머신러닝
1) 머신 러닝 이란?
1. 머신러닝이 아닌 접근의 한계
기존의 프로그래밍 방법은 이렇다
def prediction(이미지 as input):
코딩방법
return 결과기존의 코딩 방식은 짜여진 로직에 걸린다면 제대로 분류를 하는 것이고, 아니면 잘못된 분류를 한다. 기존 고양이의 사진에 대해서 로직이 짜여졌다면 어래와 같은 사진을 제대로 분류할 수 있을까?

아마 제대로 분류하지 못할 것이다. 로직에 모든 경우의 수를 다 넣어줄 수는 없기 때문에 한계가 있음. 로직을 업데이트 하게 된다면 어떻게 될까? 이 한계를 극복한 게 머신러닝이라고 생각한다.
2. 머신러닝이 대안이 되는 이유
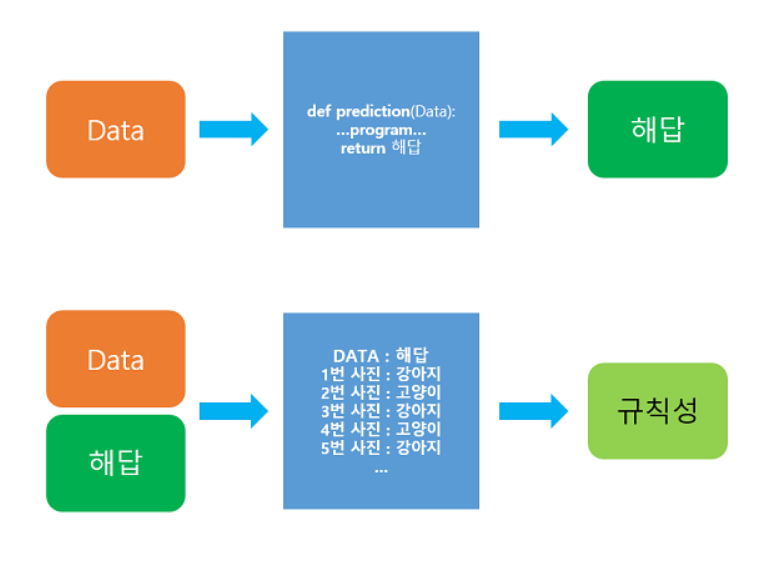
주어진 데이터로부터 결과를 찾는 게아니라, 주어진 데이터를 이용해 규칙성을 찾는다. 이 과정을 학습(training)이라 한다. 기존의 프로그래밍 방식에서 얻은 해답을 데이터와 함께 인풋으로 넣어 규칙성을 찾는 것. 어떻게 보면 사람이 학습하는 과정과 유사. 이런 이유로 기계학습이 조명받게 된 것이라 생각.
2) 머신러닝 훑어보기
1. 머신 러닝 모델의 평가
하이퍼파라미터와 매개변수의 가장 큰 차이는 하이퍼파라미터는 보통 사용자가 직접 정해줄 수 있는 변수라는 점입니다. 뒤의 선형 회귀 챕터에서 배우게 되는 경사 하강법에서 학습률(learning rate)이 이에 해당되며 딥 러닝에서는 은닉층의 수, 뉴런의 수, 드롭아웃 비율 등이 이에 해당됩니다. 반면 여기서 언급하는 매개변수는 사용자가 결정해주는 값이 아니라 모델이 학습하는 과정에서 얻어지는 값입니다. 정리하면 절대적인 정의라고는 할 수 없지만, 하이퍼파라미터는 사람이 정하는 변수인 반면, 매개변수는 기계가 훈련을 통해서 바꾸는 변수

- 예측은 positive, negative를 의미하고, 정답은 True, False를 의미한다. TN(True Negative) -> negative 예측이 맞은 경우.
FN(False Negative) -> negative 예측이 틀린 경우.
FP(Flase Positive) -> positive 예측이 틀린 경우.
TP(True Positive) -> positive 예측이 맞은 경우.

- 정밀도는 양성이라고 대답한 경우 중 양성이 맞은 비율
- 재현율(=sensitivity)은 실제 양성 중에 양성을 맞춘 비율

- Specificity는 sensitivity와 같이 사용 됨.
- 이 둘은 trade-off의 성향을 보임. 어느 하나를 높이면 어느 하나가 낮아짐.
- 민감도와 특이도 중 중요한 지표가 뭐냐에 따라 Threshold 값을 조절해주면 됨. 보통 이 값을 0.5로 확률이 이것보다 크면 1, 작으면 0으로 분류하는데 1인 클래스를 잘 맞추는게 중요하다하면 Threshold 값을 0에 가깝게 낮추고, 0을 잘 맞추는게 중요하다면 1에 가깝게 올림.
특이도를 통해서 False Positive Rate를 구할 수 있는데 이는 환자가 아닌데 환자라고 예측하는 경우로써 False Positive Rate = 1 - Specificity 로 나타낼 수 있습니다. 1 - 특이도도 또한 AUC를 산출하는 과정에서 중요한 지표로써 작용하니 참고

3) 선형 회귀
1. 선형 회귀
x를 독립적인 변수, y를 x에 의해 영향을 받는 종속적인 변수라고 보통 지칭하고, x와 y의 선형 관계를 모델링 하는 것을 말함. x가 1개라면 단순 선형 회귀라고 함. 2개 이상부터 중회귀(다중 선형 회귀)라고 함.

이런 수식들을 딥러닝에선 가설 H(x)로 표현 함.
cost function(비용 함수)는 MSE라고 생각하면 됨.
-> 가설함수를 통해 나온 값과 실제 값의 차의 제곱낸 것의 평균.

