성능 평가 방법
1. Top N

출처: COVID-19 information retrieval...
2. Bpref

출처: COVID-19 information retrieval...
키워드&문장 / 절대평가 조합이 가장 검색도 빠르고 검색도 잘 될 것이다!
실험 1
- 키워드 / 상대평가
- 문장 / 상대평가
- 키워드&문장 / 상대평가
- 키워드 / 절대평가
- 문장 / 절대평가
- 키워드&문장 / 절대평가
가설 2
의미 단위로 문장 묶기 단계에서 코사인 유사도 0.5 이상을 같은 내용을 말하고 있는 문장쌍이라고 판단한다. 이렇게 했을 때 더욱 검색 성능이 좋을 것이다.
실험 2
- 한 문장씩 나눴을 때
- 임계값 0.1
- 임계값 0.2
- 임계값 0.3
- 임계값 0.4
- 임계값 0.5
- 임계값 0.6
- 임계값 0.7
- 임계값 0.8
- 임계값 0.9
실험 2 설계
- 검증 방법은 상대평가로한다.
- 검증 대상 데이터는 article_id 중 무작위로 100개만 뽑아서 고정한다.(전체 6천개 가량)
예상 결과
- 데이터 타입: pandas.DataFrame
- 열: ['article_id','sentence_index','target_sentence']
참고 자료
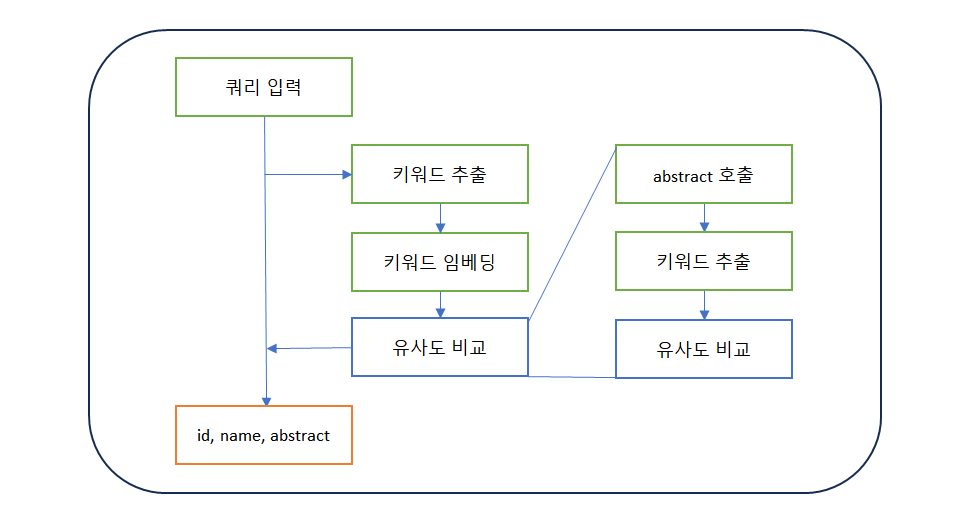
new 검색 알고리즘
- 키워드 유의어 - Abstract 키워드 추출
평가 지표 관련 아이디어
- A: 쿼리 키워드
- B: 정답 키워드
- C: A와 유사도 60%인 정답 아닌 논문 키워드
- D: A와 유사도 40%인 정답 아닌 논문 키워드
일 때 B와 C의 유사도가 50% 이상이면 괜찮음
1차로 A와 유사도가 50%이상인 애들 걸러 낸 다음
2차로 정답과 유사도가 50%이상인 애들이 몇개가 포함되어있는지를 성능지표로
아이디어 실험 결과



생각보다 낮다. 인용구의 키워드 추출, 타겟 논문의 abstract 키워드 추출해서 SBERT로 코사인유사도를 구한 결과이다. 적은 정보만으로 비교한 것인데 저정도이면 높은 것일 수 있다. 정답이 아닌 타겟 논문들과의 유사도를 비교해보면 더 정확하게 알 수 있을 것 같다.


각각 0.12, 0.18가량 차이가 나는 것을 확인할 수 있다. 물론 표본이 너무 적어서 일반화하기는 이르지만 성공 가능성은 보인다.

