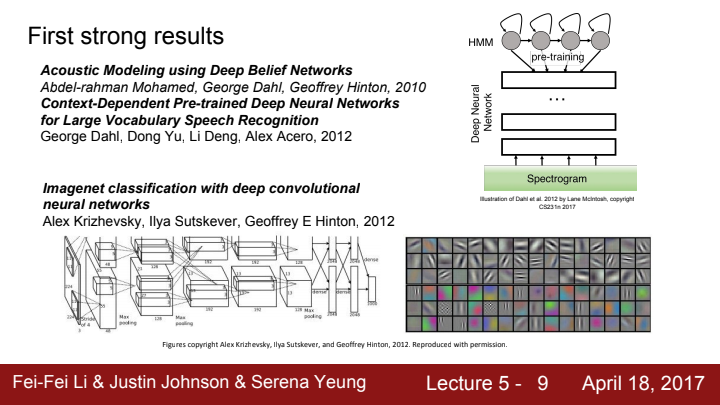
딥 러닝은 이전까지 큰 주목을 받지 못했었지만, 2012년 AlexNet의 등장을 기점으로 엄청난 관심을 받게 되었습니다. Imagenet classification challenge에서 deep CNN을 가지고 최초로 우승을 한 모델이죠.
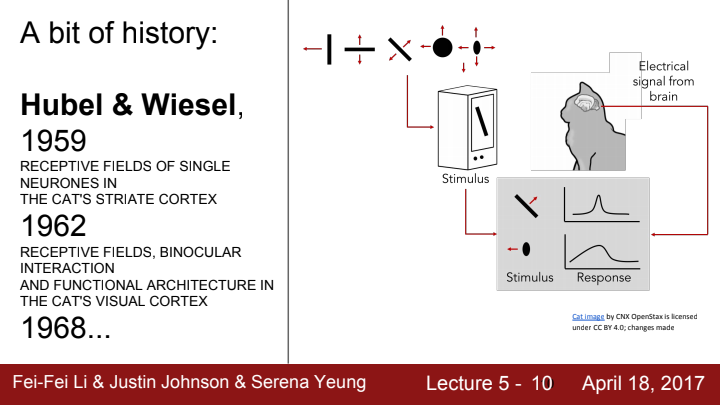
1강에서인가... 이 실험에 대해 다룬 적이 한 번 있었죠? 1강에서 위 논문에 대해 설명할 때 제가 "우리가 이미지를 인식할 때 계층적인 순서를 가지고 이미지를 차례차례 부분적으로 인식해 하나의 이미지를 이해하게 된다"라는 이야기를 꺼냈었을 겁니다. 이 "부분적으로"라는 키워드에 집중하는 것이 CNN이라는 아이디어의 출발점입니다.

시각 세포들은 각각 시야의 특정 부분에 반응을 합니다. 근접한 세포들은 곧 근접한 visual field(Receptive field)에 대해 반응을 하겠죠? 각 세포들은 서로 독립된 visual field에 대해 반응하는 것이 아니라 field끼리 겹치는 영역이 존재할 수 있습니다.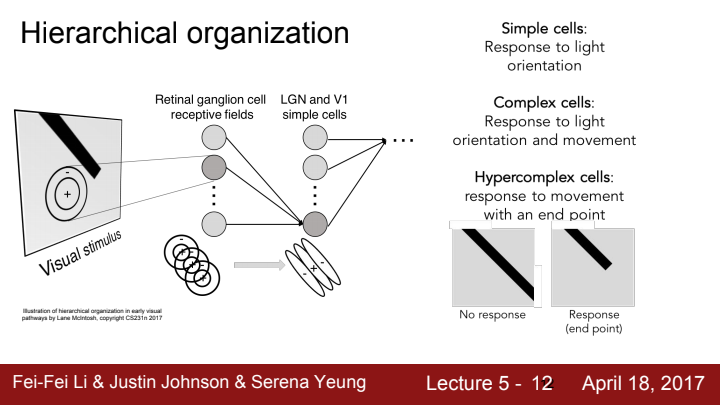
위 그림과 같이 시각을 처리하는 세포들은 계층적인 구조를 가지고 있습니다. 가장 simple한 cell의 경우 물체로부터 오는 빛의 orientation에 반응하고, 점점 cell이 복잡해질수록 movement, end point(corner, blob...)에 반응을 한다고 합니다.
즉 우리의 시각 세포는,
- 계층이 복잡해질수록 반응하는 정보가 달라진다.
- 같은 계층의 세포들은 각각 다른 Receptive field를 가지며, 각 receptive field에 대한 responce들이 모여 전체 시야 정보를 확보한다. + 인접한 receptive field끼리 겹치는 영역이 존재할 수 있다.
라고 정리할 수 있을 것입니다.
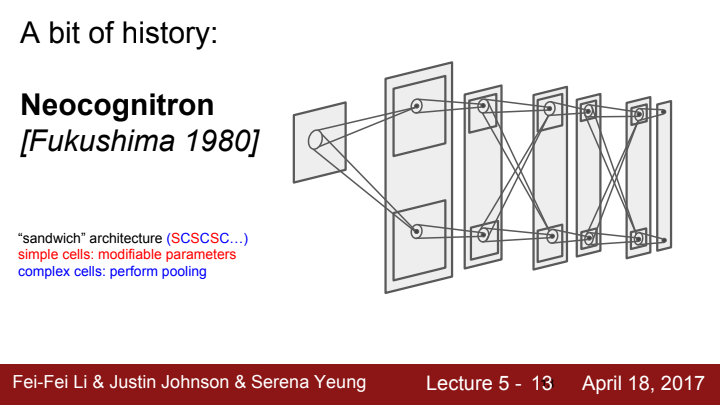
위와 같은 아이디어를 기반으로, 1998년 손글씨를 인식하는 LeNet-5가 세상에 등장하며 우리가 아는 CNN이 본격적으로 세상에 탄생하게 되었습니다.
