카운트 기반의 단어 표현
1) 다양한 단어 표현 방법
1. 단어의 표현 방법
크게 국소 표현(Local Representation)과 분산 표현(Distributed Representation)으로 나뉜다. 국소는 해당 단어 그 자체만 보고, 특정 값을 매핑해 단어를 표현하고, 분산 방법은 그 단어를 표현하고자 주변을 참고해 단어를 표현한다.
예를 들어, puppy, cute, lovely에 각각 1, 2, 3을 매핑한다면 국소!! puppy 주변에 cute, lovely가 자주 등장하므로 puppy를 cute, lovely한 느낌이라고 정의한다면 이건 분산 표현!
2. 단어 표현의 카테고리화
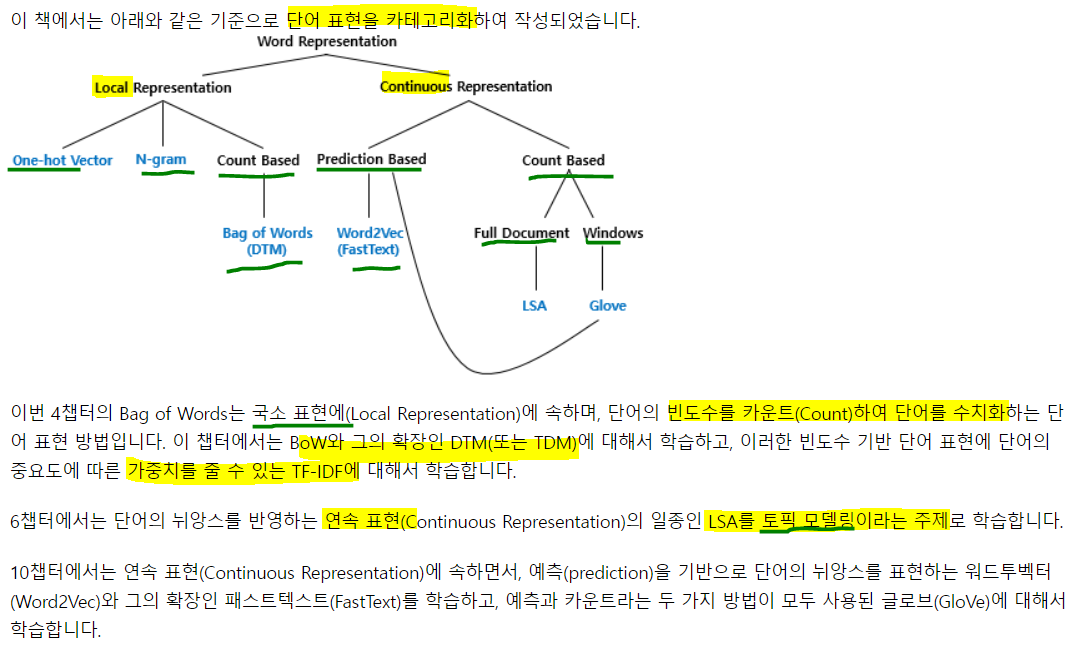
2) Bag of words(BoW)
1. Bag of words?
단어의 등장 순서를 고려하지 않는 빈도수 기반의 텍스트 데이터의 수치화 표현.
단어들이 들어있는 Bag이라 생각하고, 이를 막 섞으면 이미 순서는 중요하지 않게되고 word가 몇개 들어있는지 그 빈도N만 중요.
BoW를 만드는 과정은 1)우선 각 단어에 고유 정수 인덱스를 부여. 2) 각 인덱스 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만든다.
ex) 정부가 발표하는 물가상승률은 소비자가 느끼는 물가상승률은 다르다.
from konlpy.tag import Okt
import re
okt = Okt()
token = re.sub("(\.)", "", '정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.')