출처: https://sosoeasy.tistory.com/287
머신러닝과 딥러닝의 학습은 결국 저 코스트를 0에 가깝게 최소화 하는 Weight와 bias를 찾아가는 과정임. 이 찾아과는 과정에 사용되는 알고리즘이 옵티마이저 또는 최적화 알고리즘.
가장 많이 쓰이는 Gradient Descent(경사 하강법)을 생각해보자.
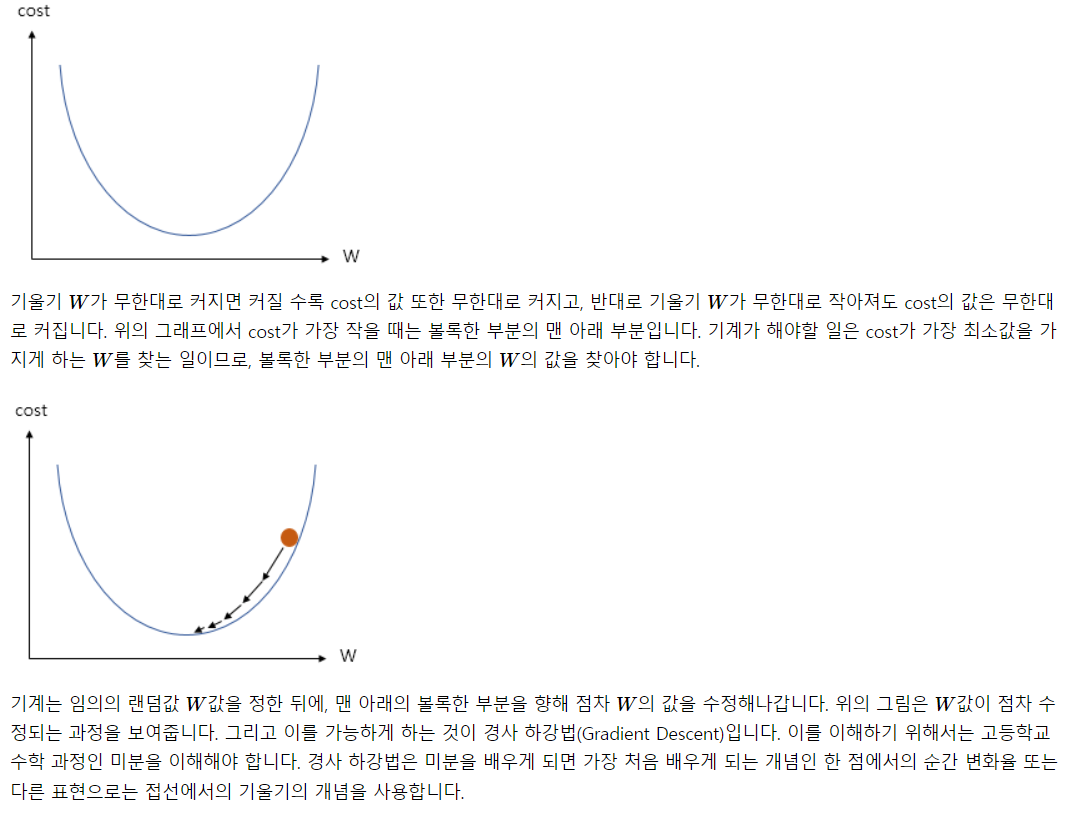
x축에 W를, y축에 cost를 매핑했고, 저 중간에 미분했을 때 기울기가 0이 되는 지점을 찾아가는 것! 왜 cost는 2차 방정식의 형태냐? -> MSE가 오차의 제곱 이므로.
learning rate에 따라 조금씩 x축을 움직이며 저 0이 되는 지점을 찾아가는 것.
학부 때 생각해보면, 회귀식의 Beta들. 딥러닝에선 Weight.를 찾는 과정에서 두 개의 방법이 쓰였다. 1) 최소제곱법, 2) 최대우도.
보통 최소제곱법을 많이 썼고, 이 Beta 찾는 방법이 저 접선의 기울기 0이 되는 지점이었음. 이 과정을 구현한게 머신러닝과 딥러닝. 저 찾아가는 과정을.
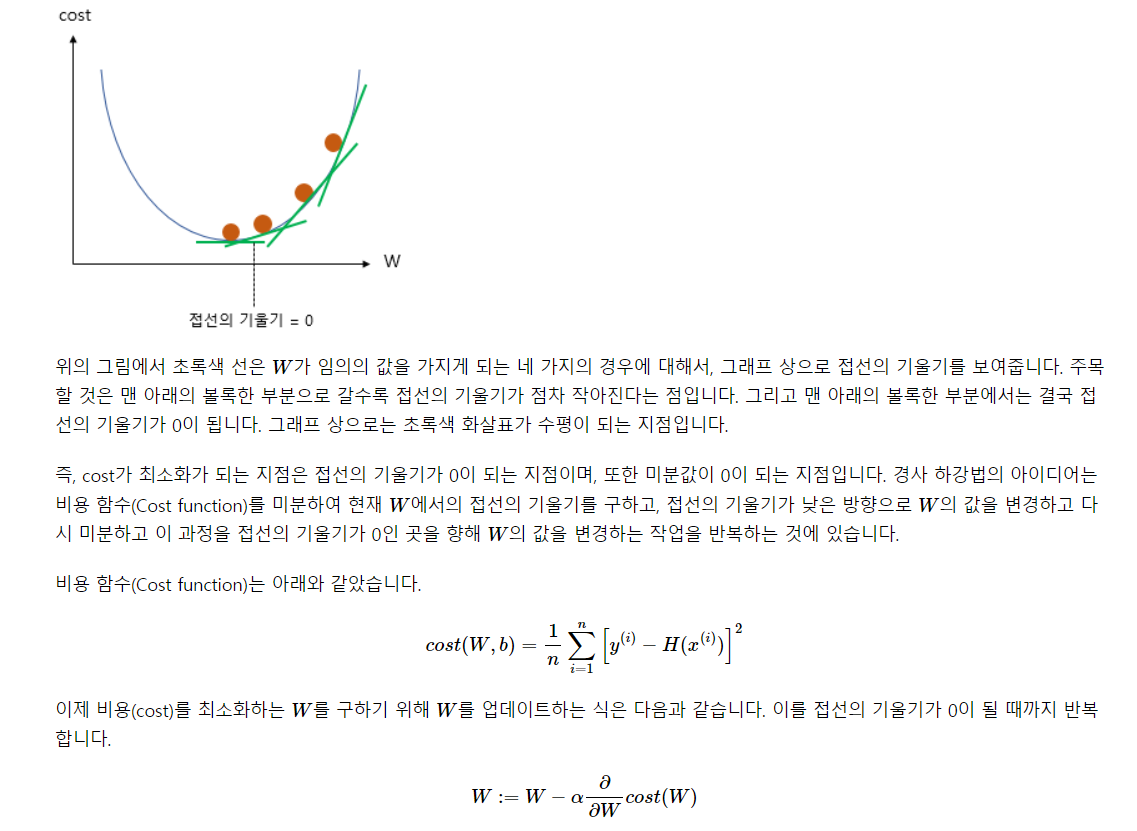