Convolutional Neural Networks
Fully Connected Layer(FC Layer)

CNN을 구성하는 Convolutional layer에 대해 알아보기 전, 우리가 여태까지 배워왔던 FC layer에 대해 살펴보도록 하겠습니다.
FC layer는 input의 원래 spatial structure가 어땠건, 모두 vector로 flatten하는 일종의 preprocessing 작업을 거쳐 입력을 받습니다. 이후 가중치와 dot product를 수행한 후 activation function에 태운 결과값을 출력했죠.
이는 사실 feature extraction 과정에서 그리 좋은 방법이 아닐 수 있습니다. original한 input의 spatial structure를 배제한 채 image의 feature를 추출하고자 하기 때문이죠.
Convolutional Layer

FC layer와 달리 CNN에서 사용되는 Convolutional layer는 input의 spatial structure을 보존하면서 output을 출력합니다. 어떻게 그렇게 할 수 있을까요?
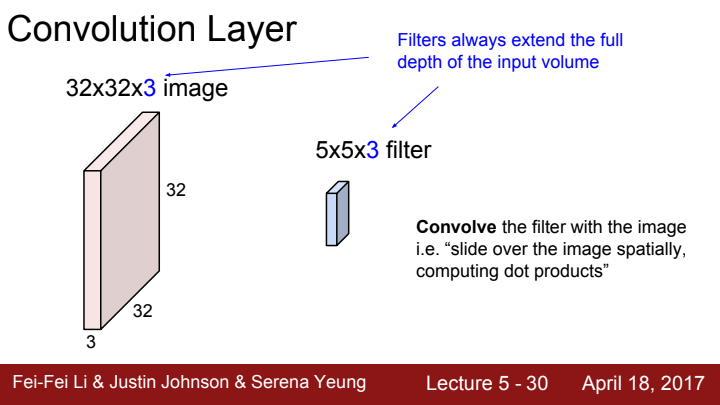
FC layer에서는 input의 모든 cell과 output의 모든 cell을 연결하는 거대한 weight matrix를 학습시켰습니다. 반면에 Convolutional layer에서는 이미지를 작은 부분부분으로 나눠 합성곱을 시켜주는 filter(=kernel)가 학습의 대상입니다.
아까 우리의 시각 세포는 같은 계층(layer)에 속한 세포들은 시각의 서로 다른 부분들을 receptive field로 삼아 반응한다고 했었죠? 이 filter가 바로 이미지의 서로 다른 부분들을 receptive field로 삼아 바라보고 반응하는 역할을 합니다.
참고로, 우리가 바라보는 이미지는 RGB 3개 채널의 matrix값을 모은 tensor라고 이야기 한 적이 있었죠? filter 또한 image의 각 채널에 대한 정보들을 서로 다르게 받아들이고 처리해야 하기 때문에 filter의 depth는 언제나 input으로 들어오는 data의 depth와 같습니다.
위 사진을 예시로 들면, filter size 5X5X3에서 5X5가 filter의 receptive field size, 3이 depth입니다.
당연히 filter가 가지고 있는 가중치 element의 개수는 5X5X3개겠죠?
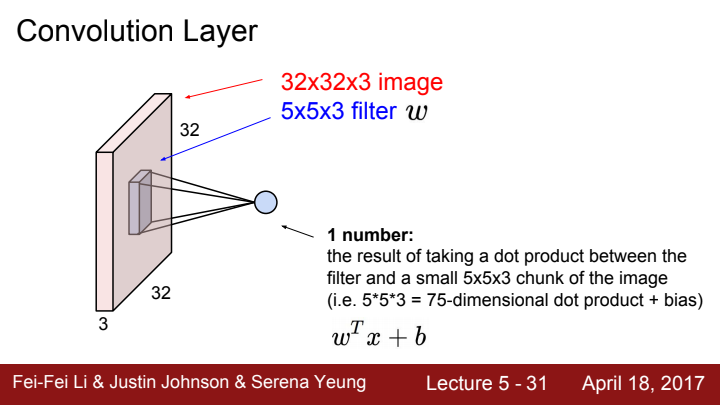
filter가 어떻게 이미지의 각 receptive field에서 output을 추출하는지를 보여주는 과정입니다. filter size에 해당하는 chunk만큼 dot product를 해주고 선택에 따라 bias를 더하는 과정을 거쳐 각 receptive field로부터 1개의 수를 출력합니다.
