1)언어 모델이란?
언어 모델은 언어라는 현상을 모델링 하고자 단어 시퀀스(또는 문장)에 확률을 할당하는 모델!
통계를 이용한 방법과 인공 신경망을 이용한 방법으로 나뉘는데, 최근엔 인공신경망이 더 좋은 성능을 보여준다.
1. 언어 모델(Language Model)
단어 시퀀스에 확률을 할당하는 일을 하는 모델. 가장 자연스러운 단어 시퀀스를 찾아내는 모델임. 이전 단어들이 주어졌을 때 다음 단어를 예측하게 하는 것!
다른 유형의 언어 모델은 주어진 양쪽의 단어들로부터 비어있는 가운데를 예측하는 언어 모델이 있음. 이건 BERT에서 다룸
언어모델링은 주어진 단어들로부터 모르는 단어를 예측하는 작업을 말한다. 즉, 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일이 언어 모델링.
2. 단어 시퀀스의 확률 할당
- a. 기계번역
p(나는 버스를 탔다) > P(나는 버스를 태운다)
: 언어 모델은 두 문장을 비교해 좌측 문장의 확률이 더 높다고 판단
- b. 오타 교정
선생님이 교실로 부리나케 P(달려갔다) > P(갈려갔다)
: 두 문장을 비교해 좌측의 문장 확률이 더 높다고 판단
- c: 음성 인식
P(나는 메롱을 먹는다) < P(나는 메론을 먹는다)
: 언어 모델은 이처럼 확률을 이용해서 보다 적절한 문장을 판단한다. 확률을 어떻게 할당하는지는 아직 모르고, 로직이 이런식인 것만 알아두기.
3. 주어진 이전 단어들로부터 다음 단어 예측하기

4. 언어 모델의 간단한 직관
비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를 [?]라는 문장이 있다면 사람은 쉽게 '놓쳤다'라고 예측을 한다. 왜냐면 우리 지식에 기반해 나올 수 있는 여러 단어 후보에 놓고 놓쳤다란 단어가 나올 확률을 가장 높게 판단했기 때문.
기계도 이런 로직을 바탕으로 단어 후보군을 놓고 가장 높은 확률을 갖는 단어를 정답으로 예측을 한다. 이는 검색엔진에서도 많이 사용됨.
예를 들면, '딥러닝을 이용한' 까지만 치면 그 뒤에 '주가 예측', '구문 분석' 등등 다음에 올 문장들의 후보군을 쭉 보여주는 게 연관 검색어 같은 것들임!
2) 통계적 언어 모델(SLM)
1. 조건부 확률

- 조건부 확률을 이용해 문장의 확률을 구함
2. 문장에 대한 확률

- 위에서 구한 조건부 확률의 일반화를 이용.
- 문장의 확률을 조건부 확률의 연쇄 곱으로 계산!!
3. 카운트 기반의 접근
문장의 확률을 구하기 위해 다음 단어에 대한 예측 확률을 모두 곱해줬음.
SLM은 이전 단어로부터 다음 단어에 대한 확률을 어떻게 계산?

- 사전 조건에 해당되는 문장의 카운트와 사후까지 합해진 문장의 카운트를 이용해서 확률을 계산한다.
- 전체 코퍼스 내에 사전 문장의 수와 사후까지 합한 문장의 수로 계싼!!
4. 카운트 기반 접근의 한계 - 희소 문제
위에서 처럼 카운트 기반으로 확률을 계산해 접근한다면 갖고있는 코퍼스, 기계가 훈련하는 데이터는 방대한 양이 필요하다. 사후 조건인 is가 붙어있는 텍스트가 0번 존재했다면 확률을 0으로 계산해서 is는 아예 고려조차 할 수 없게 된다.
이처럼 충분한 데이터를 관측하지 못해 정확히 모델링하지 못하는 걸 희소문제라 함. 이 문제 완화 방법으론 n-gram이나 스무딩이나 백오프 같은 일반화 기법이 존재한다. 희소 문제에 대한 근본적인 해결이 되지 못해서 언어 모델의 트렌드는 통계에서 인공 신경망으로 넘어오게 됨!!
3) N-gram 언어 모델
여전히 카운트에 기반한 통계적 접근을 사용하므로 SLM 일종. 하지만 모든 단어를 고려하는 것이 아닌 일부만 고려해 접근. 이때 일부 단어 몇 개를 보느냐를 결정하는게 N!!
1. 코퍼스에서 카운트하지 못하는 경우의 감소
SLM의 한계는 코퍼스 내에 확률 계산하고 싶은 문장이나 단어가 없을 수 있다는 점. 계산하고 싶은 문장이 길수록 그 문장이 존재하지 않을 가능성이 높다 보통. 따라서 참고하는 단어의 수를 줄이면 카운트 할 가능성이 높아질 수 있다.