- cost에 대해 미분해준 값에 학습률을 곱해주고 이걸 weight에서 빼줌.
- 학습률을 크게하면 움직이는 폭이 커진다. 이 말은, 저 0이 되는 지점을 그냥 지나칠 수도 있는 것.
- 학습률을 작게하면 움직이는 폭이 작음. 이 말은, 저 0이 되는 지점을 지나칠 가능성이 낮음
- 하지만 이 둘은 또 트레이드 오프임. 학습률이 작으면 비교적 최적에 잘 도달하지만, 이 시간이 엄청 오래걸림. 시간 자체도 비용이므로 고려해야 함
- 학습률이 높으면 최적을 지나칠 수는 있지만 시간이 적게 소요.
- 그래서 잘 선택해야 함. GD말고 다양하게 있음.
4) 자동 미분과 선형 회귀
텐서플로우의 Gradient.Tape()을 이용해 미분이 구현 가능
임의로 H(w) = 라는 식을 세워보고 w에 대해 미분
import tensorflow as tf
w = tf.Variable(2.)
def f(w):
y = w**2
z = 2*y + 5
return z
## 미분
with tf.GradientTape() as tape:
z = f(w)
## f(w)를 w에 대해 미분
gradient = tape.gradient(z, [w])
print(gradient)[<tf.Tensor: shape=(), dtype=float32, numpy=8.0>]의 미분은 . 값이 2였으므로 그 값은 8.
2. 자동 미분을 이용한 선형 회귀 구현
### 초기 가설 정의 H(x) = Wx + b
w = tf.Variable(4.)
b = tf.Variable(1.)
@tf.function
def hypothesis(x):
return w*x + b
x_test = [3.5, 5, 5.5, 6]
print(hypothesis(x_test).numpy())[15. 21. 23. 25.]## 평균 제곱오차 정의
@tf.function
def mse_loss(y_pred, y):
# 두 개의 차이 값을 제곱해서 평균을 취함.
return tf.reduce_mean(tf.square(y_pred - y))
x = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 공부 시간
y = [11, 22, 33, 44, 53, 66, 77, 87, 95] # 공부 시간과 매핑되는 점수
optimizer = tf.optimizers.SGD(.01) # SGD를 옵티마이저로 사용하고, 학습률은 0.01
## 300번 반복해서 W, b를 찾아감
for i in range(301):
with tf.GradientTape () as tape:
y_pred = hypothesis(x)
cost = mse_loss(y_pred, y)
gradients = tape.gradient(cost, [w, b]) # cost에 대해 w와 b에 대해 미분한 값을 넣어줌
# 파라미터 업데이트. -> x축 상에서 움직이는 것. w와 b가 바뀜
optimizer.apply_gradients(zip(gradients, [w, b]))
if i % 10 == 0:
print('epoch: {:3} | w의 값: {:5.4f} | b의 값: {:5.4} | cost: {:5.6f}'.format(i, w.numpy(), b.numpy(), cost))epoch: 0 | w의 값: 9.6918 | b의 값: 1.894 | cost: 173.778076
epoch: 10 | w의 값: 10.4979 | b의 값: 1.972 | cost: 1.348798
epoch: 20 | w의 값: 10.5054 | b의 값: 1.925 | cost: 1.325962
epoch: 30 | w의 값: 10.5126 | b의 값: 1.88 | cost: 1.304935
epoch: 40 | w의 값: 10.5195 | b의 값: 1.837 | cost: 1.285576
epoch: 50 | w의 값: 10.5261 | b의 값: 1.795 | cost: 1.267737
.... 중략 ....
epoch: 300 | w의 값: 10.6271 | b의 값: 1.159 | cost: 1.086422경사하강법의 로직에 따라 하나 학습해서 cost 구하고 미분해서 이동하고, 계속 반복해서 cost가 최소로 되는 지점까지 찾아감.
300번의 epoch이 끝났고 최종 얻은 params는 w: 10.6269, b: 1.161. 원래 초기 설정한 w는 4, b는 1이었음.
## 학습된 모델에 임의의 값을 넣고 예측결과 확인
x_test = [3.5, 5, 5.5, 6]
hypothesis(x_test).numpy()array([38.35414 , 54.294846, 59.60841 , 64.92198 ], dtype=float32)w와 b값이 계속 업데이트 되었으므로 hypothesis의 w와 b도 계속 업데이트. w와 b는 계속 바뀌었고 hypothesis 함수 안에서 w와 b를 생성한 것이 아닌, 함수 외부에 있는 변수를 이용하는 것이므로!
3. 케라스로 선형회귀 구현
api를 활용하면 훨씬 쉽게 구현이 가능하다.
Sequential을 이용해 모델을 생성하고, add를 통해 정보들을 추가해서 모델 설계
model = keras.models.Sequential()
model.add(keras.layers.Dense(1, input_dim = 1)이런식으로 모델을 설계해나간다.
Dense에 첫번째 인자는 출력의 차원, 두 번째는 입력의 차원
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
X = [1, 2, 3, 4, 5, 6, 7, 8, 9]
y = [11, 22, 33, 44, 53, 66, 77, 87, 95]
# 비어있는 모델 생성.
# Sequential은 레이어를 하나씩 추가하며 모델을 설계
# 하나씪 추가하므로 누적되어 가는 과정을 알 수 있음
model = Sequential()
## 첫 레이어를 쌓은 것이고, x, y 차원이 1.
## 선형회귀 이므로 활성화 함수는 lienar!
model.add(Dense(1, input_dim = 1, activation = 'linear'))
# sgd. lr = .01
sgd = optimizers.SGD(lr = .01)
# loss function은 mse를 사용
# sgd를 따로 생성 안하고 loss에서 문자열로 지정한 것처럼
# 'sgd'도 가능할 것. 근데 그건 디폴트 sgd를 써야함.
# lr의 변화를 주고싶다면 위에서처럼 생성해서 써야함.
model.compile(optimizer = sgd, loss = 'mse', metrics = ['mse'])
# X, y의 오차 최소화를 위한 훈련 300번
model.fit(X, y, batch_size = 1, epochs = 300, shuffle = False)Epoch 1/300
9/9 [==============================] - 0s 2ms/step - loss: 388.3102 - mse: 388.3102
Epoch 2/300
9/9 [==============================] - 0s 2ms/step - loss: 2.3133 - mse: 2.3133
Epoch 3/300
9/9 [==============================] - 0s 2ms/step - loss: 2.3071 - mse: 2.3071
Epoch 4/300
9/9 [==============================] - 0s 2ms/step - loss: 2.3011 - mse: 2.3011
Epoch 5/300
9/9 [==============================] - 0s 2ms/step - loss: 2.2954 - mse: 2.2954
... 중략 ....
Epoch 300/300
9/9 [==============================] - 0s 2ms/step - loss: 2.1460 - mse: 2.1460
<keras.callbacks.History at 0x7f2eb1e10810>9/9 는 sample의 사이즈. 배치 사이즈를 1로 지정했으므로. 배치 사이즈는 한 번에 학습시킬 묶음의 사이즈를 뜻함
컴퓨팅 성능의 한계로 미니배치를 자주 이용.
총 300번의 반복을 지정했기 때문에 epochs는 300
import matplotlib.pyplot as plt
plt.plot(X, model.predict(X), 'b', X,y, 'k.',)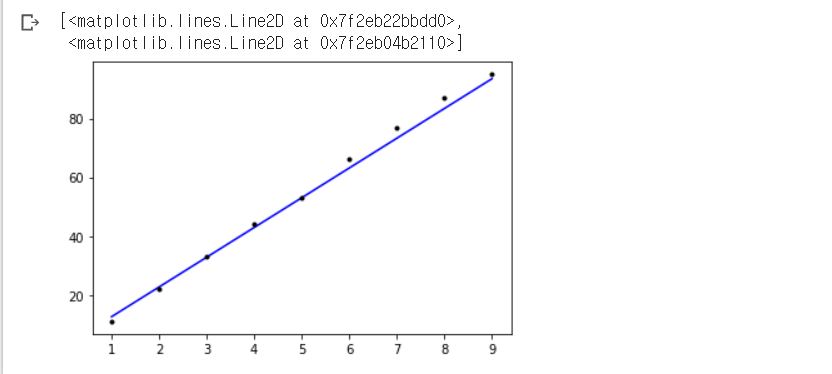
저 점들은 실제 주었던 실제 값에 해당되고, 직선은 오차를 최소화 한 W, b를 가지는 직선.
애초에 데이터의 분포를 보면 선형 관계가 뚜렷하므로 이런 경우엔 아주 good.
model.predict()는 머신러닝에서 처럼 훈련된 모델에서 입력값을 바탕으로 출력값을 얻는 것.

노란색 부분이 저 파란 선을 그은 것이고(X에 대해서 모델로 예측한 y 값 -> 이게 학습된 모델), 초록색 밑줄이 점을 그려준 것.
plt.plot()은 기본적으로 line plot을 그려줌
그리고 그냥 'b'면 파란색이고 기본이 line이므로 파란 선을 그리지만, 'b.'을 하면 파란색 점을 그려줌!!! 'k.'이 검정 점인 것도 그 이유 !!
5) 로지스틱 회귀
앞서 한 선형회귀는 수치예측과 같은 Regression 문제를 해결하는 모델이고, 로지스틱 회귀는 범주 예측, 분류등의 Classfication 문제 해결을 위한 모델이다. 선형모델을 사용하되 log-odds 변환을 통해 0~1 사이의 확률 값으로 결과를 매핑해주는 것.
1. 이진분류
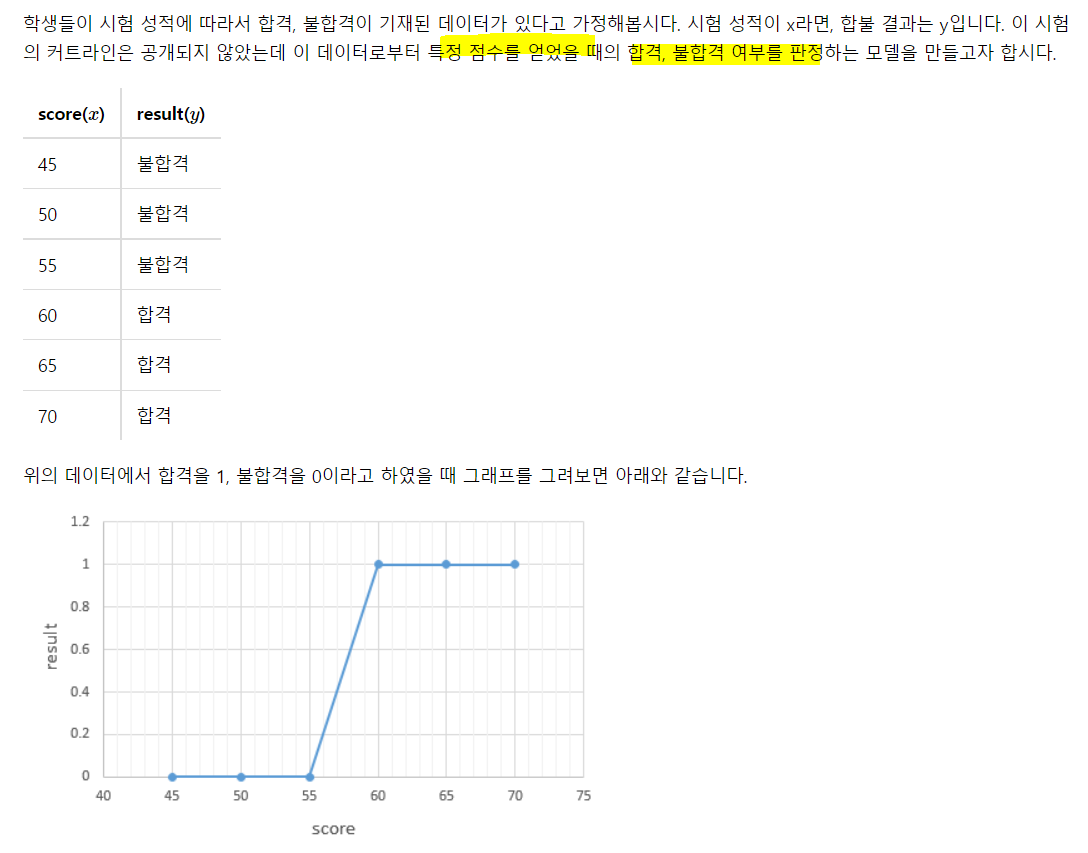