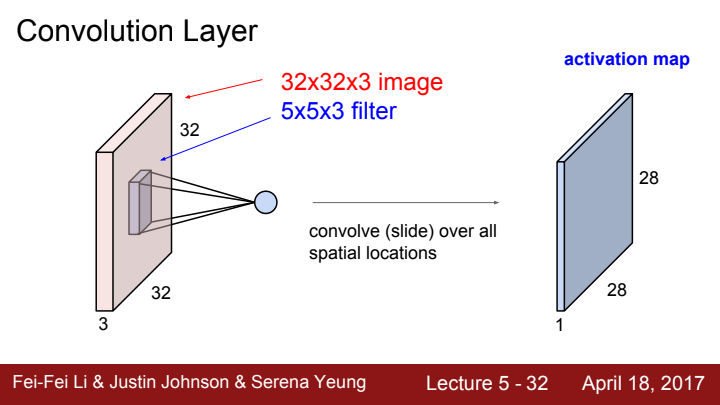
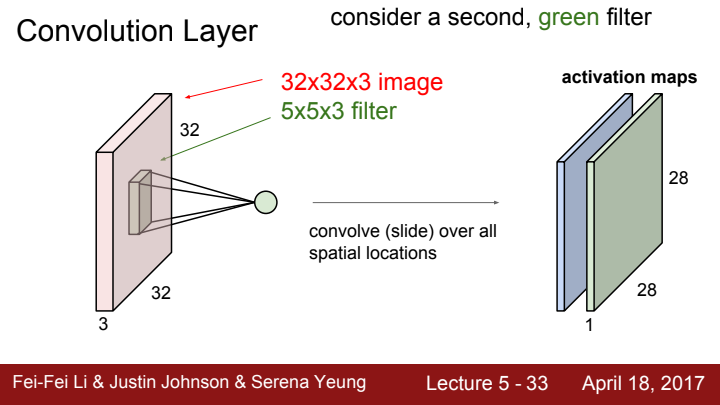
한 layer에서 filter의 개수는 하나로 고정되어있지 않습니다. filter의 개수 또한 사용자가 임의로 설정해줄 수 있는 일종의 하이퍼파라미터인데요,
한 layer에 여러 filter를 사용함으로써 각 filter마다 이미지의 특정한 concept을 찾을 수 있도록 할 수 있습니다. 물론 filter의 size도 다르게 설정해 줄 수 있습니다. 이 아이디어는 이후 배울 CNN architecture들 중 GoogLeNet이라 불리우는 모델의 inception module이라는 아이디어의 기반이 됩니다!
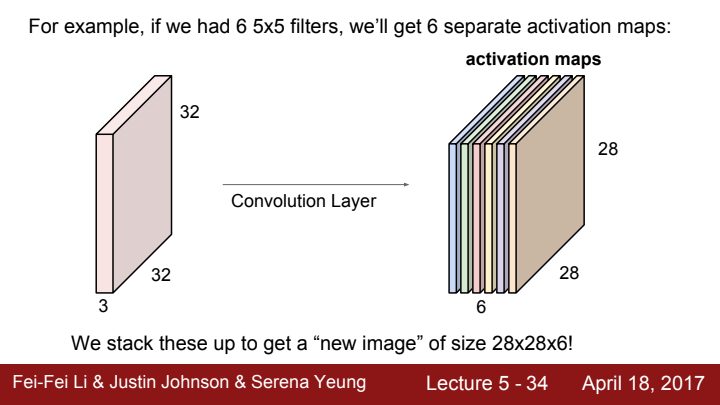
위와 같이 filter의 개수만큼 서로 다른 activation map을 얻어낼 수 있습니다. filter의 개수가 output의 channel 수(=depth)가 되는 것이죠!
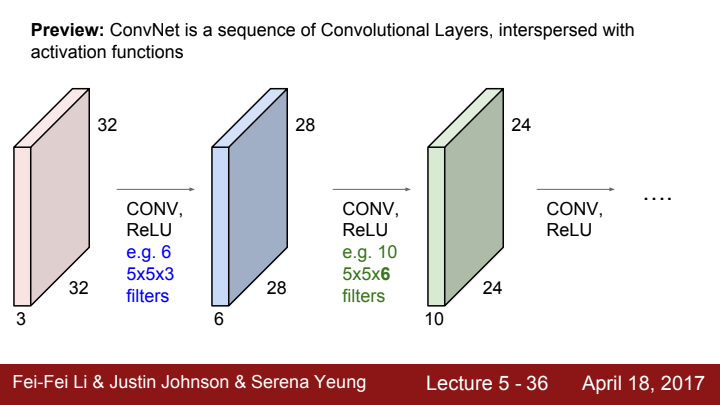
CNN의 layer를 쌓아나가는 모습입니다. 앞서 말씀드렸다시피, 한 layer의 filter의 depth는 입력으로 들어오는 data의 depth와 같아야한다 말씀드렸죠?
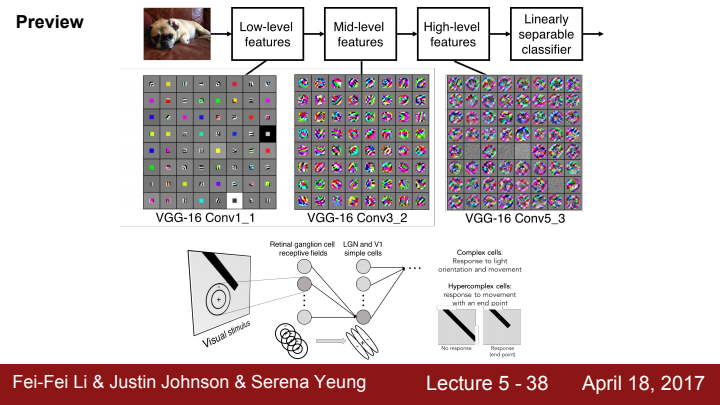
시각 지능은 계층적 구조를 가지고, 각 계층마다 다른 자극에 반응한다 했었죠? 이와 같이 CNN의 layer도 계층적으로 이미지의 feature를 바라보고 처리합니다.