2. N-gram
임의의 개수를 정하기 위한 기준이 n-gram. n개의 연속적인 단어 나열을 의미한다. n개의 단어 뭉치 단위로 끊어 이를 하나의 토큰으로 간주.
unigrams : an, adorable, little, boy, is, spreading, smiles
bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles

3. N-gram Language Model의 한계
4-gram에서 무시됐던 앞에 '작고 사랑스러운'을 생각해보자. 수식어까지 모두 고려한다면 그 뒤에 '모욕을 퍼트렸다'라는 부정 내용이 '웃음 지었다'라는 긍정 내용 대신 선택될 수 있을까?
코퍼스 내 데이터를 어떻게 가정하는지에 따라 다르고, 전혀 말이 안되는 문장은 아니지만 n-gram 뒤 단어 몇 개만 보다 보니 의도하고 싶은 대로 문장을 끝맺음 하지 못하는 경우가 생긴다. 문장을 읽다보면 앞과 뒤의 문맥이 전혀 연결 안되는 경우도 있다. 즉, 전체 문장을 고려한 언어 모델보단 정확도가 떨어질 수 밖에 없다.
(1) 희소 문제
모든 시퀀스를 보는 것보다 일부 시퀀스 만을 보는게 현실적으로 코퍼스에서 카운트 할 확률을 높였지만, n-gram도 여전히 희소 문제가 존재한다.
(2) n을 선택하는 건 trade-off
n을 보다 크게 하는 것은 좀 더 성능을 높일 수 있다. 하지만 n이 클수록 해당 n-gram을 카운트 할 확률은 적어지므로 희소 문제가 점점 심각해진다. n이 커질수록 모델 사이즈가 커진다는 문제도 있고.
n을 적게 선택하면 카운트는 잘되겠지만, 근사의 정확도는 현실의 확률분포와 멀어진다. 적절한 n을 선택해야 한다. 트레이드오프 때문에 n은 최대 5를 넘게 잡아선 안된다고 권장

- n이 커질수록 더 성능이 좋아진다.
4. 적용 분야(Domain)에 맞는 코퍼스의 수집
어떤 분야인지, 어떤 어플인지에 따라 특정 단어들의 확률 분포는 당연히 다름. 언어 모델에 사용하는 코퍼스를 각자 도메인 코퍼스를 사용한다면 제대로 된 언어 생성할 가능성이 높아진다.
이게 언어 모델의 약점이 되기도 하는데, 도메인 코퍼스가 뭐냐에 따라 성능이 비약적으로 달라지기 때문. 결국 머신러닝의 목적은 '일반화'가 아니겠나? 모든 경우에 대해서 잘 예측가능한 것. 하지만 코퍼스에 영향을 받으므로 '일반화'가 어려운 게 한계인가보다.
5. 인공 신경망을 이용한 언어 모델
n-gram의 한계를 극복하기 위해 분모, 분바에 숫자를 더해서 카운트했을 떄 0이 되는 것을 방지하는 등의 여러 일반화가 존재한다. 근본적인 n-gram 취약점을 제대로 해결하진 못해서 대체적으로 성능이 우수한 인공 신경망을 이용한 언어 모델이 많이 사용된다.
4) 한국어에서의 언어 모델
1. 한국어는 어순이 중요하지 않다
한국어는 어순이 중요하지 않다. 이전 단어가 주어지면 다음 단어가 나타날 확률을 구해야 하는데, 어순이 중요치 않다는 건 뭐가 나와도 상관 없단 뜻!!
ex)
1. 나는 운동을 한다. 체육관에서
2. 나는 체육관에서 운동을 한다.
3. 체육관에서 운동을 한다
4. 나는 운동을 체육관에서 한다.
4개 문장 모두 내가 체육관에서 운동을 한다는 의미를 갖고 있다. 이게 한국어의 좋은 점인데, 언어 모델에서는 참 안좋은 점으로 통한다....
2. 한국어는 교착어!
교착어는 모델 작동을 어렵게 한다. 띄어쓰기 단위인 어절 단위로 토큰화를 할 경우 문장에서 발생가능한 수가 굉장히 높아진다. 조사와 같은 교착어 때문!!
영어엔 조사가 없고, 한국어엔 어떤 행동을 하는 동사의 주어나 목적어를 위해 조사라는 것이 있다.
ex) '그녀' 하나만 해도 그녀가, 그녀를, 그녀와 그녀의, 그녀께서, 그녀처럼.... 벌써 6개의 조사가 붙을 수 있고 이러면 같은 뜻이라 해도 다른 표현이 다수인 것이다. 따라서, 한국어에선 토큰화를 통해 접사나 조사를 분리하는 것은 중요한 작업이 되기도 한다.
3. 한국어는 띄어쓰기가 제대로 X
이전에도 봤던 것 처럼, 한국어는 띄어쓰기를 제대로 안해도 이해가 된다. 또한, 규칙이 상대적으로 까다로워 자연어 처리를 하는 것에 있어 코퍼스는 띄어쓰기가 제대로 안된 경우가 많다. 토큰이 제대로 분리되지 않은채 훈련에 사용된다면 언어 모델은 제대로 동작할 수가 없다. 쓰레기 인, 쓰레기 아웃!!!!
5) 펄플렉서티(Perplexity)
모델 내에서 자신의 성능을 수치화해 결과를 내놓는 내부 평가를 뜻함
1. 언어 모델의 평가 방법(Evaluation metric): PPL
펄플렉서티는 내부 평가 지표. 보통 PPL이라 함. perplexed는 헷갈리는 이란 뜻. PPL을 헷갈리는 정도로 이해하자. PPL은 수치가 높으면 좋은게 아니라, 낮을수록 좋은 것!

