
TIMESTAMP
@200915 시작
@200916 Introduction~1.2.3
@200918 1.2.4~완료
Summary
Keywords
-
artificial intelligence, machine learning, deep learning
-
knowledge base, logistic regression, naive Bayes, multilayer perceptron (MLP)
-
representation, representation learning
-
autoencoder, encoder, decoder
-
feature, factors of variation
-
cybernetics, connectionism, artificial neural networks (ANNs)
-
adaptive linear element (ADALINE)
-
stochastic gradient descent
-
linear models
-
rectified linear unit
-
connectionism, parallel distributed processing
-
distributed representation
-
reinforcemnet learning
Concepts
- 모든 것은 representation의 문제이다.
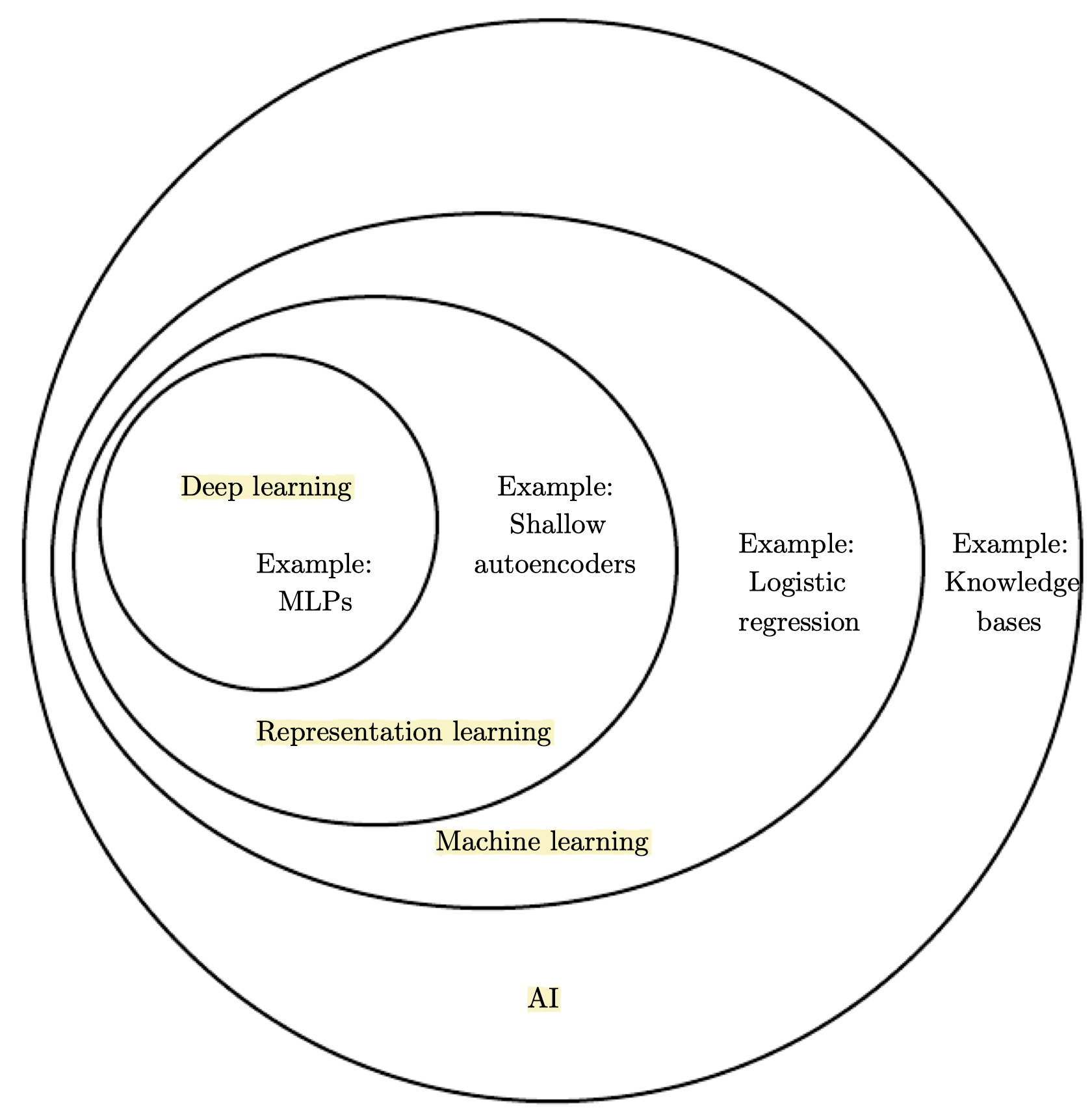
(AI -> Machine learning > Representation learning > Deep learning)
This solution is to allow computers to learn from experience and understand the world in terms of a hierarchy of concepts.