위 사진의 Conv layer의 pixel에 나타난 이미지가 의미하는 바는, 각 뉴런을 최대로 activation시키는 input이 무엇인지를 도식화한 것입니다.
이렇게 이미지를 계층적으로 layer를 거치며 처리한 feature 값들을 마지막에 linear classifier에 입력해줌으로써 우리는 이미지를 정해진 category로 분류할 수 있게 됩니다.
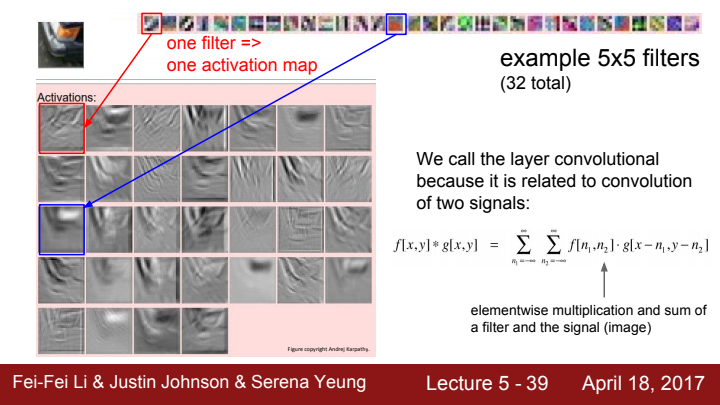
우리가 Convolutional layer라는 이름을 사용하는 이유는, filter가 receptive field의 activation map을 출력하는 계산 과정이 두 신호의 '합성곱(Convolution)' 계산 과정과 닮아있기 때문입니다.
(신호와 시스템 및 디지털신호처리 과목을 공부하게 되면 배우게 되는 개념입니다. 자세한 개념이 궁금하시다면, 합성곱에 대해 검색해보시고 천천히 공부해보시길 바랍니다)
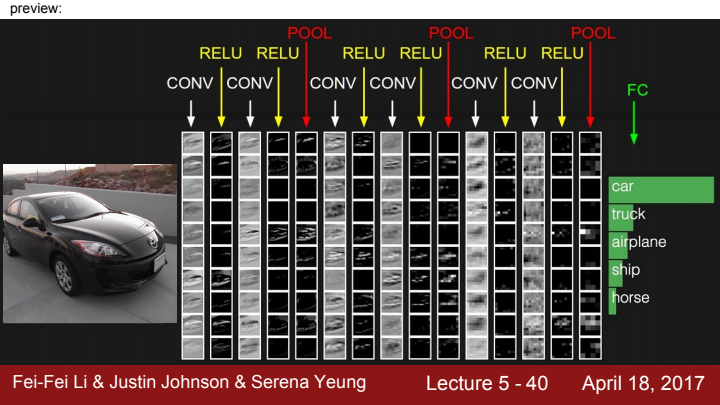
CNN을 활용한 Image Classifier의 간단한 architecture입니다. 여기서 ReLU는 nonlinearity를 추가하는 activation function이고, Pool은 Pooling layer를 의미합니다.
pooling layer는 출력 data의 size를 줄여줌으로써 다음 layer가 계산해야 할 정보를 축소시켜주는 역할을 합니다. average pooling 또는 max pooling이 주로 사용됩니다. 자세한 내용은 차후 다룰 예정입니다.
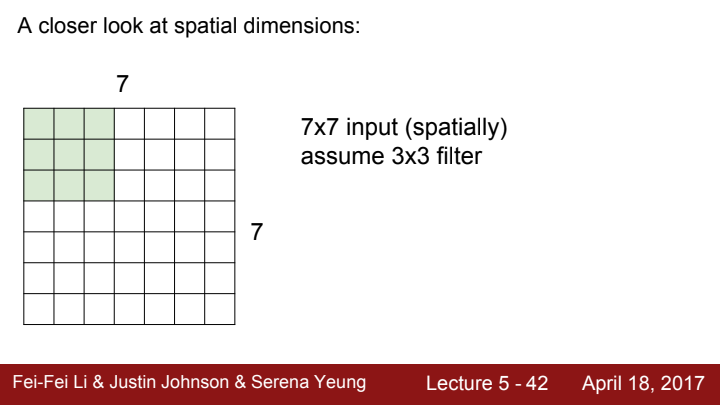
Conv layer가 연산을 수행하는 과정에 대해 조금 더 자세히 살펴보겠습니다. 3x3 size의 filter가 7x7짜리 spatial dimension을 가진 이미지 데이터를 계산한다고 생각해봅시다. 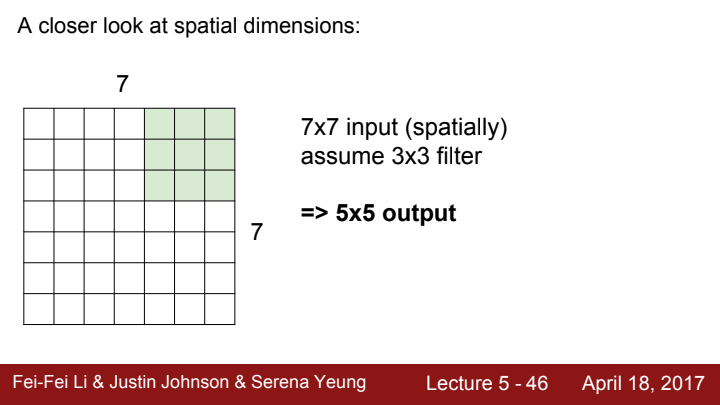
filter가 pixel 한 칸 간격으로 이미지를 탐색한다면, output activation map의 크기는 5x5가 될 것입니다.
filter가 이미지 전체를 탐색하기 위해 한 번 움직이는 간격의 크기를 stride라고 부릅니다.