# 정규 표현식을 통해 온점을 제거하는 정제 작업
token = okt.morphs(token)
# OKT 형태소 분석기를 이용해 토큰화 작업을 수행
word2index = {}
bow = [] # Bag of Words
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
# token을 읽으면서 word2index에 없는 단어는 추가하고, 있는 단어는 넘긴다.
bow.insert(len(word2index)-1, 1)
# bow의 index에 1을 넣어준다
else:
index = word2index.get(voca)
# 재등장 하는 단어의 인덱스를 받아옴
bow[index] = bow[index] + 1
# 재등장 하는 단어는 해당 인덱스에 1을 더해줌. 단어의 개수를 세는 것
print(word2index){'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}bow[1, 2, 1, 1, 2, 1, 1, 1, 1, 1]문서에 대한 인덱스를 부여한 결과는 첫번째, 그 BoW는 두 번째. 그래서 해당 인덱스를 가지는 단어의 빈도를 알 수 있음. 원한다면 불용어에 해당되는 조사도 제거하며 더 정제된 BoW를 만들 수 있음
2. Bag of Words 다른 예제들
앞서 언급했듯이, BoW에 있어서 중요한 것은 단어의 등장 빈도입니다. 단어의 순서. 즉, 인덱스의 순서는 전혀 상관없습니다. 문서1에 대한 인덱스 할당을 임의로 바꾸고 그에 따른 BoW를 만든다고 해봅시다.
('발표': 0, '가': 1, '정부': 2, '하는': 3, '소비자': 4, '과': 5, '물가상승률': 6, '느끼는': 7, '은': 8, '다르다': 9)
[1, 2, 1, 1, 1, 1, 2, 1, 1, 1]위의 BoW는 단지 단어들의 인덱스만 바뀌었을 뿐이며, 개념적으로는 여전히 앞서 만든 BoW와 동일한 BoW로 취급할 수 있습니다.
문서2 : 소비자는 주로 소비하는 상품을 기준으로 물가상승률을 느낀다.
만약, 위의 코드에 문서2로 입력으로 하여 인덱스 할당과 BoW를 만드는 것을 진행한다면 아래와 같은 결과가 나옵니다.
('소비자': 0, '는': 1, '주로': 2, '소비': 3, '하는': 4, '상품': 5, '을': 6, '기준': 7, '으로': 8, '물가상승률': 9, '느낀다': 10)
[1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1] 문서1과 문서2를 합쳐서 (이를 문서3이라고 명명합시다.) BoW를 만들 수도 있습니다.
문서3: 정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다. 소비자는 주로 소비하는 상품을 기준으로 물가상승률을 느낀다.
위의 코드에 문서3을 입력으로 하여 인덱스 할당과 BoW를 만든다면 아래와 같은 결과가 나옵니다.
('정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9, '는': 10, '주로': 11, '소비': 12, '상품': 13, '을': 14, '기준': 15, '으로': 16, '느낀다': 17)
[1, 2, 1, 2, 3, 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1] 문서3의 단어 집합은 문서1과 문서2의 단어들을 모두 포함하고 있는 것들을 볼 수 있습니다. BoW는 종종 여러 문서의 단어 집합을 합친 뒤에, 해당 단어 집합에 대한 각 문서의 BoW를 구하기도 합니다. 가령, 문서3에 대한 단어 집합을 기준으로 문서1, 문서2의 BoW를 만든다고 한다면 결과는 아래와 같습니다.
문서3 단어 집합에 대한 문서1 BoW : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
문서3 단어 집합에 대한 문서2 BoW : [0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 2, 1, 1, 1]문서3 단어 집합에서 물가상승률이라는 단어는 인덱스가 4에 해당됩니다. 물가상승률이라는 단어는 문서1에서는 2회 등장하며, 문서2에서는 1회 등장하였기 때문에 두 BoW의 인덱스 4의 값은 각각 2와 1이 되는 것을 볼 수 있습니다.
BoW는 각 단어가 등장한 횟수를 수치화하는 텍스트 표현 방법이기 때문에, 주로 어떤 단어가 얼마나 등장했는지를 기준으로 문서가 어떤 성격의 문서인지를 판단하는 작업에 쓰입니다. 즉, 분류 문제나 여러 문서 간의 유사도를 구하는 문제에 주로 쓰입니다. 가령, '달리기', '체력', '근력'과 같은 단어가 자주 등장하면 해당 문서를 체육 관련 문서로 분류할 수 있을 것이며, '미분', '방정식', '부등식'과 같은 단어가 자주 등장한다면 수학 관련 문서로 분류할 수 있습니다.
