4.1 최적의 모델과 파라미터 찾기
4.1.1 사이킷런을 통해 학습과 예측 데이터셋 나누기
필요라이브러리 임포트
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt전처리했던 데이터셋 불러오기
df = pd.read_csv('/content/drive/MyDrive/edwith/프로젝트로 배우는 데이터 사이언스/data/datasets.csv')
df.shape
df.head()
학습과 예측에 사용할 데이터셋 만들기
from sklearn.model_selection import train_test_split
X = df[['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Pregnancies_high', 'Age_low', 'Age_middle', 'Insulin_nan', 'low_glu_insulin']]
y = df['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .2, random_state = 42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
X_train.head()
- train_test_split의 random_shuffle은 True가 디폴트. False로 주면 섞지 않고 순서대로 지정한 사이즈 만큼 할당함
- 훈련 / 테스트 셋의 shape을 확인했고, random_state를 주어 매번 같은 결과가 나올 수 있도록한다.
4.1.2 랜덤값을 고정해 DecisionTree로 학습과 예측
학습과 예측하기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = 11, random_state = 42)
model
- max_depth는 11로 깊이를 제한해줬고 state도 주어 랜덤한 부분에서 같은 일이 일어나도록 해줌
model.fit(X_train, y_train)
- max_depth와 random_state만 설정해주고 나머지는 디폴트로 만들어준 모델에 트레인 셋을 학습시킴!
성능 평가
y_pred = model.predict(X_test)
print('틀린 개수는', abs(y_pred - y_test).sum())
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred) * 100
- 이전처럼 len 구해주고 diff_count 세서 빼준 다음에 len으로 나눠서 accuracy 구할 필요 없이 sklearn의 metrics 안에 있는 매서드를 이용하면 됨
4.1.3 최적의 max_depth 파라미터 찾기
feature_names = X_train.columns.tolist()
from sklearn.tree import plot_tree
plt.figure(figsize = (15, 15))
tree = plot_tree(model, feature_names = feature_names, fontsize = 10, filled = True)
plt.savefig('plot_tree.png')
- Insulin이 가장 상위 조건으로 왔고 불순도가 0이 되는 순간까지 트리는 분기를 하고 criterion을 gini로 했으므로 gini계수가 0이 되는 순간까지 leaf가 생성
최적의 max_depth 찾기 with for loop
for max_depth in range(3, 12):
model = DecisionTreeClassifier(max_depth = max_depth, random_state = 42)
y_pred = model.fit(X_train, y_train).predict(X_test)
score = accuracy_score(y_test, y_pred) * 100
print(max_depth, score)
- for문을 이용해 3-11사이의 숫자로 max_depth를 지정해 모델을 생성하고 학습한 후에 성능을 평가한 것
- for문을 이용해 CV를 할 때 for문 안에 model 생성을 넣는 경우도 있었는데 굳이 그럴 필요 없음
- 모델을 fit 시킨 후 얻게되는 weight들이 남아서 다시 또 학습을 하는게 아니라 초기화된 상태로 새로운 데이터 셋을 학습하게 됨
- 만약 전이학습(다른 셋으로 학습시켜 얻은 모델을 그대로 가져다 씀. weight를 가져옴!)을 하는 것이라면 모델 생성할 때 sample_weight를 None이 아닌 값을 지정해주면 됨.
- max_depth = 4일 때 88%로 성능이 가장 좋음
- 깊이가 깊어질수록 성능이 낮아지는데 그 이유는 과적합때문이 아닐까 생각
4.1.4 GridSearchCV를 이용해 최적 하이퍼파라미터 찾기
5-Fold CV
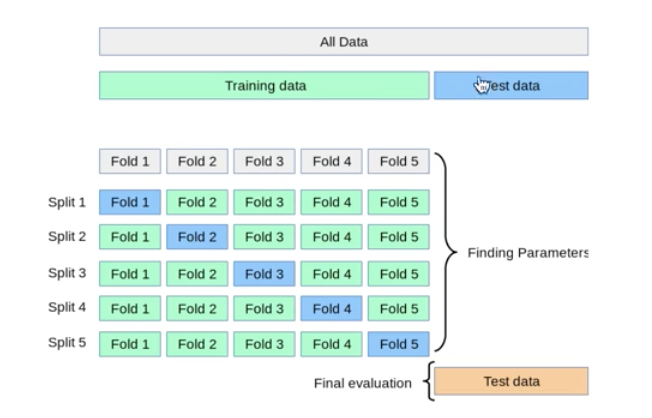
- k-fold CV는 train set에 대해 k개의 fold로 나눠 k-1개의 fold는 학습으로 1개는 test로 총 k번의 반복 학습을 통해 모델의 성능 지표를 return하고 이 지표의 평균 값으로 모델의 성능을 평가한다.
- 최종적으로 test set으로 애초에 떼어 뒀던 set으로 도출된 최종 모델의 성능을 평가!
