5.2.1 회귀로 예측한 인슐린 분류에 사용하기
## 원본 데이터
df = pd.read_csv('/content/drive/MyDrive/edwith/프로젝트로 배우는 데이터 사이언스/data/diabetes_feature.csv')
df_insulin = pd.read_csv('diabets_fill_insulin.csv')
df['Insulin'] = df_insulin['Insulin']
df.head()X = df[['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age', 'Pregnancies_high']]
X.shape
- Insulin 값을 회귀로 예측한 값을 넣어줌

- X에 변수는 8개만 넣어줌
y = df['Outcome']
y.shape
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
print('Transet shape: {}, {}\nTestset shape: {}, {}'.format(X_train.shape, y_train.shape, X_test.shape, y_test.shape))
- Test set엔 20%만큼 할당해 줌
Modeling
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
estimators = [DecisionTreeClassifier(random_state = 42),
RandomForestClassifier(random_state = 42),
GradientBoostingClassifier(random_state = 42)]
estimators
- 3개의 모델 생성
max_depth = np.random.randint(2, 20, 10)
max_features = np.random.uniform(0.3, 1.0, 10)
model_names = [model.__class__.__name__ for model in estimators]
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {'max_depth': max_depth, 'max_features': max_features}
results = []
for i in estimators:
result = []
if i.__class__.__name__ != 'DecisionTreeClassifier':
param_distributions['n_estimators'] = np.random.randint(100, 200, 10)