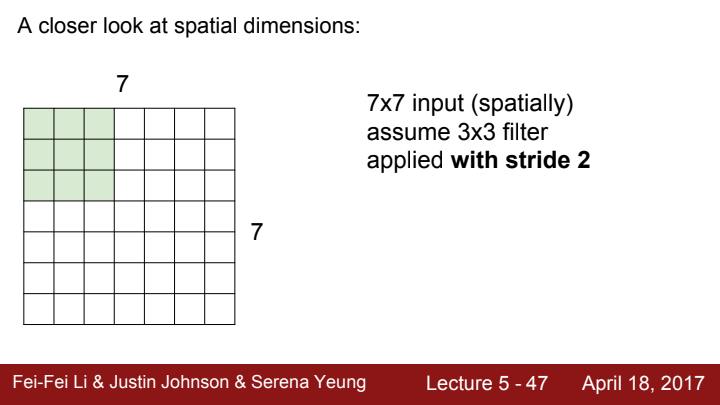
이번엔 stride가 2인 경우를 생각해봅시다. stride가 2라는 건, filter가 한 receptive field를 계산하고 난 뒤 다음 receptive field로 이동하는 간격이 2칸이라는 의미겠죠?
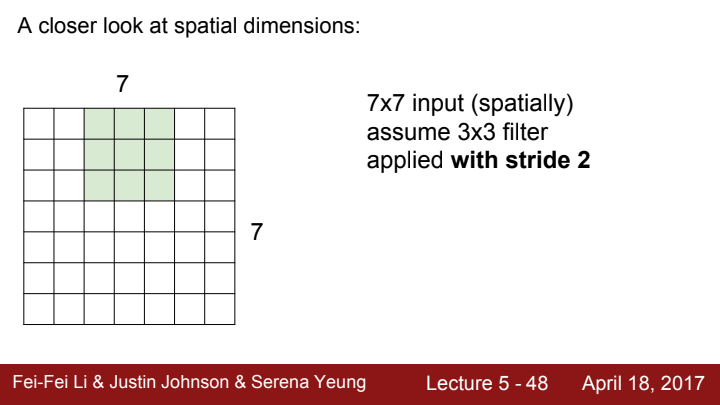
이렇게 pixel 2칸을 이동하는 모습을 볼 수 있습니다.
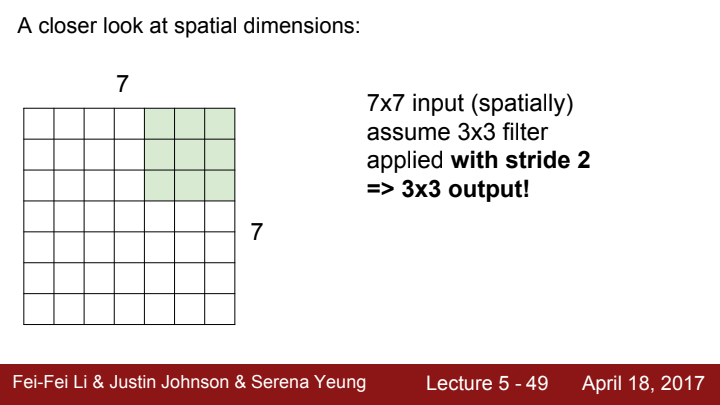
stride를 2로 설정했을 때, output activation map의 size가 3x3으로 줄어들은 것을 확인할 수 있습니다.
stride는 kernel size, 그리고 후에 배울 padding과 같이 사용자가 직접 정해줘야 하는 하이퍼파라미터입니다. 이 stride의 크기에 따라 output의 size가 크게 달라지니 잘 계산하고 값을 설정해야겠죠?

stride는 내가 원하는 숫자라면 아무 값이나 집어넣을 수 있는 것이 아닙니다!
라는 수식의 결과값이 정수로 나와야하기 때문에, 위의 경우에서 stride를 3으로 설정하면 오류가 날 것입니다.
padding

다음은 padding의 개념에 대해 다뤄보겠습니다. 7x7 size의 input의 가장자리에 1 pixel씩 0의 값을 가진 pixel들을 추가해준다면 output activation map의 size가 어떻게 될까요?
우선 추가된 pixel들의 존재로 인해 input size가 9x9로 늘어나게 될 것입니다. 앞서 배운 공식을 활용해보면 output size가 7x7인 것을 확인할 수 있죠.
이처럼 input의 가장자리에 0의 값을 가진 pixel들을 추가해주는 행위를 zero padding이라고 합니다. 앞서 설명드린대로 padding 또한 몇 pixel씩이나 pad해줄지를 하이퍼파라미터로 조정합니다.
padding은 왜 필요한 걸까요? 위 그림에서 input의 원래 size는 7x7이고, padding없이 layer를 거치게 되면 필연적으로 output의 size는 이보다 줄어들 수 밖에 없습니다. 하지만 우리가 1칸씩 zero padding을 해줌으로써 원래의 input size인 7x7이 보존되는 모습을 볼 수 있었습니다.