- 여기서 말하는 'Learn from experience'라는 것은 사람이 컴퓨터가 필요한 지식들을 직접 일일이 명시하지 않아도 된다는 의미이고, 'hierarchy of concepts'는 컴퓨터는 단순한 것들을 쌓아감으로써 복잡한 개념을 이해한다는 의미이다. 이때 개념들 간의 관계들을 그래프로 그린다면 깊은 층으로 구성될 것이며 이를 AI와 구별지어 딥러닝이라고 한다.
Introduction
Machine Learning and AI
- 인류는 고대 그리스 시대부터 생각하는 기계를 만들고자 했다. 오늘날에는 AI가 활발히 연구가 되고 있고, 이러한 소프트웨어를 통해 (1) 루틴한 작업들을 자동화하고 (2) 스피치나 이미지를 이해하거나 (3) 의학에서의 진단이나 과학적 연구 등에 활용되기를 기대한다.
- AI 초기에는 사람에게는 어렵지만 컴퓨터에게는 상대적으로 직관적이어 쉬운 문제들을 주로 풀었다. 대표적으로는 IBM의 딥블루 체스 게임이나 Cyc 프로젝트로, 사람이 정형화된 규칙을 컴퓨터에 명시하는 것만으로도 쉽게 풀 수 있다
- 하지만 오히려 사람들에게는 직관적이고 쉬운 문제들이 AI에게는 가장 어려운 문제일 수 있다. 음성이나 얼굴 인식과 같이 이유는 설명하기 어렵지만 사람이 쉽게 할 수 있는 것들은 주관적이고 직관적이라는 특징을 가지고 있으며, 위와 같이 정형화된 형식으로 표현하기가 어렵다.
- 컴퓨터가 이러한 것을 학습하는 것이 현재의 과제라고 할 수 있으며, 이 책 또한 이 문제들에 대한 솔루션을 다루고자 한다.
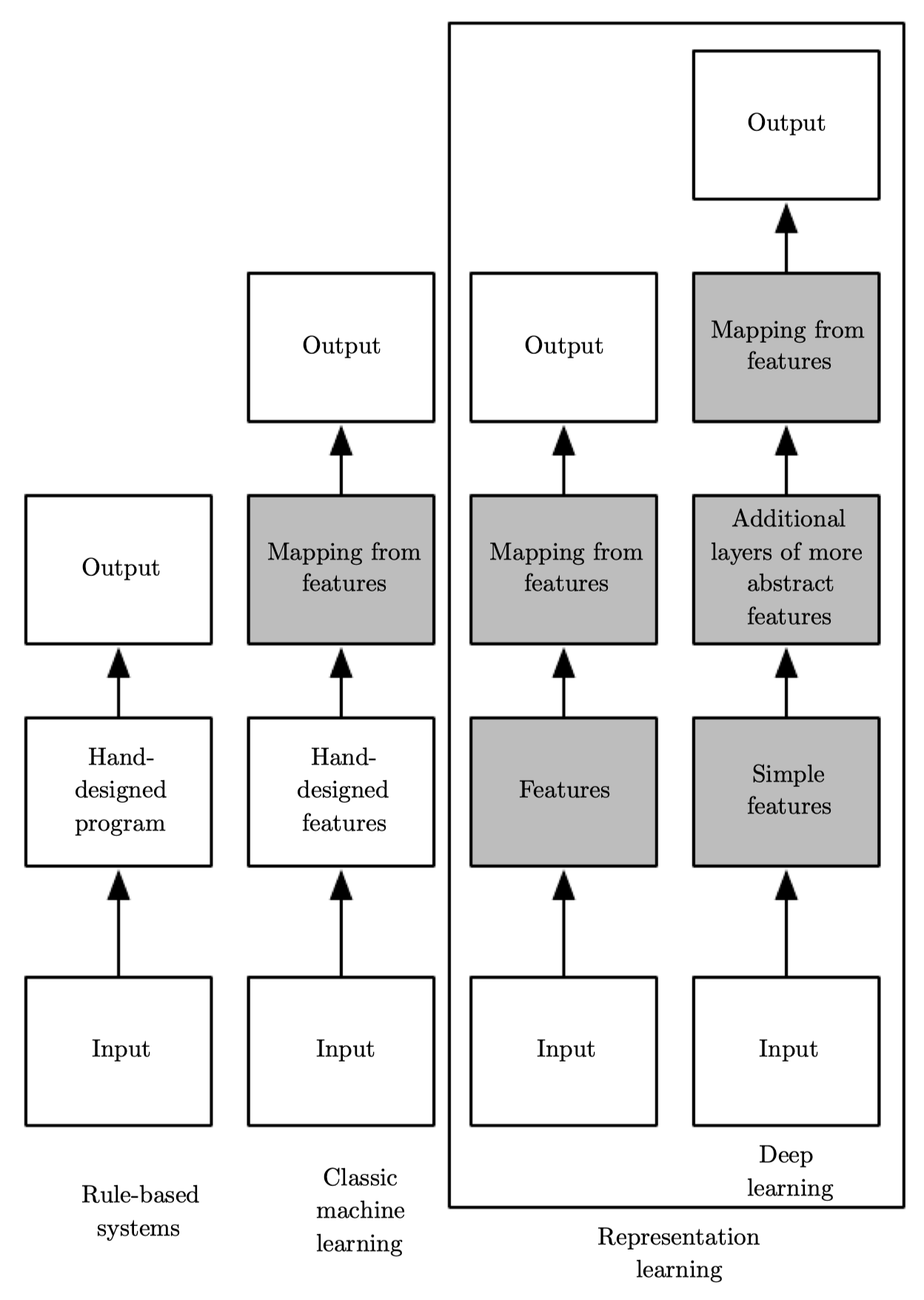
다시 정리하면, "knowledge based approach"는 사람에 의한 hard-coded knowledge를 사용하는 반면, "machine learning"을 통해서는 원 자료에서 패턴을 추출함으로써 their own knowledge를 습득한다.