보통 Threshold를 0.5로 함. 앞서 말했던 것처럼 민감도 혹은 특이도 중 어떤것이 중요하냐에 따라 Threshold를 조정!
2. 시그모이드 함수

## sigmoid 구현
def sigmoid(x):
return 1 / (1+np.exp(-x))
x = np.arange(-5., 5., .1)
y = sigmoid(x)
plt.plot(x, y, 'g')
plt.plot([0,0], [1.,0.], ':') # 점선 추가
plt.title('sigmoid')
plt.show()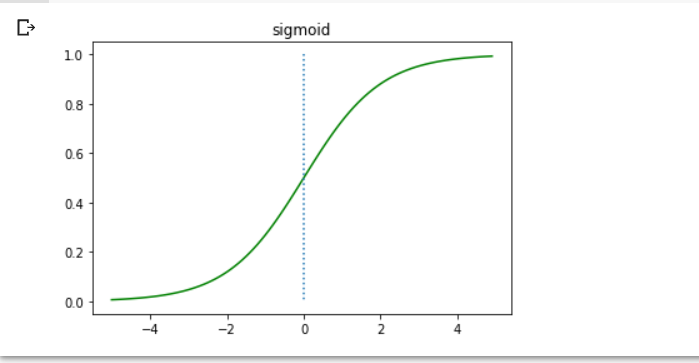
w는 1, b는 0임을 가정한 그래프!
w와 b의 변화에 따라 어떻게 달라지는지 확인
x = np.arange(-5., 5., .1)
y1 = sigmoid(0.5*x) # w = 0.5
y2 = sigmoid(x) # w = 1
y3 = sigmoid(2*x) # w= 2
plt.plot(x, y1, 'r', linestyle = '--') # w = 0.5
plt.plot(x, y2, 'g') # w = 1
plt.plot(x, y3, 'b', linestyle = '--') # w = 2
plt.plot([0, 0], [1., 0.], ':')
plt.title('Sigmoid with variety w')
plt.show()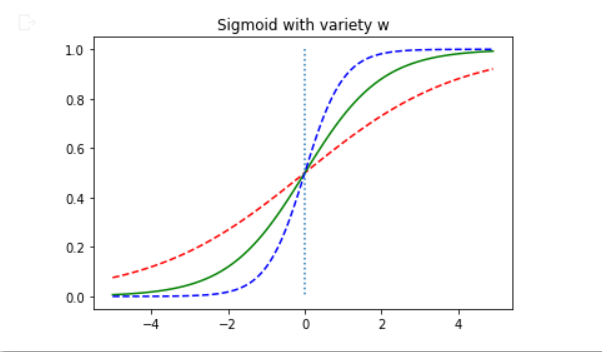
파란색이 w = 2, 빨간색이 w = 0.5
w가 커질수록 s자 부분이 더 0에 가까워져가는 듯. -> 경사가 더 가파르게 변함
x = np.arange(-5., 5., .1)
y1 = sigmoid(x + 0.5) # b = 0.5
y2 = sigmoid(x + 1) # b = 1
y3 = sigmoid(x + 2) # b= 2
plt.plot(x, y1, 'r', linestyle = '--') # b = 0.5
plt.plot(x, y2, 'g') # b = 1
plt.plot(x, y3, 'b', linestyle = '--') # b = 2
plt.plot([0, 0], [1., 0.], ':')
plt.title('Sigmoid with variety b')
plt.show()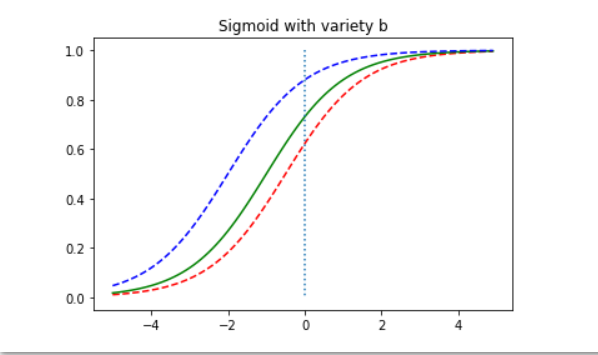
파란색이 b = 2, 빨간색이 b = 0.5. b 값은 커질수록 더 왼쪽으로 움직이면서 결국 왼쪽 상단에 가까워지면서 90도의 모양이 되는듯?
3. 비용함수
로지스틱 회귀도 경사 하강법과 같은 옵티마이저로 wegiht를 찾지만, 비용 함수로는 평균제곱오차 사용 X.
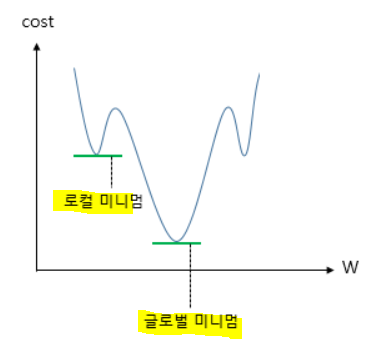
위와 같은 형태를 띄므로 로컬 미니멈에서 멈출 수 있음
따라서 새로운 비용함수를 써야함.