이와 같이 padding은 input data의 size를 output에서도 preserve하고 싶을 때 사용할 수 있는 skill입니다.
저는 딥러닝을 처음 공부할 때, 이 padding에 대한 내용이 가장 공감이 안 됐습니다. 아까는 일부러 output size를 더 줄이려고 pooling이라는 것까지 도입해놓고서, 갑자기 여기선 왜 size를 보전하겠다는 건지?
하지만 CNN의 여러 architecture들을 공부해보고, 딥러닝과 컴퓨터비전에 대해 더욱 자세히 배우고 복습하다보니 이제는 pooling도 꼭 필요하고, padding도 꼭 있어줘야 할 중요한 기능임을 이제는 어렴풋이 이해를 하게 된 것 같습니다.
딥러닝 모델의 깊이가 깊어질수록, 우리가 다뤄야 할 parameter의 개수는 늘어나고, 연산량 또한 저희의 상상을 초월합니다. 몇십 몇백만원짜리 GPU를 여러 개씩 달아놓은 컴퓨터로도 SOTA라 여겨지는 여러 컴퓨터 비전 모델들을 학습하기 위해선 짧으면 몇 시간, 길면 며칠씩 걸립니다. 이 연산에 대한 비용을 줄이기 위해 pooling 과정이 필요합니다.
padding은 그럼 왜 필요하냐고요? Convolution layer, pooling layer 모두 입력으로 들어온 데이터의 size보다 작은 size의 output을 출력합니다. 이는 다음 layer가 계산해야 할 계산량이 줄어든다는 의미이기도 하지만, 이렇게 size가 줄어들기만 하다보면 언젠간 1x1짜리 pixel하나만 남아버릴 수도 있겠네요. 과유불급이죠. 아무리 size를 줄이면서 중요한 정보를 압축한다 한들, 몇백x몇백 size의 이미지의 온갖 공간적 정보를 저렇게 조그마한 크기에 담는다는 것은 말이 안 된다고 볼 수 있습니다. 이러한 문제를 방지하기 위해서 padding 또한 꼭 필요한 과정입니다.
이것보다 더 엄밀하고 심오한 이유들이 분명 존재하겠지만, 제가 직접 딥러닝에 대해 공부하고 혼자 고민해보고, 간단한 모델들을 몇 번 직접 설계해 본 입장으로선 최소한 이러한 이유들 때문에 padding과 pooling이 꼭 필요한 기능이라 느꼈습니다.

spatial한 structure를 보존하기 위해선 보통 저렇게 stride와 zero padding 하이퍼파라미터를 설정한다고 하는데요, 뭐 무조건 저렇게 해야만 한다는 법은 없습니다. 하이퍼파라미터는 말 그대로 값을 어떻게 설정하든 내 맘이니까요! (물론 output size가 정수x정수로 나오도록은 설정해줘야 하지만요)

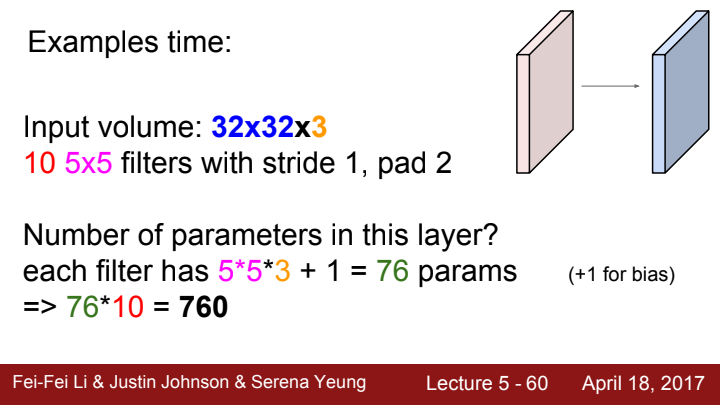
Conv layer를 거친 output의 volume과 filter의 총 parameter 개수를 계산해보겠습니다.
우선 output volume부터 생각해보죠. 제가 filter의 총 개수가 output의 채널 수가 된다고 이야기했었죠? 10개의 filter를 가지고 있으므로 일단 output channel 수는 10이 될 것입니다.
위에선 2칸씩 padding하고, stride를 1로 설정했네요. input의 size가 보존될 거라는 생각이 듭니다. 위에서 배운 공식대로니까요. filter size는 5x5고 input의 channel 수가 3입니다.
input 상하좌우에 사이좋게 2칸씩 늘려주었으니 input size가 32+2*2=36으로 늘어났을 겁니다. 여기에 filter size와 stride를 고려하여 계산해주면, 가 output의 한 채널당 가로(세로) 길이가 되겠네요.
결론으로 output의 volume은 32x32x10이 되겠습니다.
반대로 input data를 연산하는 데 쓰이는 parameter의 개수를 살펴보겠습니다. filter 하나의 volume이 5x5x3이니 filter 한 개당 parameter의 개수는 5x5x3=75개가 되겠네요. 이런 filter가 10개가 있으니 총 parameter의 개수는 750개 입니다...만
이는 filter에 weight만 존재하고 bias는 없다라는 가정 하에서만 맞는 말입니다. 이전에 bias의 존재 의미에 대해 이야기한 적이 있었죠? FC layer뿐만 아니라 Conv layer에서도 bias를 사용할 수 있습니다. 각 filter 당 bias 1개씩 추가해서 계산해주면 총 parameter의 개수는 760개가 되죠.
conv layer에선 이 bias를 통해 layer의 초기 출력값이 0을 넘게 함으로써 dead ReLU가 학습 초기부터 발생하는 것을 방지할 수도 있고... 모델 성능을 조정하는 과정 등에서 종종 유용하게 쓰입니다. 무슨 소리인지 모르시겠죠? 이후 강의에서 다루게 되니 일단은 한 귀로 흘리시길 바랍니다.