Representations Matter
- 가장 간단한 머신러닝 예제로는 logistic regression, naive Bayes 등이 있다. 이때 데이터의 representation이 머신러닝의 성능을 좌우하며, 이를 feature라고도 한다. AI를 위해서는 적절한 feature를 디자인하는 것이 중요하지만, 대다수의 문제들에서는 어떤 것을 뽑아야하는지 알기 어렵다.
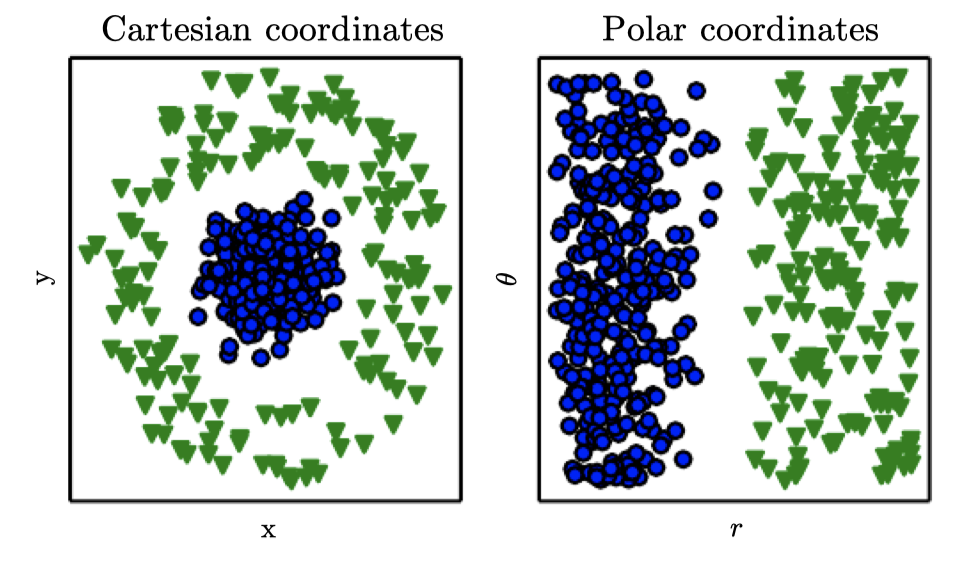
- 이때 representation learning이 사용될 수 있다. 기존의 머신러닝이 수행하던 것(주어진 representation으로부터 결과치를 찾기)에 더하여 representation 자체까지도 찾도록 하는 것이다. 직접 학습한 representation이 사람이 디자인한 것보다 더 나은 성능을 보이기도 하며, 또한 사람의 개입이 최소화되므로 새로운 문제를 푸는데도 빠르게 적용할 수 있다.
- 대표적인 예로는 오토인코더가 있다. 인코더(input -> representation)와 디코더(representation -> original)의 조합으로 구성되며, 최대한 많은 정보를 유지하는 방향으로 학습되어 새로운 representation을 만든다.
- feature을 디자인하거나 feature 자체를 학습하든 간에, 결국 데이터를 잘 설명하는 factors of variation을 분리시키는 것이 목적이다. 이때 factors라는 것은 꼭 직접적으로 관찰되는 것을 말하는 것은 아니며 다소 추상적인 형식으로 존재할 수 있다.