혹시나하고 구해본 두 타겟 논문 간의 유사도.
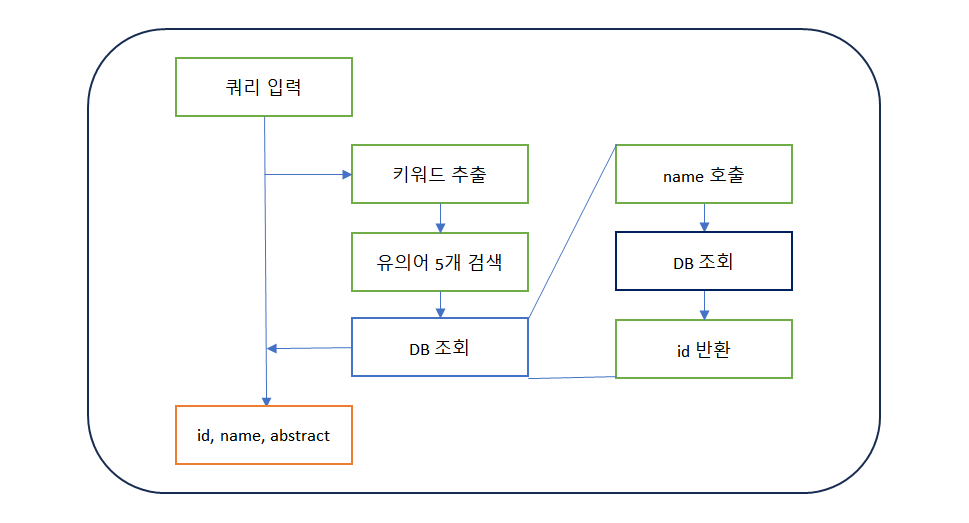
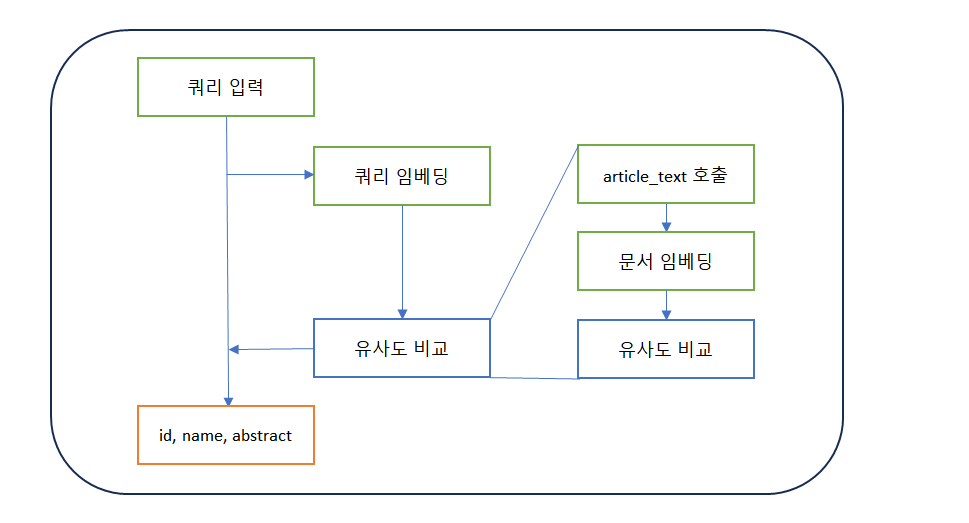
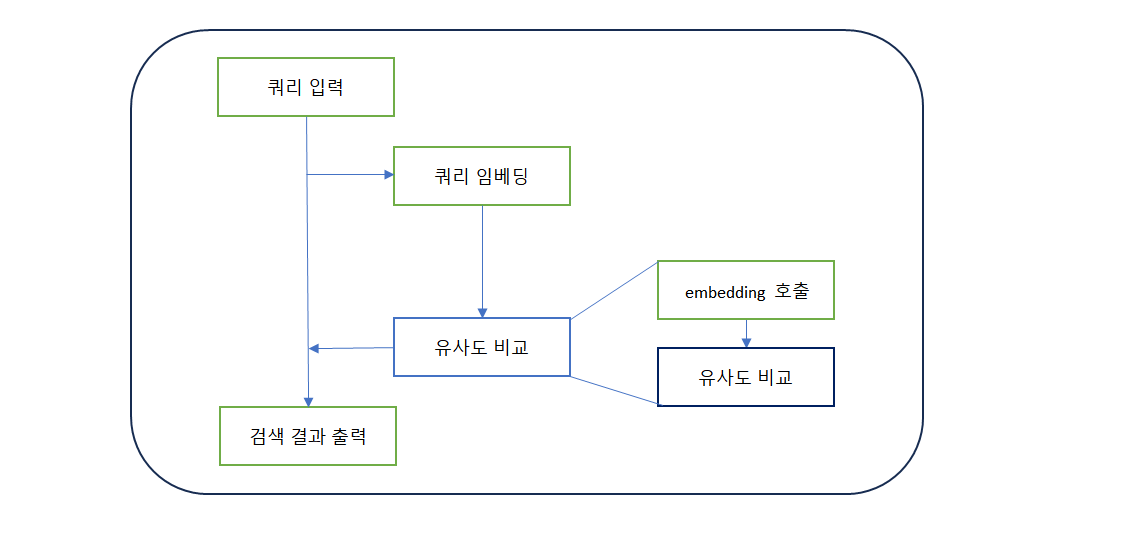
다른 검색 알고리즘 실험/검증
1. 쿼리 키워드 유사어 - 포함 논문 검색
2. 쿼리 키워드 유사어 - 문서 전체 임베딩
3. 쿼리 키워드 유사어 - 의미단위 분할 문장 임베딩

聞一知十