그냥 두 함수를 활용해 적절한 보정을 해서 0, 1에 따라 그 비용함수를 사용할 수 있게 크로스엔트로피를 만들었음. 로지스틱 회귀의 비용함수는 크로스엔트로피를 평균낸 것을 사용하고!!
6) 텐서플로우로 로지스틱 실습
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
X = np.array([-50, -40, -30, -20, -10, -5, 0, 5, 10, 20, 30, 40, 50])
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) # x = 10부터 1
model = Sequential()
# 로지스틱 회귀이므로 활성함수는 activation
# 이 과정을 sklearn의 linear_model에서 LogisticRegression 써도 됨
model.add(Dense(1, input_dim = 1, activation = 'sigmoid'))
# sgd, 손실함수는 binary crossentropy(이진 크로스 엔트로피)
sgd = optimizers.SGD(lr = .01)
model.compile(optimizer = sgd, loss = 'binary_crossentropy', metrics = ['binary_accuracy'])
model.fit(X, y, batch_size = 1, epochs = 200, shuffle = False)Epoch 1/200
13/13 [==============================] - 0s 2ms/step - loss: 0.6201 - binary_accuracy: 0.9231
Epoch 2/200
13/13 [==============================] - 0s 2ms/step - loss: 0.5992 - binary_accuracy: 0.9231
Epoch 3/200
13/13 [==============================] - 0s 1ms/step - loss: 0.5783 - binary_accuracy: 0.9231
Epoch 4/200
13/13 [==============================] - 0s 1ms/step - loss: 0.5574 - binary_accuracy: 0.9231
... 중략 ....
Epoch 200/200
13/13 [==============================] - 0s 2ms/step - loss: 0.0880 - binary_accuracy: 1.0000
<keras.callbacks.History at 0x7f2eb35225d0>총 200회에 걸쳐 w와 b를 찾는 과정을 거침. accuracy는 1이 되었음..
실제 값과 오차를 최소화 한 w, b로 시그모이드 함수를 그려보자
plt.plot(X, model.predict(X), 'b', X, y, 'k.')
plt.plot([-50, 50], [0.5, 0.5], ':')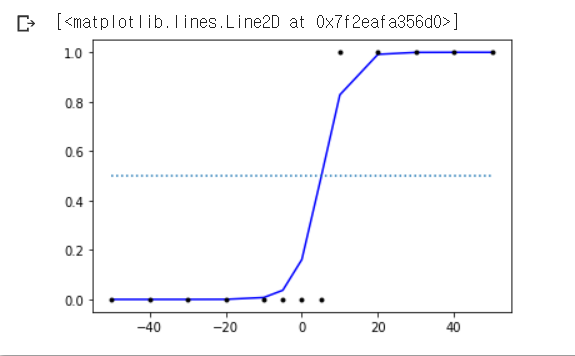
- 특정 지점 이후로 0.5의 확률 값. 아마 5에서 10 사이 그 갑일 때 인듯
- 5보다 작을때와 10보다 큰 값에대해 어떤 확률을 리턴하는지 확인
print(model.predict([1,2,3,4,4.5]))
print(model.predict([6,7,8,9,10]))[[0.20964664]
[0.26796517]
[0.33561748]
[0.41076577]
[0.4502259 ]]
[[0.5703722 ]
[0.64690334]
[0.716576 ]
[0.77723503]
[0.82802737]]- 5보다 작을 떈 0.5보다 작고, 5보다 크면 0.5보다 큼
7) 다중 입력에 대한 실습
x가 2개 이상인 로지스틱 회귀에 대한 실습~
1. 다중 선형 회귀
실생활에서 변수가 하나면 너무 좋겠지만, 정확도를 위해 보통 다수의 변수를 사용한다. 따라서 이를 실습
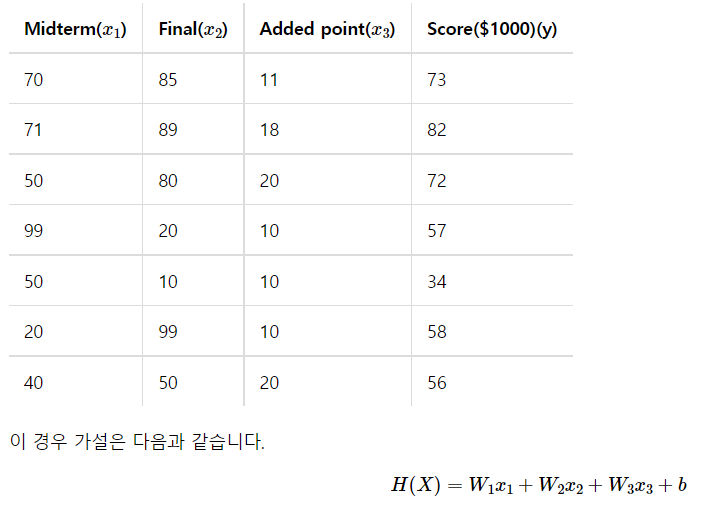
이 데이터를 사용하고, x들로 y를 예측!
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# 입력 벡터의 차원은 3입니다. 즉, input_dim은 3입니다.
X = np.array([[70,85,11],[71,89,18],[50,80,20],[99,20,10],[50,10,10]]) # 중간, 기말, 가산점
# 출력 벡터의 차원은 1입니다. 즉, output_dim은 1입니다.
y = np.array([73,82,72,57,34]) # 최종 성적
model=Sequential()
model.add(Dense(1, input_dim=3, activation='linear'))
# 학습률(learning rate, lr)은 0.00001로 합니다.
sgd=optimizers.SGD(lr=0.00001)
# 손실 함수(Loss function)은 평균제곱오차 mse를 사용합니다.
model.compile(optimizer = sgd ,loss='mse',metrics=['mse'])
# 주어진 X와 y데이터에 대해서 오차를 최소화하는 작업을 2,000번 시도합니다.
model.fit(X,y, batch_size=1, epochs=2000, shuffle=False)epoch이 2000이므로 돌아가는 시간이 꽤 됨.
앞선 코드와 별 차이는 없고 dense에서 입력 차원이 3차원 이므로 input_dim이 3으로 바뀐 것 뿐.
Epoch 1/2000
5/5 [==============================] - 0s 2ms/step - loss: 1062.2842 - mse: 1062.2842
Epoch 2/2000
5/5 [==============================] - 0s 2ms/step - loss: 619.6295 - mse: 619.6295
--- 중략 ---
5/5 [==============================] - 0s 3ms/step - loss: 0.0274 - mse: 0.0274
Epoch 1999/2000
5/5 [==============================] - 0s 3ms/step - loss: 0.0273 - mse: 0.0273
Epoch 2000/2000
5/5 [==============================] - 0s 3ms/step - loss: 0.0273 - mse: 0.0273
<keras.callbacks.History at 0x7f2eaf953d90>#예측-> 학습한 값에 대해
print(model.predict(X))[[73.09192 ]
[81.97716 ]
[71.968925]
[57.153507]
[33.69886 ]]X_test = np.array([[20, 99, 10], [40, 50, 20]]) # 58, 56이 각각의 정답
print(model.predict(X_test))[[58.02091]
[55.81251]]소수점까지 정확하진 않지만, 거의 정확함. 사실 이 데이터는 x로 만들어낸 y인 것이므로 그 weight를 찾는 것이 너무 쉬운 것이고, 실제 데이터에선 y가 어떤 X에 의해 만들어진 것인지 알 수가 없음. 그래서 최대한 많은 X를 구해서 넣어보고 돌리면서 제거하던지 하는 것!
2. 다중 로지스틱 회귀

이것도 똑같음. 주의할 것이 하나 있는데, 만약 이런 변수 여러개를 사용해서 y를 찾아 간다면, X의 고유한 효과만 볼 것이 아니라 X1 * X2와 같은 interaction도 고려해야 함. 근데 둘이 관계가 없다면 굳이?
# 입력은 2차원
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
# 출력은 1차원
y = np.array([0, 1, 1, 1])
model = Sequential()
model.add(Dense(1, input_dim = 2, activation = 'sigmoid'))
model.compile(optimizer = 'sgd', loss = 'binary_crossentropy', metrics = ['binary_accuracy'])
model.fit(X, y, batch_size = 1, epochs = 800, shuffle = False)Epoch 1/800
4/4 [==============================] - 0s 46ms/step - loss: 0.9076 - binary_accuracy: 0.5000
... 중략 ...
Epoch 800/800
4/4 [==============================] - 0s 2ms/step - loss: 0.2222 - binary_accuracy: 1.0000# 예측
print(model.predict(X))[[0.4274996 ]
[0.86555034]
[0.84432185]
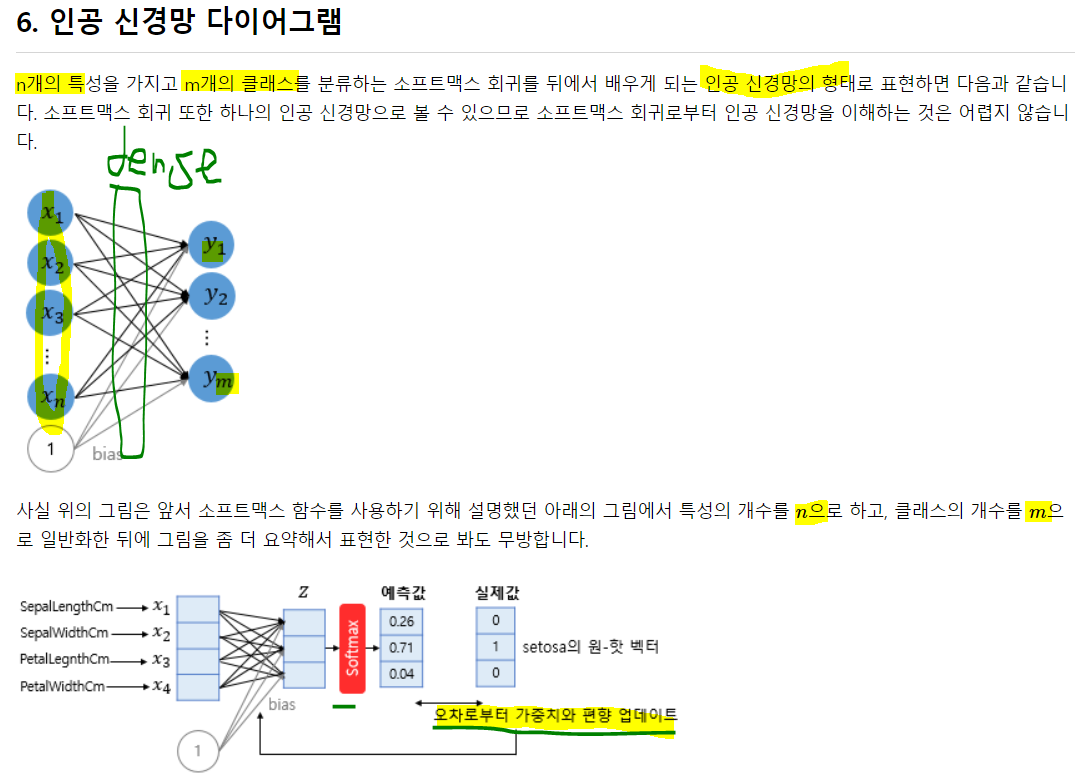
[0.97906095]]인공 신경망 다이어그램