2. 분기 계수(Branching factor)
PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수이다.
특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하는 지를 의미.
PPL이 10이라면, 해당 언어 모델은 다음 단어를 예측하는 모든 시점마다 평균적으로 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 봄.
같은 테스트 데이터에 대해 두 언어 모델의 PPL을 각각 계산 후 PPL 값을 비교하면, 언어 모델 중 어떤 것이 성능이 좋은지 판단 가능. PPL이 더 낮은 언어 모델의 성능이 GOOD!

test ppl이 높다고 해서, 일반화가 잘되는 것은 아님. over-fitting의 느낌인 듯.
3. 기존 언어 모델 vs 인공 신경망을 이용한 언어 모델
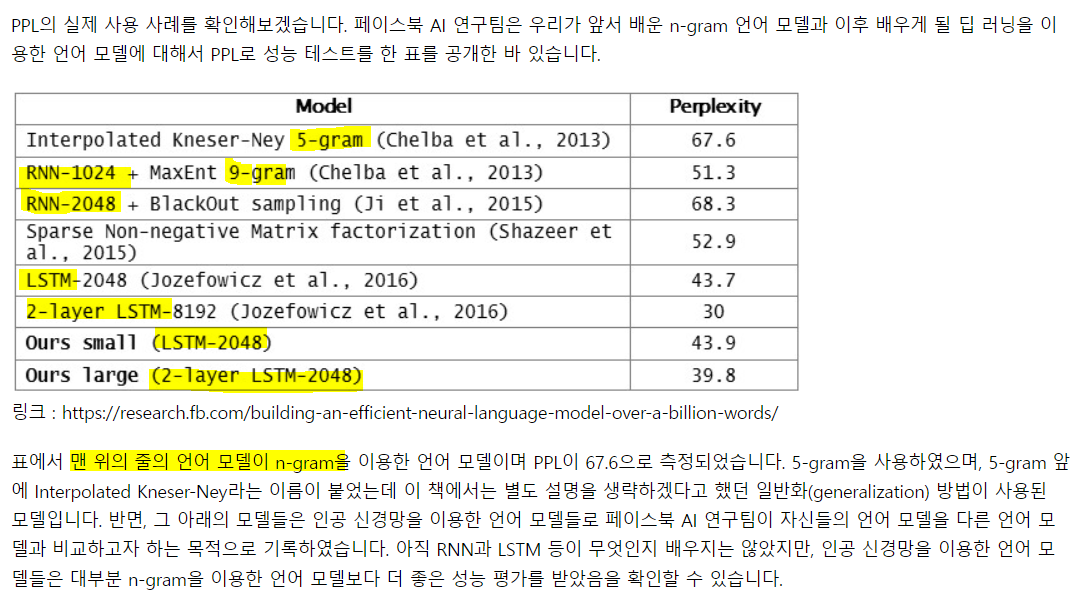
neural net 모델들이 n-gram보다 더 좋은 성능을 보인다..!!!!!
하지만, 뭐 코퍼스가 어떻게 구성되었냐에 따라도 다를 것이고, 머신러닝의 특성상 모든 경우에 good 즉, 완벽한 generalization이 된 모델은 없다 아직. 있을지도 모르겠고... 그래서 다양한 모델을 알고 있고 교차검증을 해서 최적을 찾는 것이 현명. 여러 모델에 대해 그 특징들을 파악하고 있는 게 좋을듯
6) 조건부 확률

- 조건부 확률의 개념을 이해하는데 쉽지 않았다 예전엔.
- 조금 쉽게 생각해보면, 어떤 조건이 선행되었을 때 관심있는 사건이 발생하는 경우라고 생각하자
- 말이 어려운데, 임의로 한 명을 뽑았는데, 이 사람이 서울에 살 때(선행 조건), 20살일(관심있는 사건) 확률 이런게 조건부 확률
- 특정 조건 하에서 사건이 벌어질 확률을 계산하는 것!!
- 그리고 저런 표를 만들면 조건부 확률을 저렇게 복잡하게 계산할 게 아니라, 고등학생 하나 뽑았을 때, 남학생일 확률을 계산하는 건 그냥 전체 사건을 300으로 보는 게 아니라 고등학생으로 보고 남자인 count를 보고 prob을 계산해주면 됨. 오히려 더 쉽다. 저런식으로 matrix화 하면