- 예를 들어, 녹음된 음성(화자의 연령, 성별, 악센트 등)이나 자동차 사진(위치, 색상, 각도, 햇빛 등) 다양한 factors of variation이 존재한다.
- 실제 AI 적용에서의 어려움의 주요 이유로는 이러한 factors of variation이 데이터의 모든 측면에 영향을 미치기 때문이다.
- 예를 들어 빨간색 자동차 사진이 밤에 찍힌 경우 검정색에 가까운 픽셀을 가질 것이며, 자동차의 실루엣 모양은 각도에 따라 다르다.
- AI 실제 적용을 위해서는 이렇게 복잡한 factors of variation을 풀어내는 것이 필요하다. 당연히 원자료로부터 고차원의 추상화된 features를 추출하는 것이 어려울 수 있으며, 인간 수준에 가까운 데이터에 대한 이해가 필요하다.
- 따라서 이런 문제를 풀기 위해서 적절한 representation을 찾을 수 없다면, representation learning 또한 한계가 존재한다. 이때, 딥러닝을 통해서 더욱 단순한 형태의 representation을 사용함으로써 이러한 핵심 문제를 해결할 수 있다.
Depth: Repeated Composition
-
딥러닝은 단순한 것들로부터 복잡한 개념을 구성할 수 있다. 예를 들어 아래의 그림처럼 단순화하고 이를 조합함으로써(코너, 컨투어 -> 엣지) 사람 이미지를 파악할 수 있는 것이다.
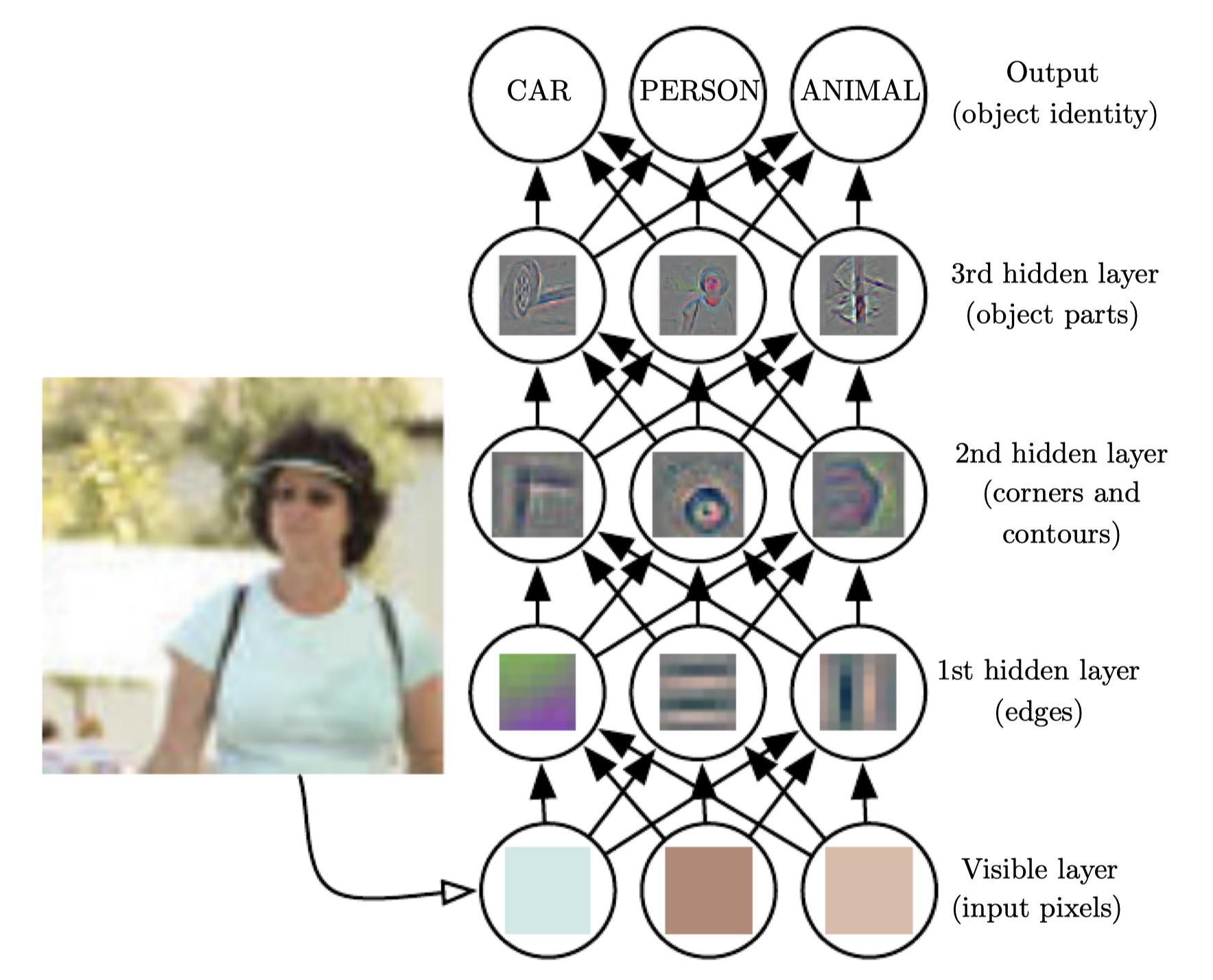
-
딥러닝의 대표적인 예로는 feedforward deep network 혹은 multilayer perceptron (MLP)가 있다. MLP는 단순히 input을 output으로 매핑하는 수학적인 함수으로, 여러개의 단순화된 functions로 구성된다. 이때 각각의 수학적인 계산을 새로운 representation으로 생각할 수 있다.