지금까지 배운 내용의 정리입니다. 참고로 filter의 개수는 2의 승수들(powers of 2)로 설정해주는 것이 좋다네요. GPU 연산과 관련해 이 개수들이 효율적이라 그렇다고 합니다. 정확한 것은 저도 공부가 더 필요할 것 같습니다.
The brain/neuron view of CONV Layer
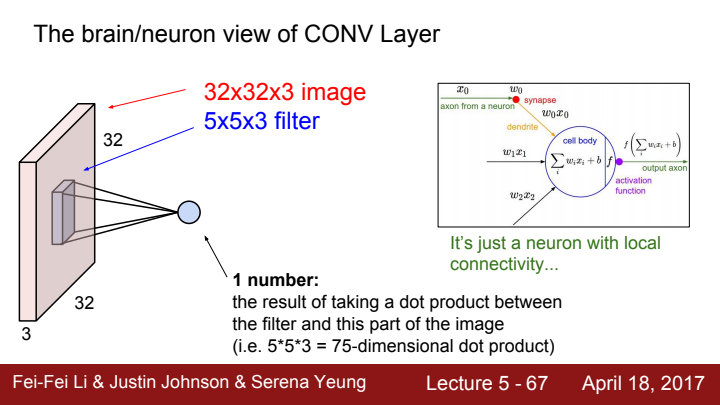
conv layer를 뇌와 뉴런의 관점으로 한 번 바라볼까요? 우리는 filter를 통해 input image의 일부분에 대한 output을 계산했습니다. 이 과정을 우리는 local connectivity를 가진 neuron이라 생각해 볼 수 있을 것 같습니다.
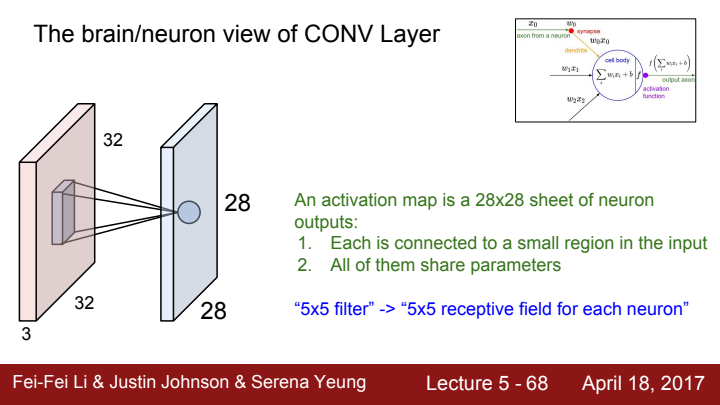
conv layer의 특징을 정리해보자면,
- input의 small region들을 차례로 돌아다니며 filter가 계산을 한다.
- 한 filter가 훑고 지나가는 모든 region들에 대한 계산에 필요한 parameter는 동일하다.
입니다. 5x5 size의 filter는 뉴런이 가지는 5x5짜리 receptive field로 치환해 생각해 볼 수 있습니다. 즉 filter 하나가 계산하는 전체 결과 값은 뉴런 하나의 전체 출력 전기 신호이고, 각 receptive field에 대한 filter의 출력값은 뉴런에 연결된 여러 수용체들이 받아오는 시야의 특정 부분에 대한 입력을 처리한 local output이란 거죠.
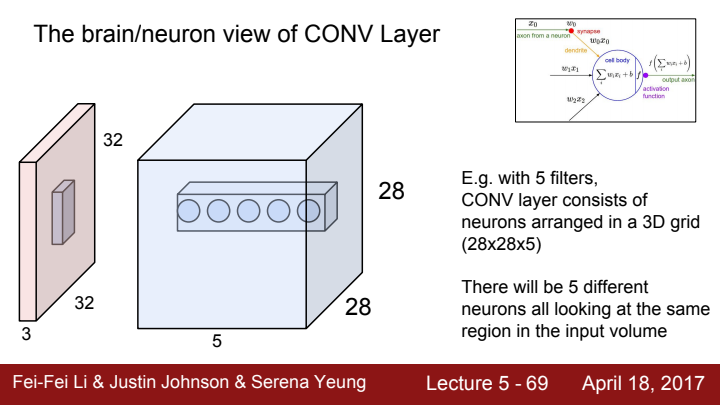
즉 filter가 5개라는 의미는 같은 계층에 존재하는 서로 다른 뉴런의 개수가 총 5개라는 의미입니다.
