1) 코사인 유사도
1. 코사인 유사도(Cosine Similarity)
두 벡터 간의 코사인 각도를 이용해 구할 수 있는 두 벡터의 유사도를 의미.
두 벡터의 방향이 완전히 동일하면 1(cos(0) = 1), 180도 반대라면 -1(cos(pi) = -1), 직교하면 0(cos(pi/2) = 0). 직관적으로 두 벡터의 방향이 유사한지를 의미
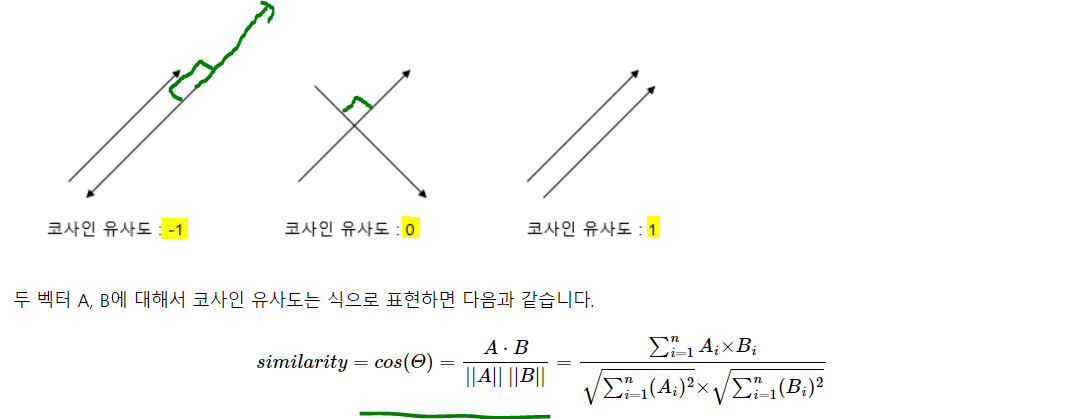
그냥 두 벡터간의 코사인 값 구하는 것! 선대시간에 배운 기본 내용

from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
## norm은 각 벡터의 크기를 뜻함. dot은 두 매트릭스의 dot product
return dot(A, B) / (norm(A) * norm(B))
doc1 = np.array([0, 1, 1, 1])
doc2 = np.array([1, 0, 1, 1])
doc3 = np.array([2, 0, 2, 2])
print(cos_sim(doc1, doc2)) # doc1과 2의 코사인 유사도
print(cos_sim(doc1, doc3)) # 1과 3의 유사도
print(cos_sim(doc2, doc3)) # 2와 3의 유사도0.6666666666666667
0.6666666666666667
1.00000000000000022와 3은 1로 완전히 동일하다는 건데 보면, doc2는 doc1의 tf에 스칼라 곱만 해준 것. 즉 크기만 다를 뿐 같은 것.
이처럼 하나의 문서가 다른 하나 문서의 tf의 곱으로 표현된 건 단순히 모든 단어의 빈도수가 똑같이 증가한 것. 만약 문장의 길이가 엄청 길어서 모든 단어의 빈도수가 비슷하게 증가만 하는 경우가 많음. 이런 경우 1이 나온다고 이게 이 문서와 엄청 유사하다고 생각하는게 아니라, 그냥 단순히 늘어난 것을 알 수 있게 해줌. 즉, 문서의 길이가 다른 상황에서 비교적 공정한 비교를 가능케 함.
이는 코사인 유사도가 벡터의 크기가 아닌, 방향에 초점을 두기 때문!
2. 유사도를 이용한 추천 시스템 구현
TF-IDF와 코사인 유사도 만으로 줄거리에 기반해 영화 추천 시스템 만들 수 있음
영화 파일 다운로드
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
data = pd.read_csv('/content/drive/MyDrive/산학협력프로젝트/딥러닝을 이용한 자연어 처리 입문/archive/movies_metadata.csv', low_memory = False)
data.head()
data는 위와 같은 형태로 구성되어 있고 그 shape은 (45466, 24). 우선 상위 20000개만 잘라서 사용하겠음
data = data.head(20000)
data.overview.isna().sum()135줄거리 기반의 영화 추천을 할 것이므로 overview가 중요. overview의 null이 135. TF-IDF를 생성할 때 Null이 있으면 오류가 발생하므로 그냥 ''로 대체
data.overview.fillna('', inplace = True)
## TF-IDF 수행
## 영어 불용어를 제거하고 TF-IDF 생성
tfidf = TfidfVectorizer(stop_words = 'english')
tfidf_mat = tfidf.fit_transform(data['overview'])
tfidf_mat.shape(20000, 47487)
20000개의 문서에 대해 47487개의 단어 토큰이 생성되었다!
