프로젝트로 배우는 데이터 사이언스
1.1.1 사이킷런과 머신러닝
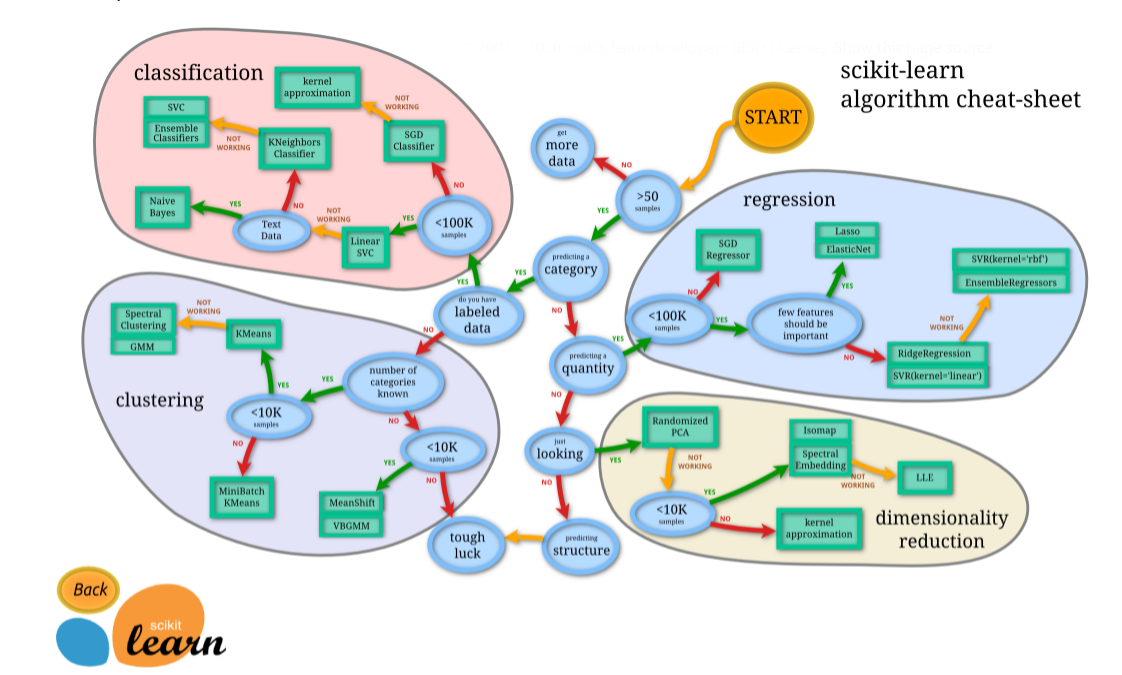
: 정답(Label)이 존재. 수치를 예측하는 것이면 Regression, 분류의 문제는 ClassificationClassification -> https://scikit-learn.org/stable/supervised_learning.htmlRegress
2.1.2 의사결정나무로 간단한 분류 예측 모델 만들기
링크: https://www.kaggle.com/uciml/pima-indians-diabetes-databasePregnancies : 임신 횟수Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도BloodPressure : 이완기 혈
3.2. EDA를 통해 데이터 탐색하기1

Pregnancies : 임신 횟수Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도BloodPressure : 이완기 혈압 (mm Hg)SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값Insulin
4.2. EDA를 통해 데이터 탐색하기2
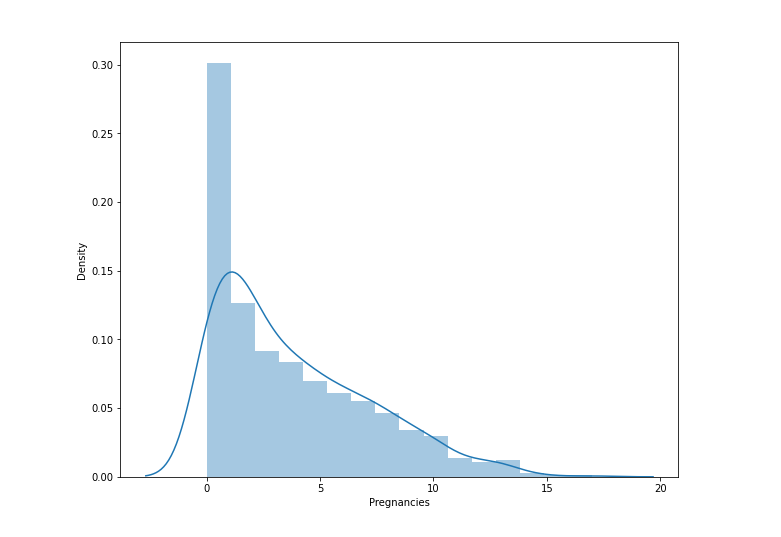
수치형 변수 1개의 분포를 파악할 때 사용histogram과 pdf도 함께 그려줌임신횟수의 분포를 보면 왼쪽으로 skewed된 형태를 보임.횟수가 늘수록 상대적으로 적은 빈도histogram의 경우 bin의 수를 늘려주면 더 세밀하게 표현할 수 있음.발병한 경우와 하지
5.3. 탐색한 데이터로 모델성능 개선1