3. CountVectorizer 클래스로 Bow만들기
사이킷 런엔 빈도를 count해 vector로 만드는 클래스를 지원한다. 영어에 대해선 손쉽게 BoW를 만들 수 있음
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray()) # 코퍼스로부터 빈도수 기록
print(vector.vocabulary_) # 각 단어의 인덱스[[1 1 2 1 2 1]]
{'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}you와 love가 두 번씩 쓰였으므로 2와 4가의 count가 2임을 알 수 있다. I는 BoW 만드는 과정에서 사라졌는데, 이는 CountVectorizer가 기본적으로 길이가 2이상인 문자만 토큰으로 인식. 앞서 정제를 배웠을 때 영어에선 길이가 짧은 문자를 제거하는 것 또한 전처리 작업으로 고려 됨!
주의할 점은, 단지 띄어쓰기만으로 단어를 자르는 낮은 수준의 토큰화를 한다는 점. 한국어에 적용한다면 조사등의 이유로 BoW가 제대로 만들어지지 않음.
앞서 '정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다'를 생각해보면 물가상승률과 물가상승률은 모두 '물가상승률'을 뜻하지만 조사가 다르므로 다른 두 단어로 인식한다 -> Bow내에 물가상승률의 n이 2가 아니라 각각 조사 붙은 것이 1씩 인식됨.
4. 불용어를 제거한 Bow만들기
BoW를 사용하는 건, 그 문서에서 각 단어가 얼마나 자주 등장했는지를 보겠다는 뜻. 빈도수를 수치화 한다는 건, 단어들이 얼마나 중요한지를 보겠단 것. 따라서 불용어를 제거하는 것은 자연어 처리의 정확도를 높이기 위해 선택 가능한 전처리 방법임!!
(1) 사용자가 직접 정의한 불용어 사용
from sklearn.feature_extraction.text import CountVectorizer
### text는 리스트 형태로 넣어줌!
text = ["Family is not an important thing. It's everything"]
### 불용어 지정. stop_words 파라미터!!!
vect = CountVectorizer(stop_words = ['the', 'a', 'an', 'is', 'not'])
print(vect.fit_transform(text).toarray())
print(vect.vocabulary_)[[1 1 1 1 1]]
{'family': 1, 'important': 2, 'thing': 4, 'it': 3, 'everything': 0}is, not, an, 축약된 's도 사라짐. stop_words 파라미터를 이용해서!!!
(2) CountVectorizer에서 제공하는 자체 불용어 사용
## 자체 불용어 사용
vect = CountVectorizer(stop_words = 'english')
print(vect.fit_transform(text).toarray()) # fit과 변환 동시에
print(vect.vocabulary_)[[1 1 1]]
{'family': 0, 'important': 1, 'thing': 2}자체 불용어를 사용하니 더 많은 단어들이 제거됨.
(3) NLTK에서 사용하는 불용어
from nltk.corpus import stopwords
sw = stopwords.words('english') # nltk 제공 불용어!
vect = CountVectorizer(stop_words = sw)
print(vect.fit_transform(text).toarray())
print(vect.vocabulary_)[[1 1 1 1]]
{'family': 1, 'important': 2, 'thing': 3, 'everything': 0}CountVectorizer 자체 제공 불용어와 NLTK의 불용어가 다름. everything의 차이가 있음. 이 예제에선 하나만 차이가 났지만, 아마 둘이 다를 것임! 불용어 사전이라는 일반화된 사전이고 사람이 만든거라 중요의 차이는 상대적인 것이기 때문에. 다를 수 밖에 없다!