8) 벡터와 행렬 연산
소프트맥스 회귀의 경우 y의 종류도 3개 이상이 되면서 더욱 복잡해짐.
넘파이, 텐서플로우의 경우 로우 레벨 머신러닝 개발을 핳게되면 각 변수들의 연 산을 벡터와 행렬의 연산으로 이해할 수 있어야 함!
내가 직접 데이터와 변수의 개수로부터 행렬의 크기, 텐서의 크기를 산정할 수 있어야 함
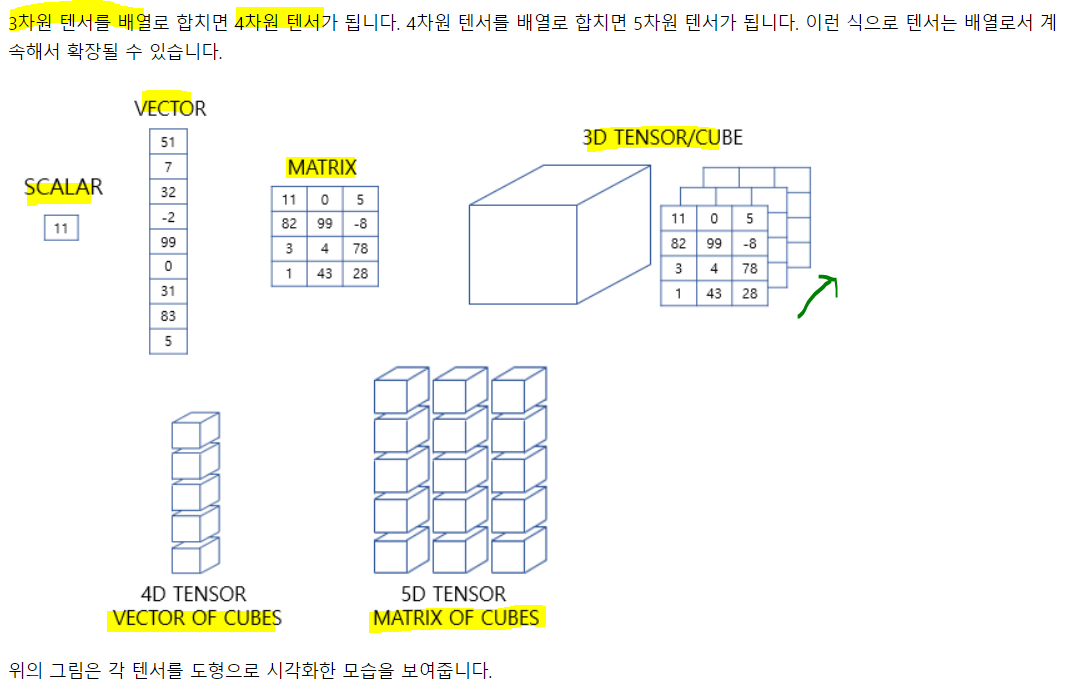
1. 벡터와 행렬과 텐서
- 벡터는 크기와 방향을 가진 양. 사실 벡터도 1차원 행렬임
- 행렬은 2차원 형상을 가진 구조
- 3차원부터는 주로 텐서라고 부른다. 2차원 행렬도 텐서가 맞긴 함.
2. 텐서
- 신경망은 복잡한 모델 내 연산을 주로 행렬을 이용. 머신러닝의 입출력이 복잡해지면서 3차원의 개념 이해는 필수적. 이걸 못하면 RNN이 쉽지 않음. 그래서 내가 어려운듯...
1) 0차원 텐서
스칼라는 하나의 실수 값으로 이루어진 데이터이고, 이를 0차원 텐서라고 함
d = np.array(5)
print(d.ndim) # 차원 확인
print(d.shape) # 크기 출력0
()ndim은 축의 수를 출력하고, 이는 차원의 수와 동일.
2) 1차원 텐서
- 벡터를 1차원 텐서라고 함. 주의할 점은 벡터의 차원과 텐서의 차원은 다름
- 벡터의 경우[1,2,3,4,5]라면 5차원. 하지만 이게 텐서의 5차원은 아님.
d = np.array([1,2,3,4])
print(d.ndim)
print(d.shape)1
(4,)단순 벡터는 (4,)로 표시. (4,1)과 같은 형태지만, (4,) != (4,1)임.
2) 2차원 텐서
행렬을 2차원 텐서라고 함
d = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print(d.ndim)
print(d.shape)2
(3, 4)2차원이고, 3행 4열짜리 매트릭스임. 보통 어레이에서 맨 앞의 [[를 보고 차원을 계산함(나는)
또한, d를 파헤쳐보면 리스트 세개가 원소로 있고, 각 리스트 내에는 스칼라 원소가 4개가 있음. 그래서 3행 4열!
4) 3차원 텐서
- 2차원 텐서나 행렬을 단위로 한번 더 배열하면 3차원이 됨.
d = np.array([
[[1,2,3,4,5], [6,7,8,9,10], [11,12,13,14,15]],
[[1,2,3,4,5], [6,7,8,9,10], [11,12,13,14,15]]
])
print(d.ndim)
print(d.shape)3
(2, 3, 5)
먼저 저 긴 2차원 텐서가 2개가 있으므로 맨 앞은 2, 그리고 각각의 텐서는 1차원 텐서 3개로 이뤄져 있으므로 3, 1차원 텐서는 5개의 스칼라로 이뤄져 있으므로 5.
생각보다 그렇게 어렵지 않을수도 있음. 어렵게 생각하지 말고 천천히 생각하기.


배치 사이즈 3이므로 2차원 텐서 3개, 시퀀스(한 문장)의 길이도 3이므로 2차원 텐서 내에 1차원 텐서들이 3개, 1차원 텐서엔 6개의 토큰에 대한 원핫 스칼라 값이 있으므로 6
만약 위의 형태의 데이터가 문서가 30개가 있다면, 30행짜리 원핫의 형태는 30행 * 토큰의 수가 됨. 여기서 배치사이즈가 3이라면 (3, 토큰의 수, 원핫 벡터의 길이)의 형태이고, 이 shape이 10개가 됨.
6) 케라스에서의 텐서
위에선 넘파이를 사용했다. 케라스도 마찬가지인데, 입력의 크기를 인자로 준다면 input_shape을 써야 함. 배치 크기를 제외하고 차원을 지정한다. 따라서 (10, 20)이라면 2차원이 인풋이 아님. (배치 사이즈, 10, 20) 3차원이 되는 것임.
만약 배치 크기까지 지정하고 싶다면 -> batch_input_shape을 지정하기.
이 외에도 입력의 속성 수를 의미하는 input_dim, 시퀀스의 길이를 의미하는 input_length가 있다. input_shape은 (input_length, input_dim)임.
3. 벡터와 행렬의 연산
1) 벡터, 행렬의 덧셈과 뺄셈

a = np.array([8, 4, 5])
b = np.array([1, 2, 3])
print(a + b)
print(a - b)[9 6 8]
[7 2 2]
a = np.array([[10, 20, 30, 40], [50,60,70,80]])
b = np.array([[5,6,7,8], [1,2,3,4]])
print(a+b)
print(a-b)[[15 26 37 48]
[51 62 73 84]]
[[ 5 14 23 32]
[49 58 67 76]]2) 내적과 곱셈
dot product와 inner product!

a = np.array([1,2,3])
b = np.array([4,5,6])
print(np.dot(a,b))32
이런식으로 계산 됨.
a = np.array([[1,3], [2,4]])
b = np.array([[5,7], [6,8]])
print(np.matmul(a, b))[[23 31]
[34 46]]3. 다중 선형 회귀 행렬 연산으로 이해하기


자꾸 이런식으로 표현을 하는 이유는 복잡한 수식을 행렬을 이용해 쉽게 표현할 수 있음. 표현된다면 계산하는 것도 어려운 것이 아니므로. 하지만 이걸 처음 한다면 조금 많이 헷갈리니까 좀 주의.