Overfitting: Train set에 대해선 Good, Test set에 대해선 badUnderfitting: Train/Test 둘 다 bad -> 그냥 학습 자체가 제대로 안됨둘 다 일반화 성능 자체는 Bad. 결국 일반화가 중요한 것이므로 Under와 Ove
6.3. 탐색한 데이터로 모델성능 개선2
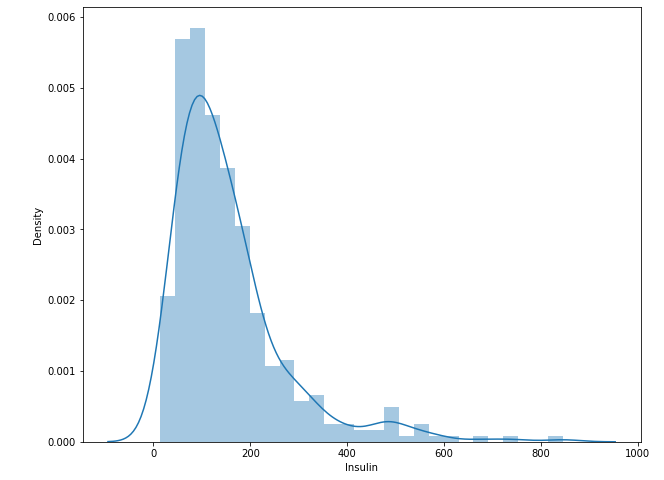
학습 시 데이터의 분포가 skewed된 형태라면 어려움이 있음한정된 케이스에 대해서만 학습하기 때문에... 이래서 balance가 중요왼쪽으로 skewed 형태Log 변환을 해줘 shape의 변환!log(0) = -Inf 이므로 +1을 해줌log 변환을 통해 꼬리가 긴
7.4. 모델과 파라미터 찾기1

train_test_split의 random_shuffle은 True가 디폴트. False로 주면 섞지 않고 순서대로 지정한 사이즈 만큼 할당함훈련 / 테스트 셋의 shape을 확인했고, random_state를 주어 매번 같은 결과가 나올 수 있도록한다.max_dep
8.4. 모델과 파라미터 찾기
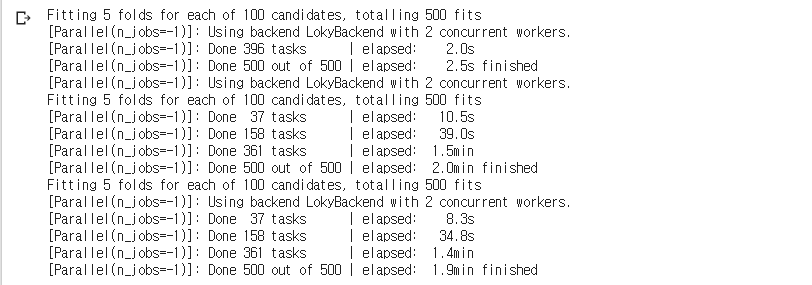
4.2 다양한 트리계열 머신러닝 모델 사용하기 4.2.1 랜덤포레스트 트리모델을 앙상블 기법에 사용(Bagging: Boostrap aggregating) 여러개의 트리 모델을 만들고 학습에 필요한 샘플은 부트스트랩을 이용 생겨나는 트리마다 랜덤하게 사용되는 변수를
9.5. 회귀모델 만들기1
이전엔 당뇨병 발병 여부를 예측하는 Classification Problem, 이번엔 인슐린 수치를 예측하는 Regression Problem전처리한 데이터엔 파생변수도 많았기 때문에 원본을 이용0으로 된 값들을 회귀로 예측해 대체해주기0 이하인 것들이 374개나 된다
10.5. 회귀모델 만들기2

Insulin 값을 회귀로 예측한 값을 넣어줌X에 변수는 8개만 넣어줌Test set엔 20%만큼 할당해 줌3개의 모델 생성100번의 iter로 DecisionTree에 대해선 모든 가능한 조합이 다 돌았고RF나 GB는 1000가지의 조합이므로 이 중 100개의 랜덤