3) 문서 단어 행렬(Document-Term Matrix, DTM)
BoW 표현 방법을 그대로 가져와, 서로 다른 문서들의 BoW들을 결합한 표현 방법. 행 열을 반대로 선택하면 TDM이라고 부름
1. 문서 단어 행렬의 표기법
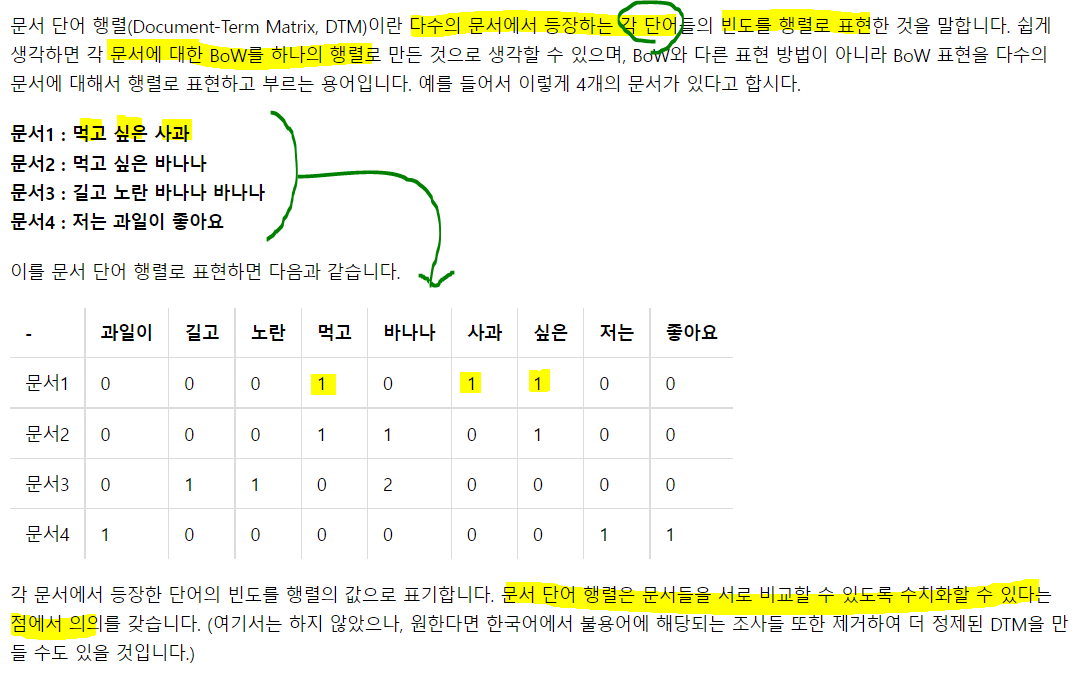
- 모든 토큰이 컬럼으로 가고 row는 각 문서. 그리고 row와 col이 만나는 cell엔 그 빈도가 들어간다.
2. DTM의 한계
매우 간단하고 구현도 쉽지만, 본질적으로 가지는 몇 가지 한계가 있음
1) 희소 표현
컬럼은 전체 단어의 집합 크기를 가진다. 즉, 코퍼스의 크기에 따라 한 문서의 차원이 몇백만이 될 수도 있다. 또한, 위에서 본 것처럼 0이 많으므로 원-핫의 한계처럼 공간적 낭비와 계산 리소스 증가의 문제...
이런 이유로, 전처리를 통해 BoW의 단어를 줄이는 것은 BoW를 사용하는 모델에서 중요. 구두점, 빈도수 낮은 단어, 불용어를 제거하고, 어간(Stemming) 또는 표제어 추출(Lemmatization)을 통해 코퍼스의 크기를 줄일 수 있다.
2) 단순 빈도 수 기반 접근
예를 들면 the와 같은 불용어는 모든 문서에서 자주 등장할 수 밖에 없음. 예를 들어, 문서1과 문서2의 유사도를 보고 싶은데 the의 등장 수가 비슷하다고 두 문서가 유사하다 생각하면 안된다. one-hot과 마찬가지로 유사도 파악이 어려움!!
4) TF-IDF(Term Frequency-Inverse Document Frequency)
: 단어의 빈도와 역 문서 빈도(문서 빈도에 특정 식을 취함)를 사용해 DTM 내 각 단어들 마다 중요 정도를 가중치로 주는 방법! 우선 DTM을 만들고 TF-IDF 가중치를 부여.
TF-IDF는 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과 중요도를 정하는 작업, 문서 내 특정 단어의 중요도를 구하는 작업에 쓰인다.
TF-IDF는 TF * IDF를 의미.
문서를 d, 단어를 t, 문서의 총 개수를 n

TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다 판단, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다 판단!
TF-IDF 값이 낮으면 중요도가 낮은 것이고, 크면 중요도가 높은 것. 'the', 'a'와 같은 건 모든 문서에서 자주 등장하므로 TF-IDF 값이 낮아진다.