-
딥러닝을 통해 (1) 적절한 representation을 학습하는 것 외에도, (2) Depth 측면에서도 이해할 수 있다.
각 층은 다른 instruction을 병렬적으로 실행한 후의 컴퓨터 메모리 상태로 생각할 수 있다. 더 깊은 depth를 가지는 네트워크는 더 많은 instruction을 순서대로 실행할 수 있다. 순차적인 instruction은 later instruction이 이전의 결과를 다시 참조할 수 있다는 점에서 장점이 있다. 딥러닝 관점에서 본다면, 한 층의 모든 정보가 input의 factors of variation을 인코딩하지는 않는다. Representation은 또한 상태 정보를 저장하며, 이는 input을 이해할 수 있는 프로그램을 실행하는 데 도움이 된다. 상태 정보는 input과 특별히 관련이 없지만 모델을 통해 처리하는 과정에 도움이 될 수 있다.
Computational Graphs
- 모델의 depth를 구하는데는 두가지 주요 방법이 존재한다
- depth of the computational graph : input으로부터 ouput까지의 가장 긴 경로의 길이
- depth of the probabilistic modeling graph.
- 여기서 핵심은 아키텍쳐의 depth가 하나의 정확한 숫자로 정해져있지 않다는 것이며, 또한 'deep'하다는 것의 기준도 존재하지 않는다. 중요한 것은 딥러닝이 기존의 머신러닝보다 더 많은 learned functions/concepts으로 구성되어 있다는 것이다.
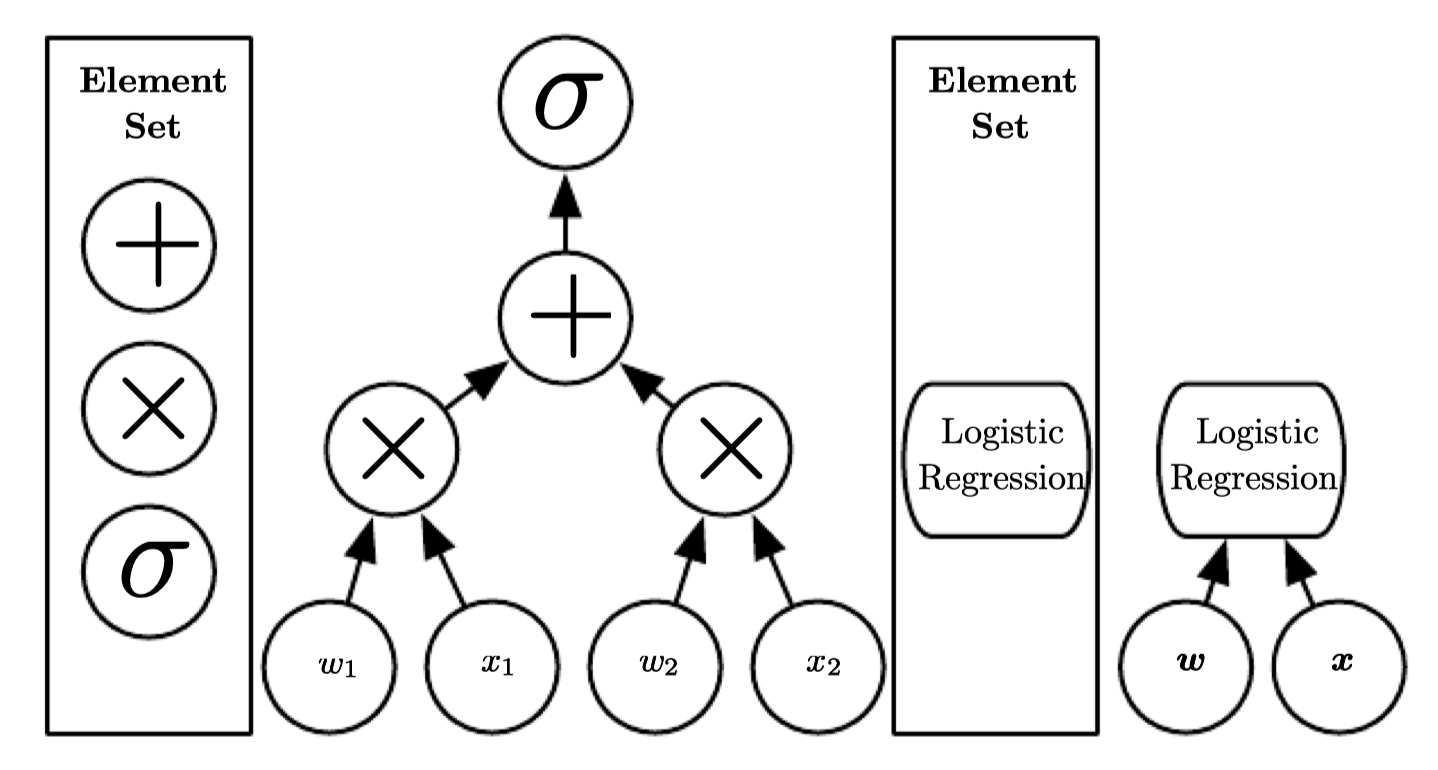
Learning Multiple Components
- 요약을 한다면, AI의 머신러닝 중 한 분야인 딥러닝은 특히 nested hierarchy of concepts의 관점에서 더 단순화 혹은 추상화된 형태로 개념을 구성하고 학습하여 좋은 성능과 유연성을 보인다.