이런 식으로 두 가지로 표현이 가능해서 상당히 헷갈림. 하지만 늘 그렇듯 차분하게 앉아서 생각을 해보면 이해가 됩니다... 안되면 더 차분히 앉아서 생각하세요.

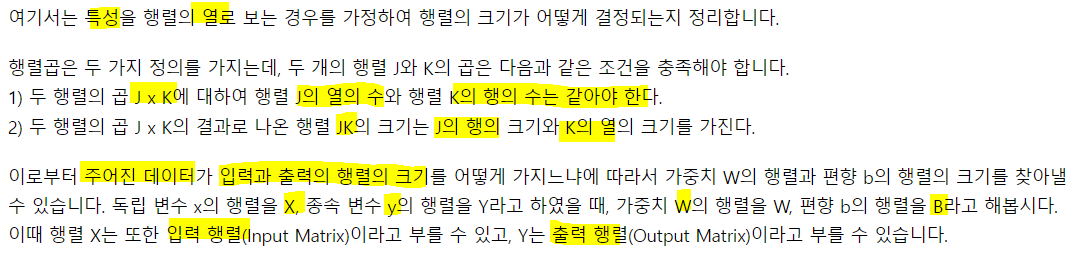
- 샘플을 관측치라고도 함. 보통 이런식으로 데이터가 구성되어 있으므로 위에서 본 두 가지 방법중에 H(X) = WX + b보다 XW + b를 사용
5. 가중치와 편향 행렬의 크기 결정

9) 소프트맥스 회귀 - 다중 클래스 분류
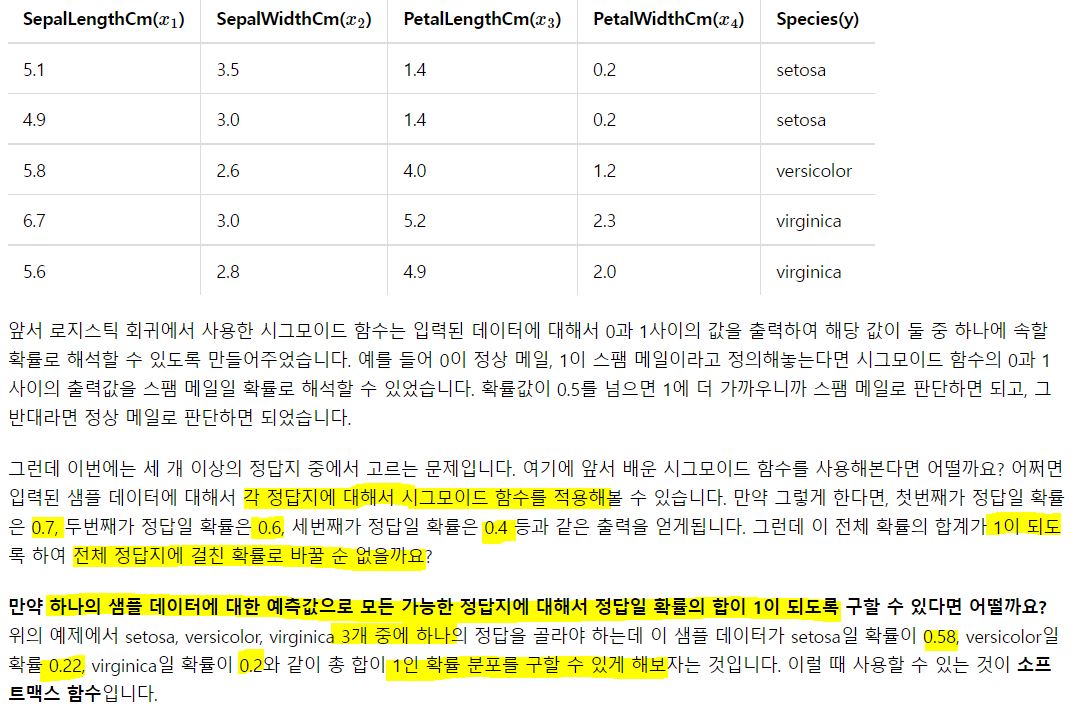



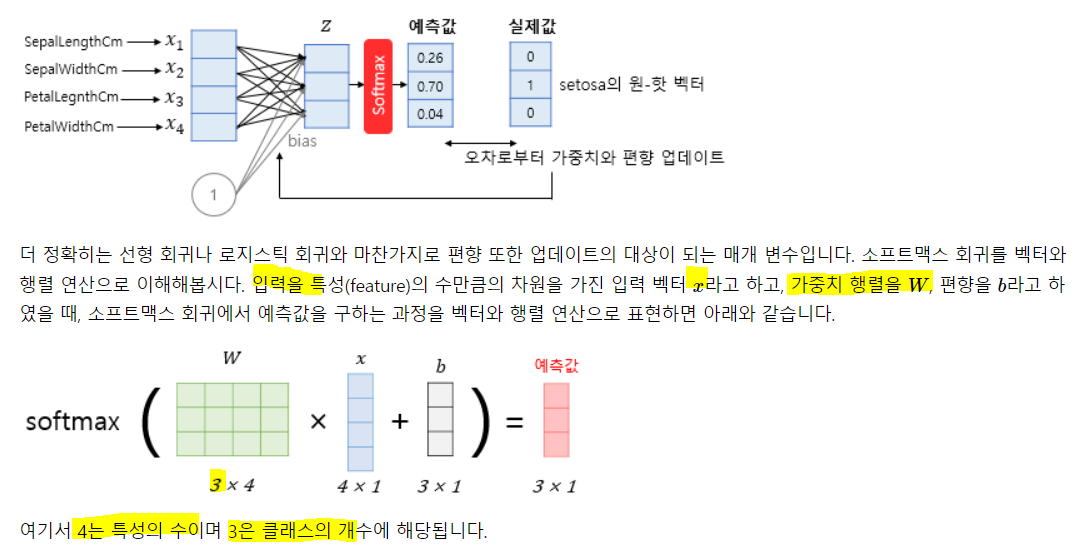
음 그냥, 로지스틱 회귀식이 클래스의 수 만큼 주어진다 생각하고 각 회귀식의 합 중 각 회귀식의 비율로 확률을 추출한다고 생각!
각각의 로지스틱 회귀에서 확률 값을 계산하고, 그 확률값을 다 더하고 각각의 확률 값의 비율을 다중 클래스의 각각의 확률로 생각하는 것! 하나의 입력으로 여러 클래스의 확률을 계산하는 것이므로. 그냥 로지스틱 회귀의 확장이라 생각하면 될듯
원핫벡터의 무작위성
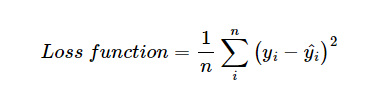