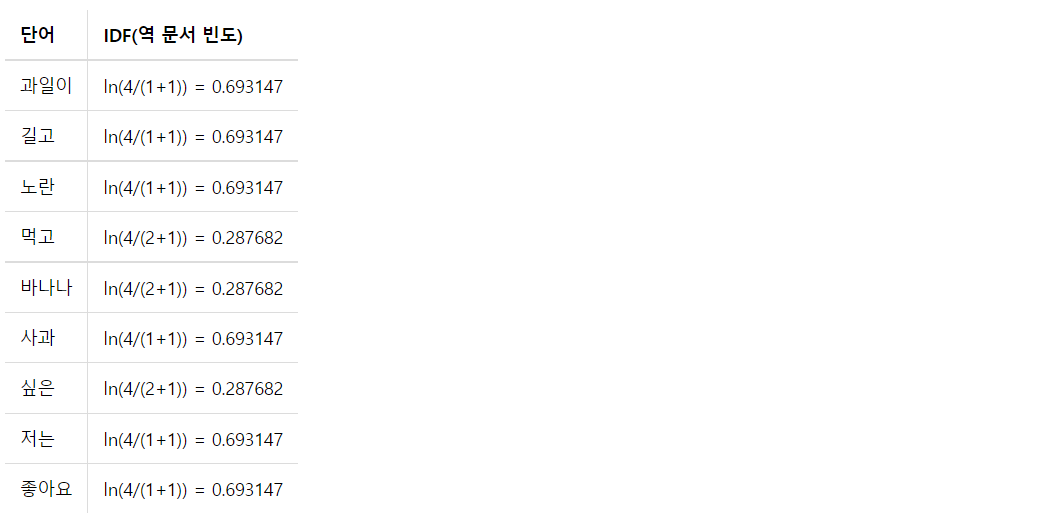
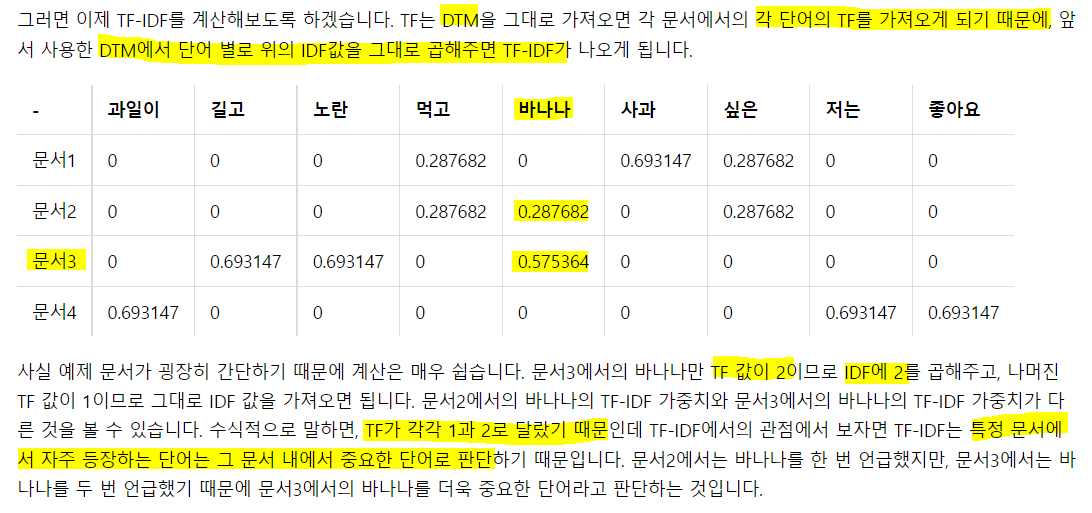
즉, 코퍼스 내 각 단어를 컬럼으로 문서를 로우로 해서 각 문서별 단어의 빈도 매트릭스, DTM을 만든다. 이게 TF에 해당.
IDF는 우선 DF를 계산한다 -> 각 단어가 총 몇개의 문서에 존재하는지. 이걸 계산하고 log(n/DF+1)을 계산하면 각 단어의 IDF가 된다. 이제 이 IDF 값을 각 컬럼 별로 곱해주면 TF-IDF가 계산되는 것!!