Who should read this book?
- Prerequisite : 프로그래밍, 미적분, 복잡성 이론, 그래프 이론
- Part I : 수학(선형대수, 확률), 기초 머신러닝
- Part II : 딥러닝 알고리즘
- Part III : 딥러닝 적용 연구
Historical trends in Deep learning
- 역사적 맥락을 통해 딥러닝을 쉽게 이해할 수 있다.
- 딥러닝은 오래된 역사를 가지고 있지만, 시대마다 중요하게 여겨지는 특징을 반영하는 이름으로 달리 불리우며 인기와 쇠퇴를 반복해왔다.
- 학습 데이터 양의 증가로 인해 딥러닝이 유용해졌다.
- 컴퓨터 인프라(하드웨어, 소프트웨어)가 개선됨에 따라 딥러닝 모델 크기 또한 성장해왔다.
- 딥러닝의 정확도가 높아지면서 점차 복잡해지는 문제들을 해결하고 있다.
Historical Waves
The many names and chaning fortunes of neural networks
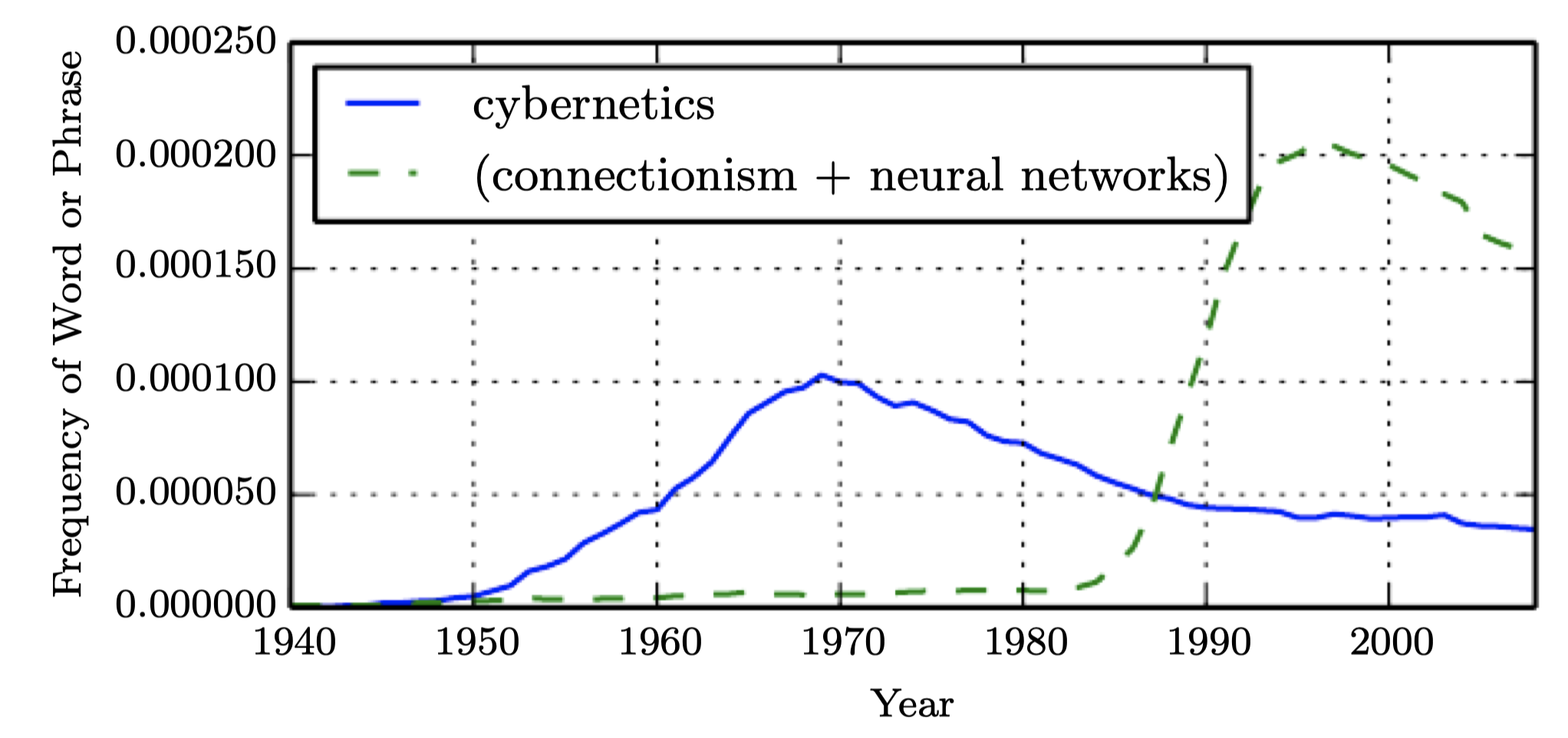
- 딥러닝이 최신 기술처럼 여겨지지만 사실 1940년대로 거슬러 올라간다. 그동안 여러 다른 이름을 거치고 최근에야 '딥러닝'이라고 불리기 때문에 새로운 것처럼 보인다. 이 분야는 그동안 각 시대의 관점과 연구자에 의해 여러번 리브랜딩이 되었다.
- 딥러닝은 그동안 세 번의 물결이 있었다.
- 4-60년대의 cybernetics
- 8-90년대의 connectionism
- 2006년부터의 deep learning
Neuroscientific perspective
-
가장 초기의 학습 알고리즘 중 일부는 생물학적 학습(뇌에서 어떻게 학습이 일어나는가)의 계산 모델을 위한 것이었다. 그 결과, artificial neural networks (ANNs)라는 이름으로 불리기도 했다. 생물학적인 뇌에서 영감을 받아 설계된 시스템이라는 관점이다. 물론 뇌 기능을 이해하는 데 사용되기도 했지만, 일반적으로는 생물학적인 기능의 모델로 설계되지는 않았다.