Grid Search
- 모델의 학습과 파라미터 튜닝까지 자동으로 해주는 module
- param_grid에 parameter 조합을 넣어주면 끝
- Grid-Search는 hyper parameter 조합 별로 model을 생성해서 k-fold cv를 생성된 모델별로 다 시키고 가장 best 모델의 params, score, 최적의 모델까지 생성.
predict()를 이용해서 생성된 최적 모델로 예측을 진행!
param_grid에는 튜닝하고 싶은 파라미터 정보를 넣습니다.
max_features는 일부 feature만 사용하고 싶을 때 사용합니다. 1은 전체라는 뜻입니다.
n_jobs는 -1로 설정하여 사용 가능한 모든 장비를 학습에 이용합니다.
cv는 cross validation을 5개로 나눕니다.
verbose를 1로 하여 로그를 찍으면서 학습을 합니다. 0이면 로그를 출력하지 않습니다.
from sklearn.model_selection import GridSearchCV
model = DecisionTreeClassifier(random_state = 42)
param_grid = {'max_depth': range(3, 12), 'max_features': [0.3, 0.5, 0.7, 0.9, 1]}
clf = GridSearchCV(model, param_grid = param_grid, n_jobs = -1, cv = 5, verbose = 1)
clf.fit(X_train, y_train)-
- depth: 3-11 => 9개, features 5개 총 9*5 = 45개의 조합. 45개 조합의 5-fold cv이므로 총 225번의 학습이 진행

- best params는 max_depth = 5, max_features = 0.5. 이 때의 score는 0.89(k개의 test set의 acc의 평균)

- best_estimator엔 model이 들어있음. 이걸 이용해 predict하면 됨.
pd.DataFrame(clf.cv_results_).sort_values(by = 'rank_test_score').head()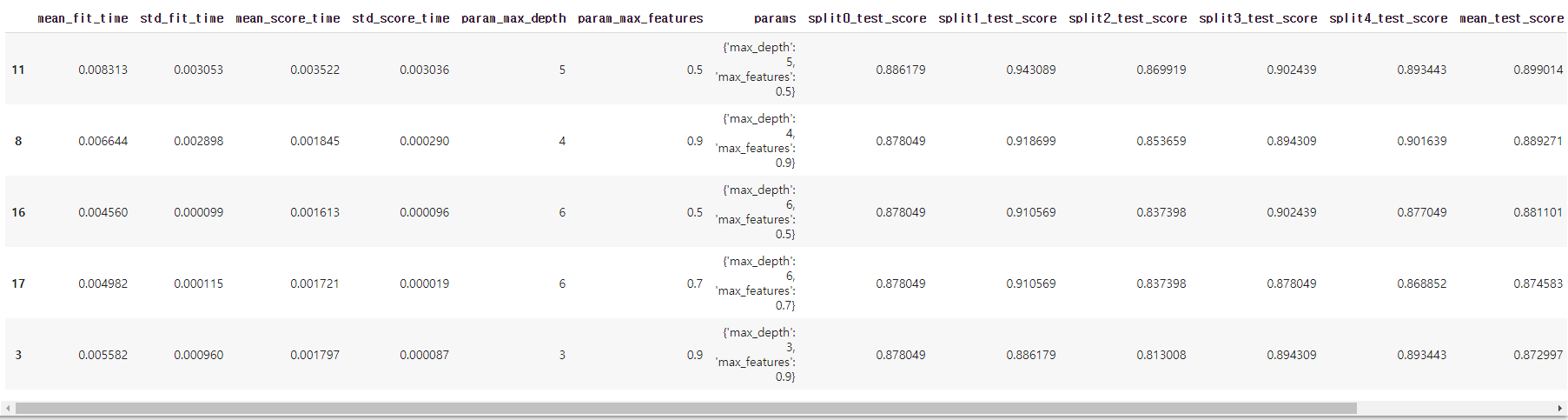
print(X_test.shape[0], (clf.predict(X_test) == clf.best_estimator_.predict(X_test)).sum())
clf.predict(X_test)
- clf나 clf.bestestimator나 똑같음. test set에 대해 제출한 답은 위와 같음!
clf.score(X_test, y_test)
- accuracy_score 함수를 이용하지 않아도 clf의
.score를 이용해 accuracy 계산 가능 - X_test에 대해 pred를 생성해서 y_test와 알아서 Accuracy 계산
- sklearn 대부분 모델엔
.score가 있음!