## 모델 생성
clf = RandomizedSearchCV(i, param_distributions, n_iter = 100, scoring = 'accuracy', n_jobs = -1)
clf.fit(X_train, y_train)
result.append(i.__class__.__name__)
result.append(clf.best_params_)
result.append(clf.best_score_)
## Test set 정확도
result.append(clf.score(X_test, y_test))
result.append(clf.cv_results_)
results.append(result)- 100번의 iter로 DecisionTree에 대해선 모든 가능한 조합이 다 돌았고
- RF나 GB는 1000가지의 조합이므로 이 중 100개의 랜덤 샘플을 통해 모델을 생성해서 돌림
- verbose를 따로 주지 않아서 로그가 print되진 않았음. 디폴트가 0인듯
df = pd.DataFrame(results, columns = ['estimator', 'best_params', 'train_score', 'test_score', 'cv_result'])
df
- RandomForest가 가장 성능이 좋다. 하지만 기존의 방법보다 좋진 않다.
- 회귀분석을 통해 값을 대체해줬지만 오히려 성능이 안좋아졌다.
이처럼 모든 상황에 베스트인 것은 없다.
따라서 가능한 모든 상황에 대해 고려해보고 그리디한 선택을 해야한다.
5.3.1 머신러닝 모델 만들기 전체 과정 정리
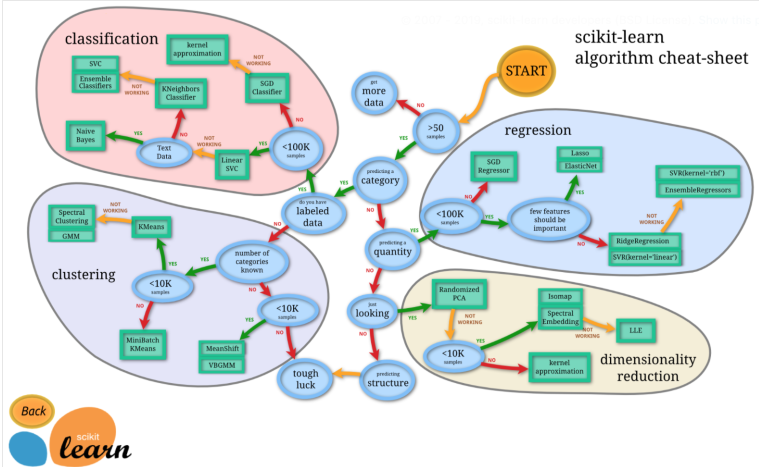
사이킷런 치트시트
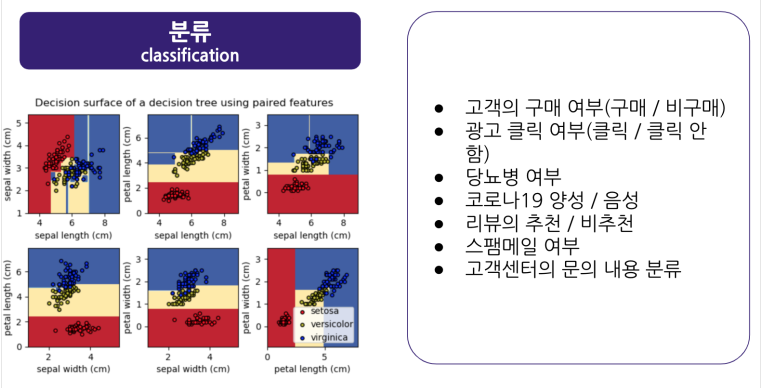
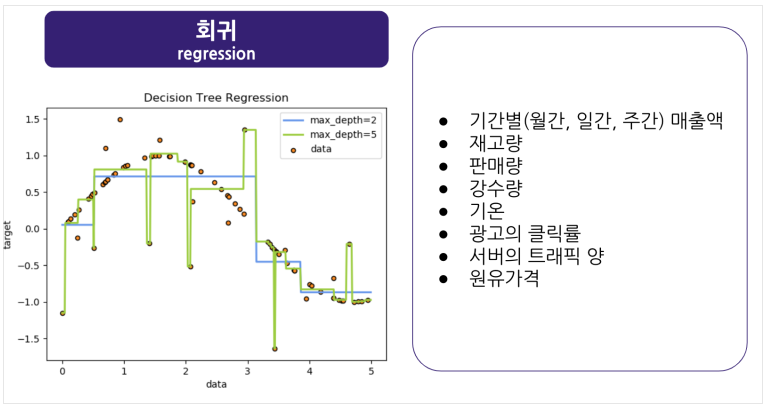
머신러닝의 종류
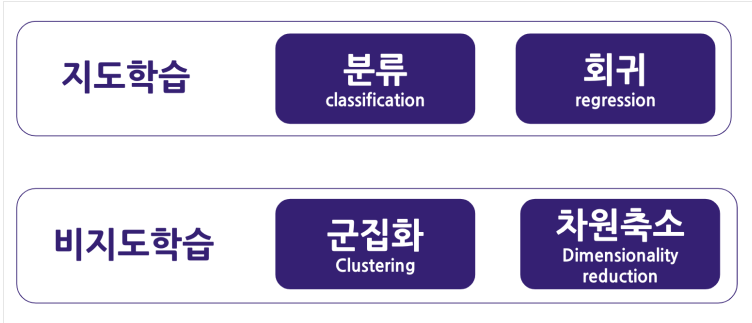
- 지도학습과 비지도학습의 예시. 강화학습도 있지만 그건 다루지 않음
전체적인 프로세스
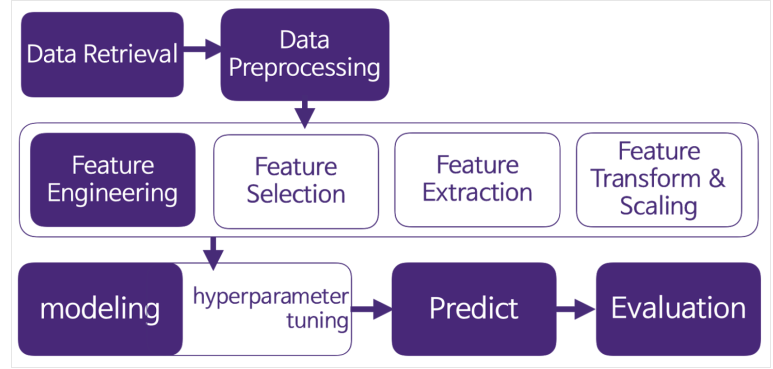
- 변수 중요도를 활용해 변수를 선택하거나 Backward, Forward등의 선택 방법을 쓰진 않았음
Decision Tree
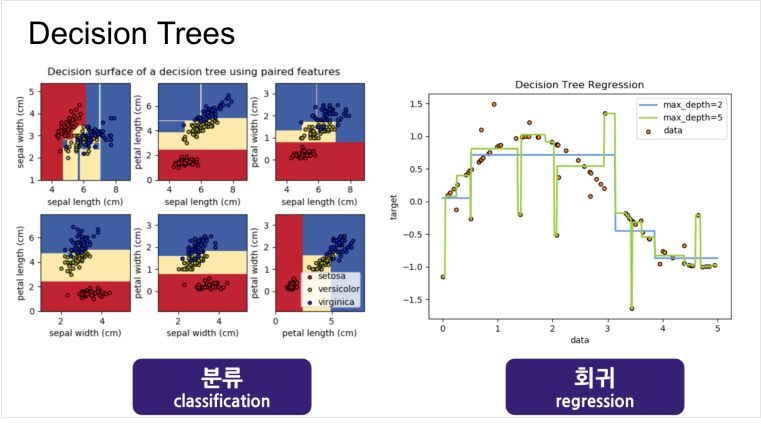
분류트리는 불순도가 적은 쪽으로, 회귀트리는 분산이 적은 쪽으로 분기!