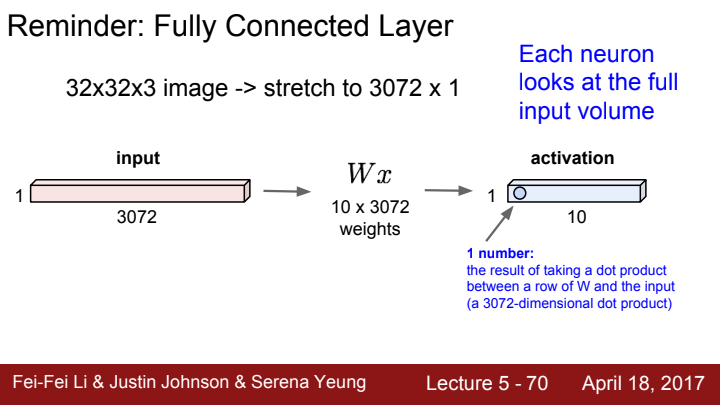
우리는 FC layer의 입력은 원래 input을 flatten하여 vector화 시킨 후 이 vector에 대한 계산 과정을 거친다고 이야기 했습니다. conv layer를 겹겹이 쌓아 이미지의 feature에 대한 계층적 정보를 수집하는 부분을 feature extractor라고 정의한다면, FC layer는 Network의 마지막에 추가되어 feature 정보를 기반으로 이미지의 category를 분류하는 classifier로 쓰입니다.
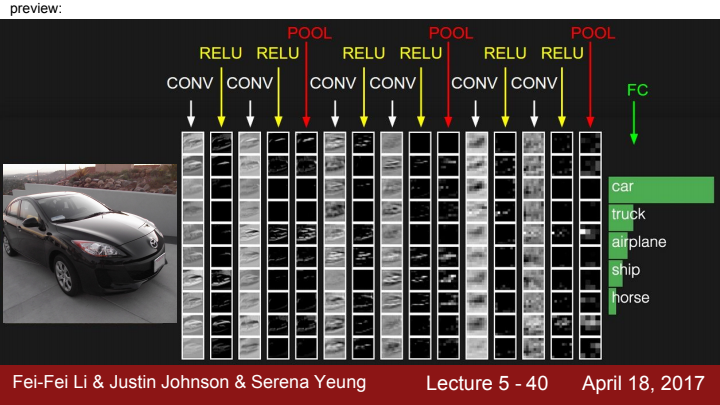
아까 위에서 한 번 봤었던 그림인데요, CNN 구성 요소들에 대해 배우고 다시 바라보니 이 이미지가 말하고자 하는 바가 이제는 정확히 보이죠?
Pooling Layer

앞서 설명드린 pooling layer에 대해 다시 자세히 설명드리겠습니다. input size를 downsampling하여 더욱 작고 다루기 쉽게 만들어주는 역할을 합니다.
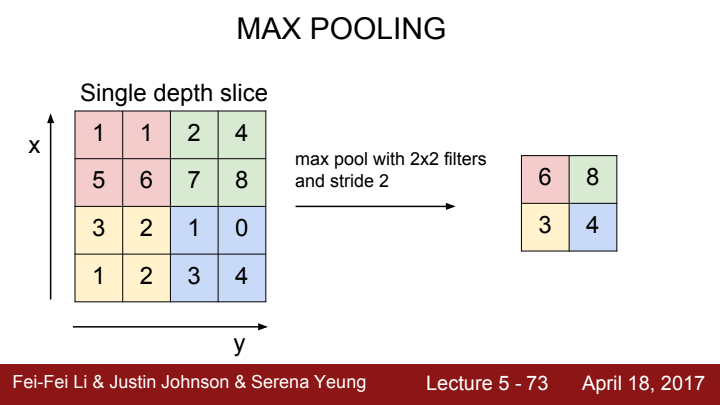
가장 많이 쓰이는 pooling으로는 max pooling이 있는데요, filter size와 stride를 정해주면 filter가 바라보는 이미지의 local region에서 가장 큰 값을 대표로써 추출해냄으로써 downsampling을 수행합니다.
Q. pooling layer의 parameter는 당연히 filter size와 동일하겠네요?
A. pooling layer는 parameter가 없습니다!! 말 그대로 각 local에서 가장 큰 값을 추출하기만 하는 역할이라 parameter가 필요할 이유도 없고 학습시킬 이유도 없습니다. 그저 정보를 압축시켜주는 역할만을 수행합니다.

지금까지 배운 내용에 대한 정리입니다. 최근(이라고 하기도 민망합니다...2017년 강의라 매우 오래되었기 때문이죠) 딥러닝 모델의 트렌드는 filter의 size를 작게 하고 layer를 깊게 쌓아올리는 것인데요. 그 이유에 대해선 차후 CNN architecture 중 VGGNet을 다루게 될 때 이에 대해 더 자세히 설명할 예정입니다.
또한 pooling layer와 FC layer 없이 conv layer만으로 이루어진 CNN architecture들이 트렌드라고 하네요(그렇다네요... 위에서 pooling이 중요하다고 제가 말했었는데 무안하네요)
CNN의 typical한 architecture는 Conv layer - ReLU block을 여러 개 쌓고, pooling layer를 거치는 더 큰 블럭을 또 여러 개 쌓은 뒤 FC layer와 ReLU를 거친 값에 softmax를 취해 최종 score를 계산한다고 하네요.
다시 말씀드리지만 이 강의는 2017년에 나온 강의이기 때문에 그 사이에 딥러닝과 컴퓨터 비전은 많은 발전을 했고, 이 강의에서 최신 트렌드라고 말하는 것들이 지금 와서는 구식일 수도 있습니다. 그러니 이 마지막 page의 내용을 너무 머리에 깊게 새겨두지는 않는 걸 추천드립니다! (저도 음~ 그렇구나 정도로만 하고 넘어갔었습니다)
다음 6,7강에선 Neural Network를 training시키는 법에 대해 본격적으로 다뤄보도록 하겠습니다.