4.1.5 RandomSearchCV를 사용해 최적 파라미터 찾기
RandomSearch CV
- Grid Search는 설정해준 comb 내에서만 parameter를 탐색
- Random Search는 좋은 성능을 낼 수 있는 랜덤값을 탐색
- max_features는 포함하는 features의 %. 0.5면 1/2 만큼 랜덤하게 포함시키겠단 뜻
max_depth = np.random.randint(3, 20, 10) ## 3~20사이 임의의 100개 int 생성
max_features = np.random.uniform(0.7, 1., 100) ## Unif(0.7, 1.)에서 난수 10개 생성
param_distributions = {'max_depth': max_depth, 'max_features' : max_features, 'min_samples_split': list(range(2, 7))}
param_distributions
- max_Depth는 0~10 사이의 임의의 정수 난수 생성. 중복 허용
- max_features는 Unif(0.7, 1.0) 에서 난수 100개 생성
- min_sample_split은 node의 최소 sample수를 지정
- parameter를 범위 안의 랜덤한 숫자로 지정해 줌
- 하이퍼 파라미터 검색 반영이 너무 클때 사용하는 방식이 Randomized Search
- 이름 그대로 범위 사이의 랜덤한 변수들 조합을 사용하여 탐색
학습이 되어 결과가 나오는 건 GridSearchCV와 같음
파라미터 조합을 생성하는게 다를 뿐.
from sklearn.model_selection import RandomizedSearchCV
clf = RandomizedSearchCV(model, param_distributions, n_iter = 1000, scoring = 'accuracy', n_jobs = -1, cv = 5, random_state = 42)
clf.fit(X_train, y_train)
- n_iter는 n_iter만큼 반복하면서 가장 좋은 조합을 찾겠다는 것
- 1000으로 입력해서 1000번 만큼 반복하면서 좋은 조합을 찾는 것
clf.best_params_
- 최적의 파라미터. 랜덤하게 찾아낸 조합 중 최적!
clf.best_score_
- 학습에서 최고 평균 accuracy는 0.88
pd.DataFrame(clf.cv_results_).sort_values('rank_test_score').head()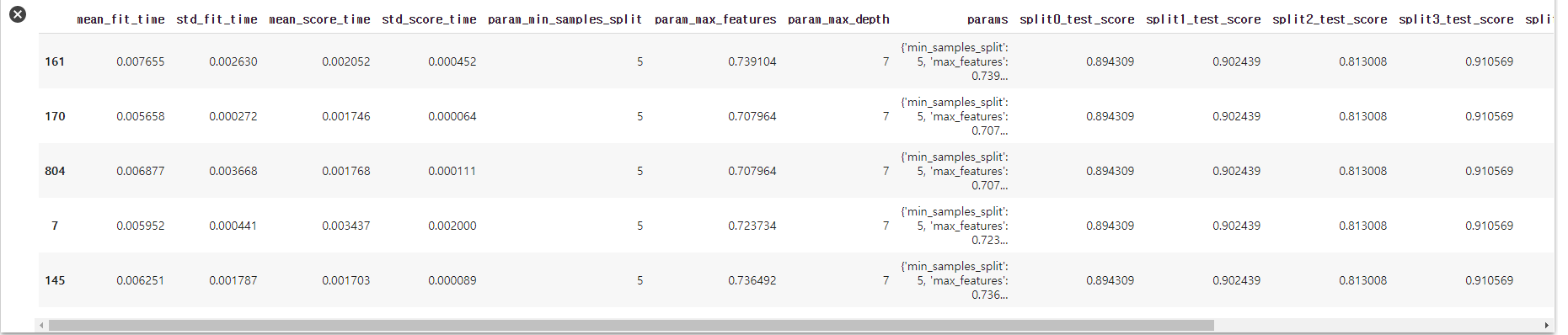
Girdsearch vs RandomizedSearch

- Grid는 직접 파라미터 값을 입력해줘야 함 -> 지정해준 범위 안에서만 최적의 조합을 찾아주는 것
그리디한 선택. 최적을 보장하진 못함. - Random은 params로 난수를 입력해주고 랜덤하게 조합을 찾아서!
- Small datasets and lots of resources라면 Grid Search가 good
- But, Lagrge datasets, high dim(param의 조합의 수가 많다면? or param이 여러개라면)
-> Randomized Search가 good - 모든 가능한 경우에 대해 학습하는게 아니라 random하게 파라미터 조합을 sampling 하기 때문에
- iter를 모든 가능한 경우의 수로 준다면 그냥 grid에 난수로 파라미터 주고 학습하는거랑 다를게 없음.
- 어찌됐건 하이퍼 파라미터 생성하고 조합하는게 다를 뿐이지 학습을 하는건 같으니까
- datasets이 조그맣고 파라미터 수도 몇개 없다면 그리드 서치로 하고
- datasets이 크고 파라미터의 수도 많다면 randomized search!
RandomizedSearch는 난수를 param list로 넣어주면 가능한 모든 조합에 대해 iters만큼 sampling을 함. sampling 된 조합에 대해 CV를 하는 것! 만약 iters가 모든 경우의 수를 넘으면 모든 경우의 수에 대해 진행. combinations보다 높은 iter는 굳이... 아무튼 가능한 모든 조합에 대해 sampling을 iters만큼 해서 CV해서 parameter 튜닝까지 하는 것
추가적으로, 임의의 범위를 지정해서 난수 생성했을 때 ex [0.4. 1.]과 같은... 만약 best params가 0.7이 많이 나왔다면 범위를 [0.7, 1.] 이런식으로 바꿔서 넣어주면 더 빠르게 최적을 찾아갈 수 있음

Data science