-
딥러닝에 대한 신경학적 관점은 두가지 주요 아이디어가 존재한다.
- 지능적인 행동이 가능하다는 증거를 뇌를 통해 제시할 수 있고, 뇌의 계산 원리를 리버스 엔지니어링하여 지능적인 시스템을 구축할 수 있다는 것이다.
- 뇌와 인간 지능의 기초가 되는 원리를 이해하는 것 자체 또한 매우 흥미롭기 때문에 다른 응용 문제를 해결하는 것과 별개로 유용할 수 있다.
-
현대에 쓰이는 '딥러닝'은 multiple levels of composition을 학습한다는 원리를 강조하는 단어로, 위의 신경과학적인 관점을 넘어서는 일반적인 개념으로 머신러닝 프레임워크 안에 적용된다.
The first wave : Cybernetics
-
신경과학의 영감을 받은 단순선형모델로, input 과 output 에 대해 weight 을 학습하고 이에 따라 예측값 을 계산한다.
-
뇌 기능의 초기 선형모델인 McCulloch-Pitts Neuron은 가 양수인지 음수인지를 통해 두 개의 그룹을 구별하는 것으로, 무엇이 적절한 가중치인지는 사람에 의해 지정되었다.
Perceptron & ADALINE
- 50년대에 제시된 Perceptron은 처음으로 가중치를 학습하는 모델이다. 이와 비슷한 시기의 adaptive linear element (ADALINE)는 실수(real number)를 예측하기 위해 값을 단순히 반환하며, 또한 데이터로부터 이러한 숫자를 예측하기 위해 학습할 수 있는 알고리즘이다.
# 참고 : 퍼셉트론과 아달라인의 비교
1. 1943년 맥컬럭과 피츠가 뇌세포를 모델링함
2. 1958년 로젠블랫이 가중치를 추가하여 퍼셉트론을 만들어냄
3. 1960년 위드로와 호프가 아달라인을 개발함
- 가중치 업데이트를 위한 활성함수가 다르다.