Cost Function


이진이든, 그 이상이든 크로스엔트로피를 이용해 loss를 계산하고 cost function은 이를 평균낸 것을 사용. 그리고 근본적으로는 같고 걍 치환해서 표기했냐 안했냐의 차이. 어렵게 생각할 것 없음. 소프트맥스는 다중(2개 이상의) 분류가 가능하고, 로지스틱은 이진 분류만 가능. 그래서 저 식에서
k=2, y1을 y, y2를 1-y, p1을 p, p2를 1-p로 치환만 하면 동일함.
5. 소프트맥스 회귀
import pandas as pd
data = pd.read_csv('/content/drive/MyDrive/산학협력프로젝트/딥러닝을 이용한 자연어 처리 입문/Iris.csv', encoding = 'latin1')
import seaborn as sns
## seaborn의 설정
sns.set(style = 'ticks', color_codes = True)
g = sns.pairplot(data, hue = 'Species', palette = 'husl')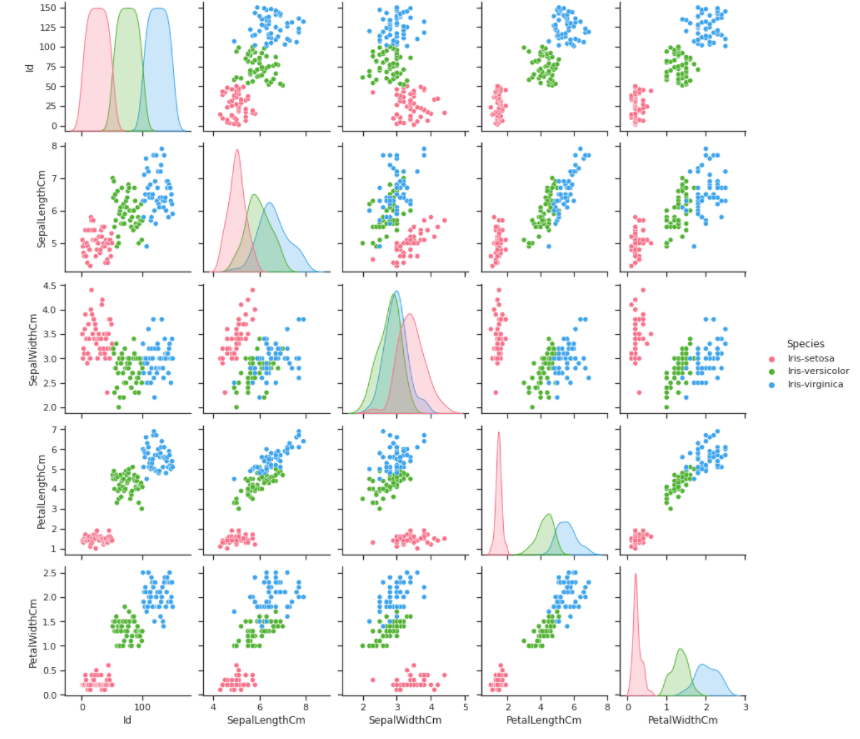
종별로 구분해서 분포를 봄. 총 세 가지를 시각화 한 것임. hue를 이용해서
클래스 세개 뿐이므로 우선 정수 인코딩
data.Species = data.Species.replace(['Iris-virginica', 'Iris-setosa', 'Iris-versicolor'], [0,1,2])
# virgin - 0, setosa - 1, versi - 2
sns.countplot(data.Species)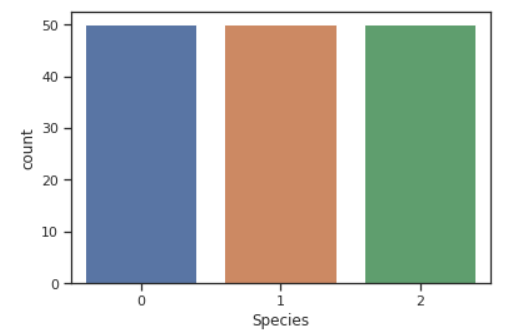
각 클래스의 불균형 없이 일-정. 만약 클래스 불균형이 존재한다면 어느 한 클래스에 대해서만 특화되므로 일반화가 될 수 없다. 따라서 오버샘플링으로 균형을 맞춰주거나 자르기도 하는데 둘 다 문제가 있음. 실제 분석 과제에선 이런 경우가 다반사임. 데이터를 추가로 수집하는게 제일 좋긴 한데 이건 비용과 시간이 많이 소요되므로. 해결하기 위해 샘플링을 통해 해결. 근데 이것도 주어진 것에서 파생되는거라 과적합의 문제가 발생 가능.
from sklearn.model_selection import train_test_split
data_X = data.iloc[:, 1:-1].values
data_y = data.iloc[:,-1].values
print(data_X[:5])
print(data_y[:5])[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[1 1 1 1 1]X_train, X_test, y_train, y_test = train_test_split(data_X, data_y, train_size = 0.8, random_state = 1)
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train) ## 원핫 인코딩
y_test = to_categorical(y_test)
print(y_train[:5])
print(y_test[:5])[[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]
[1. 0. 0.]
[1. 0. 0.]]
[[0. 1. 0.]
[0. 0. 1.]
[0. 0. 1.]
[0. 1. 0.]
[1. 0. 0.]]회귀
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
model = Sequential()
model.add(Dense(3, input_dim = 4, activation = 'softmax'))
model.compile(loss= 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# y를 one-hot 해줬응니까 categorical_crossentropy
# 안했다면 sparse_categorical_crossentropy
# optimizers는 sgd 말고 adam 써줌
## 에폭별로 업데이트 된 모델의 성능 평가를 위해 valid set을 넣어줌
## 이건 가중치 업데이트에 영향을 안미침
## history에 모델의 학습 과정에 대해 담아줌.
## 시각화에 유용하게 사용.
history = model.fit(X_train, y_train, batch_size = 1, epochs =200, validation_data = (X_test, y_test))Epoch 1/200
120/120 [==============================] - 1s 3ms/step - loss: 2.2589 - accuracy: 0.4583 - val_loss: 1.3255 - val_accuracy: 0.5000
Epoch 2/200
120/120 [==============================] - 0s 2ms/step - loss: 1.5292 - accuracy: 0.5333 - val_loss: 0.9971 - val_accuracy: 0.6333
Epoch 3/200
120/120 [==============================] - 0s 2ms/step - loss: 1.0665 - accuracy: 0.5833 - val_loss: 0.9025 - val_accuracy: 0.7000
--중략--
Epoch 198/200
120/120 [==============================] - 0s 2ms/step - loss: 0.1638 - accuracy: 0.9500 - val_loss: 0.1811 - val_accuracy: 1.0000
Epoch 199/200
120/120 [==============================] - 0s 2ms/step - loss: 0.1637 - accuracy: 0.9500 - val_loss: 0.1902 - val_accuracy: 1.0000
Epoch 200/200
120/120 [==============================] - 0s 2ms/step - loss: 0.1627 - accuracy: 0.9500 - val_loss: 0.1936 - val_accuracy: 0.9667acc는 훈련하고 나서 훈련셋에 대한 정확도이고, val_acc가 unseen set에 대한 정확도
에폭에 따른 정확도의 시각화를 해보자
epochs = range(1, len(history.history['accuracy']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss per each epoch')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'])
plt.show()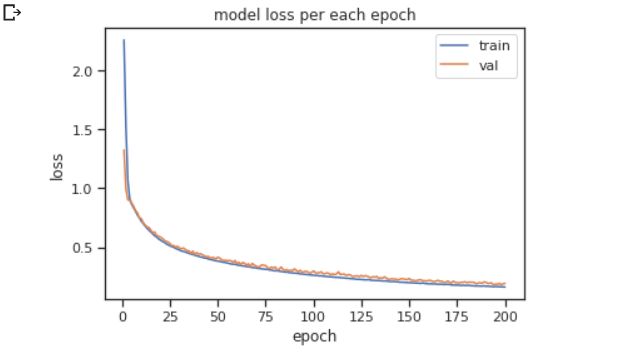
반복될수록 loss가 엄청 줄어드는 것을 볼 수 있음. 너무 많은 학습을 하게되면 과적합의 문제도 발생하므로 적절한 조절이 필요. 이건 딥러닝 부분에서 다뤄보기.
print('\n테스트 정확도: %.4f' %(model.evaluate(X_test, y_test)[1]))1/1 [==============================] - 0s 128ms/step - loss: 0.1936 - accuracy: 0.9667
테스트 정확도: 0.9667evaluate을 이용하면 test set에 대한 성능을 계산할 수 있다.
최종 모델의 정확도는 0.9667로 96% 정도의 정확한 분류가 가능!
텐서플로우를 이용해서 머신러닝해서 모델의 성능 평가할 땐 evaluate 이용하기. 사이킷런에선 .score를 이용했었음.