2. 파이썬으로 직접 구현!!!
import pandas as pd
from math import log
## 앞서 설명한 4개의 문서
docs = ['먹고 싶은 사과', '먹고 싶은 바나나', '길고 노란 바나나 바나나', '저는 과일이 좋아요']
## doc은 docs를 돌고, w는 doc의 split() 공백을 기준으로 분리된 리스트를 돈다.
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort() # 정렬
N = len(docs) # n 값
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
## t가 doc 안에 있다면 df에 t를 더함
df += t in doc
return log(N / (df + 1))
def tfidf(t, d):
return tf(t, d) * idf(t)## Tf 계산
result = []
for i in range(N):
# 이중 리스트 생성
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
# 각 단어의 freq 추가. [-1]로 가장 마지막에 넣어준 []에 접근
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns = vocab)
tf_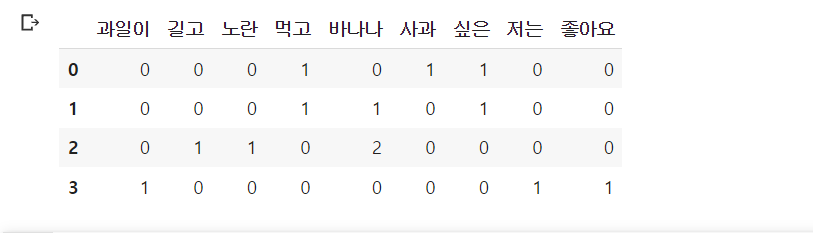
## IDF 값
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
idf_ = pd.DataFrame(result, index = vocab, columns = ['IDF'])
idf_
수기로 구한 IDF 값들과 일치. TF-IDF를 출력해보자
result = []
# 문서 수 만큼 반복
for i in range(N):
# 각 문서의 TF-IDF를 담아줄 빈 리스트 추가
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t, d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_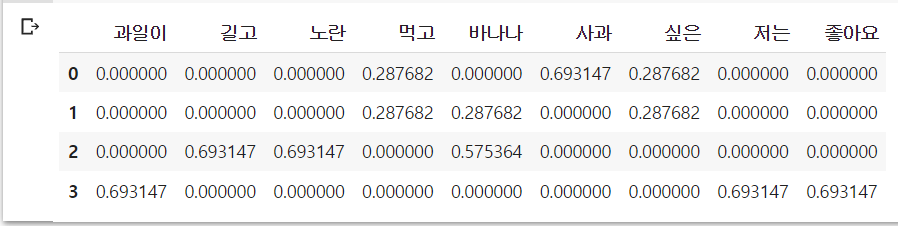
기본적으로 어떻게 tf-idf가 계산되는지 실습을 해봤다.
하지만, n이 4인데 df(t) 값이 3이라면 df(t)에 1이 더해지면서 idf의 분자 분모가 같아지면서 log(1) = 0이 된다. IDF 값이 0이라면 가중치의 역할을 할 수가 없다. 그래서 실제 구현체는 IDF(d,t)에 1을 더해 0이 되더라도 IDF가 최소 1이상의 값을 가지도록 함!! 사이킷런이 이 방식을 씀
3. 사이킷런을 이용한 DTM과 TF-IDF 실습
- DTM
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you konw I want you love',
'I like you',
'what should I do',
]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray())
print(vector.vocabulary_)[[0 1 0 1 0 1 0 2]
[0 0 1 0 0 0 0 1]
[1 0 0 0 1 0 1 0]]
{'you': 7, 'konw': 1, 'want': 5, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}DTM의 완성! 각 단어의 인덱스가 컬럼의 인덱스임! 즉 0번 컬럼은 'do'를 뜻함
- TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ['you konw I want your love',
'I like you',
'what should I do',]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)[[0. 0.46735098 0. 0.46735098 0. 0.46735098
0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0.
0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0.
0.57735027 0. 0. ]]
{'you': 7, 'konw': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}Bow, DTM, TF-IDF 모두 학습. 문서 간 유사도를 구하기 위한 재료 손질 방법을 배운 셈. 케라스로도 만들 수 있음.