코사인 유사도를 사용해 문서의 유사도를 파악하자
```py
indices = pd.Series(data.index, index = data['title']).drop_duplicates()
print(indices.head())title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
dtype: int64indices를 만든 이유는 타이틀 입력시 인덱스 리턴하기 위함
## 코사인 유사도 계산 with linear kernel
cosine_sim = linear_kernel(tfidf_mat, tfidf_mat)
## 추천 함수 작성
def get_recommend(title, cosine_sim = cosine_sim):
# 선택한 영화의 인덱스 가져오기
idx = indices[title]
# 모든 영화에 대해 유사도 구함(TF-IDF 기반)
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 정렬
sim_scores = sorted(sim_scores, key = lambda x: x[1], reverse = True)
# 가장 유사한 10개의 영화를 받아옴
sim_scores = sim_scores[1:11]
# 10개 인덱스 받아옴
movie_indices = [i[0] for i in sim_scores]
# 영화 제목 리턴
return data['title'].iloc[movie_indices]
get_recommend('The Dark Knight Rises')12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
10122 Batman Begins
Name: title, dtype: object- 다크나이트 라이즈와 유사한 overview 기반의 상위 10개 추천
- 다 배트맨 관련 영화!
- 만약 재밌게 본 영화의 줄거리가 있다면 그걸 활용해서 추천 받아도 될듯
- 단, 저 코퍼스 내에 있는 영화여야 가능한듯. 없다면 추가해서 새로 돌리면 됨
2) 여러가지 유사도 기법
1. 유클리드 거리
다차원 공간에서 두 개의 점 사이의 거리라고 생각하면 됨.

이 유사도 계산시 사용하는 거리들이 군집화에도 사용.
## 문서간 유클리드 거리 계산으로 유사도 파악
import numpy as np
def dist(x, y):
return np.sqrt(np.sum((x-y) ** 2))
doc1 = np.array([2, 3, 0, 1])
doc2 = np.array([1, 2, 3 ,1])
doc3 = np.array([2, 1, 2, 2])
docQ = np.array([1, 1, 0, 1])
print(dist(doc1, docQ))
print(dist(doc2, docQ))
print(dist(doc3, docQ))2.23606797749979
3.1622776601683795
2.449489742783178docQ가 관심있는 문서고, 1~3이 기존 존재하는 문서를 뜻한다. 유클리드 거리 기준으로 Q와 가장 유사한 문서는 doc1!!
2. 자카드 유사도
두 집합이 있을 때, 합집합에서 교집합의 비율로 유사도를 구함. 자카드 유사도는 0~1사이 값을 가지고, 동일하다면 1, 원소가 없다면 0!

doc1 = "apple banana everyone like likey watch card holder"
doc2 = "apple banana coupon passport love you"
# 토큰화를 수행합니다.
tokenized_doc1 = doc1.split()
tokenized_doc2 = doc2.split()
# 토큰화 결과 출력
print(tokenized_doc1)
print(tokenized_doc2)['apple', 'banana', 'everyone', 'like', 'likey', 'watch', 'card', 'holder']
['apple', 'banana', 'coupon', 'passport', 'love', 'you']단순 띄어쓰기 기반 토큰화를 해주고 그 결과는 위와 같다.
## 문서1과 2의 합집합과 교집합!
union = set(tokenized_doc1).union(set(tokenized_doc2))
intersection = set(tokenized_doc1).intersection(set(tokenized_doc2))
print(union)
print(intersection){'everyone', 'watch', 'card', 'like', 'holder', 'passport', 'banana', 'you', 'love', 'likey', 'apple', 'coupon'}
{'banana', 'apple'}set 연산에 대해선 set만 가능하므로 doc1, 2를 set으로 변환해 줌. 이렇게 되면 중복은 제거됨. 이제 교집합과 합집합의 수로 자카드 계수 계산
## jaccard
print(len(intersection) / len(union))0.16666666666666666두 문서간의 중복을 제외한 유니크한 원소간의 자카드 계수를 구해봤고 그 값은 0.16이다. 자카드 계수는 두 문서의 유니크한 원소의 합 중 공통적으로 등장한 비율을 뜻한다. 이 비율의 높고 낮음은 주관적이므로, 분석자가 기준을 정해야 함.