depth가 깊어지면 과적합이 일어나므로 주의. Prunning을 하거나 depth를 조절
트리는 학습 속도가 상당히 빠름. but 과적합의 문제
RandomForest and Train/Test

RandomForest는 배깅 트리
여러개의 트리를 만들고, 각 트리들의 결과를 결합해서 결과를 도출
여러개의 트리를 학습시키는 데이터는 원 데이터에서 부트스트랩 샘플링!
트리의 과적합 문제를 해결
Train data로 학습하고, 학습된 모델을 Test로 평가!!
Over vs Under fitting
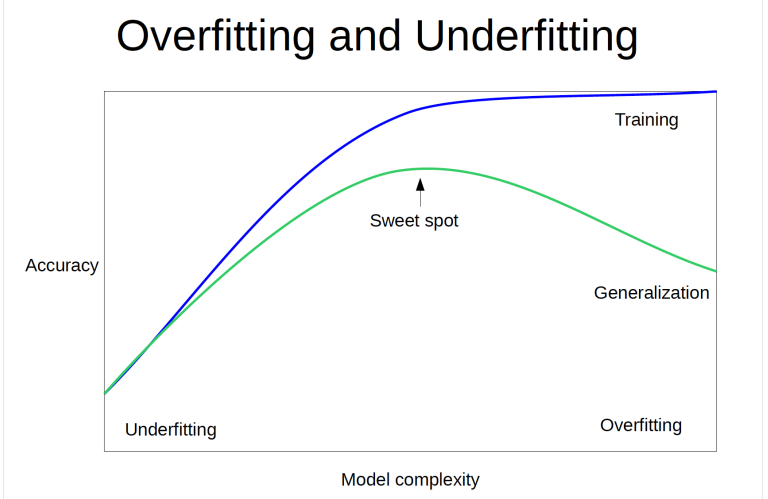
모델이 복잡해지면 Train data에 대해선 잘 맞추지만 Generalization이 안됨 -> Overfitting(Train good, Test bad)
모델이 간결하면 학습 자체도 제대로 못해서 둘 다 Bad일 수 있음
따라서, 너무 복잡하지도 간결하지도 않은 Sweet spot을 찾아야 함!
Grid vs Random search cv
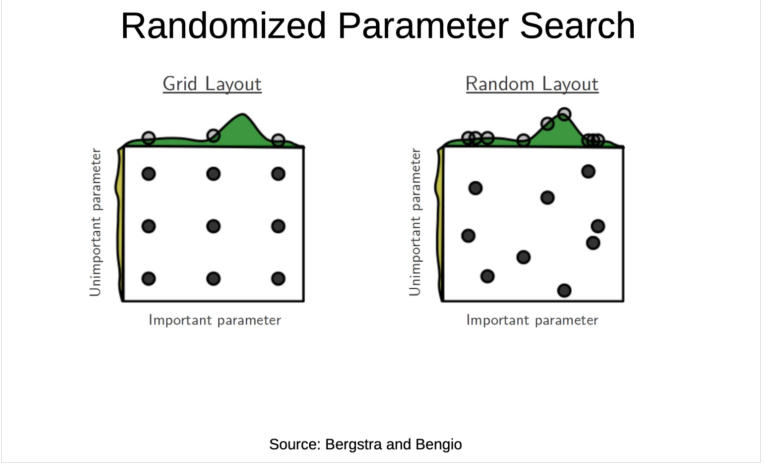
그리드는 입력해준 파라미터들에 대해 모든 조합을 생성하고
모든 조합으로 모델을 생성해서 k-fold CV를 통해 최적의 모델을 찾음데이터가 많지 않고, 하이퍼 파라미터의 차원이 낮은 경우 Good
랜덤은 난수로 파라미터를 입력하고 모든 가능한 조합을 생성함
그리고 지정해준 n_iter만큼 조합에서 샘플링을 해서 모델을 생성
이 조합을 생성하는 과정만 둘이 다를뿐, 이후에 학습은 다 똑같다.데이터가 많고, 파라미터가 복잡하다면 Random을 더 많이씀
PC가 엄청 좋고 시간도 많다면 모든 가능한 경우의 수를 Grid에 다 넣고
최적의 모델을 찾으면 됨. 근데 이게 가능할지...항상 적절한 Trade-off를 생각해야 함!!

Data science