- 퍼셉트론의 활성함수는 순입력함수 값을 임계값을 기준으로 (+1, -1)로 분류한다.
- 아달라인의 활성함수는 순입력함수 와 실제값과의 오차인 비용함수 로 한다.
- 가중치 업데이트의 경우,
- 퍼셉트론은 예측값(-1, 1)이 실제값(-1, 1)과 다를 경우 가중치 를 업데이트한다.
- 아달라인은 비용함수가 최소화되도록 경사하강법을 통해 가중치 를 조정한다.
- [관련 링크]
- 위와 같이 간단한 학습 알고리즘은 현대의 머신러닝에 큰 영향을 미쳤다.
- 특히 아달라인에서 가중치를 조정하는 방법은 stochastic gradient descent (SGD)으로, 약간의 변형된 버전이 현재까지도 딥러닝 학습에 사용되고 있다.
- 퍼셉트론과 아달라인에 사용된 에 기반한 Linear model으로 여전히 머신러닝에서 사용되고 있다.
- Linear model은 많은 제한점을 가지며, 그 중 대표적으로 XOR function을 학습할 수 없다는 점이다. 이러한 측면에서 한때 신경과학에 기반한 학습에 비판이 가해졌고, 오늘날에도 신경과학의 역할이 축소되어 있는 것은 아직까지도 뇌에 대한 이해도가 떨어지기 때문이다.
- 그럼에도 표유류 뇌의 상당수가 하나의 알고리즘을 사용하여 여러 작업을 수행한다는 점에서, 여전히 하나의 딥러닝 알고리즘이 많은 다양한 문제들을 해결할 수 있다는 희망을 신경과학이 제시하기도 한다. 이러한 가정 이전에 머신러닝 연구는 서로 분절되고 각기 다른 커뮤니티의 연구자들이 다른 분야를 연구하는 것이 일반적이지만, 오늘날의 딥러닝 커뮤니티는 다양한 곳에 적용할 수 있는 방향으로 연구가 진행되고 있다.
[Rough guidelines form neuroscience]
- 신경 과학으로부터 대략적인 가이드라인을 그릴 수 있다.
- 많은 computational units을 가지는 기본 아이디어는 뇌에서 영감을 받았다.
- Neocognitron은 표유류 시각 시스템의 구조에서 영감을 얻어 이미지 처리 모델 아키텍쳐로 개발되었으며, 이는 나중에 현대적인 convolution network의 기초가 되었다.
- 오늘날 대부분의 신경망은 rectified linear unit이라는 모델 뉴런을 기반으로 한다.
- 최초의 Cognitron은 뇌 기능에 대한 인간의 지식을 토대로 한 좀 더 복잡한 버전이고, 단순화된 현대적인 버전은 다양한 관점에서 통합되어 개발되었다.
- 그럼에도 주의할 것은 딥러닝을 뇌를 모방하는 시도로 생각해서는 안된다. 현대 딥러닝은 선형 대수, 확률, 정보이론, 수치 최적화 등 많은 분야를 활용하고 있다.
The second wave
- connectionism 혹은 parallel distributed processing이라는 이름으로 다시 활발하게 연구되었다.
- Connectionism은 인지과학의 맥락에서 나타난 것으로, 간단한 computational units의 많은 숫자가 네트워크를 통해서 지능 행위에 도달할 수 있다는 것이 주요 아이디어이다. 이는 생물학적 신경 시스템의 neuron과 계산 모델의 hidden units로 이어진다.
- 이러한 인지과학의 움직임 속에서 나타난 주요 개념들은 오늘날의 딥러닝에도 핵심이 된다.
- Distributed representation : each input to a system should be represented by many features, and each feature should be involved in the representation of many possible inputs.
- 예를 들어, 여러 색상(빨강/초록/파랑)의 물체(자동차/트럭/새)를 인지하는 시각 시스템을 가진다고 하자. 이러한 inputs을 표현하는 방법으로는 9개의 조합을 활성화하는 각기 다른 뉴런이나 은닉 유닛을 가지게 하는 것이고, 9개의 뉴런은 서로 독립적으로 색상과 물체를 학습해야한다.
- 이를 위해서 distributed representation을 활용하여 3개의 색상 뉴런과 3개의 물체 뉴런을 만들면, 9개 아닌 6개의 뉴런만을 사용하고 또한 특정 물체의 색상을 인지하는 것이 아니라 색상 자체를 학습하게 된다.
- Distributed representation은 이 책의 핵심 개념으로, 15장(Representation learning)에 더 자세히 다뤄질 예정이다.
- Back-propagation : to train deep neural networks with internal representations
- 이 알고리즘은 인기가 상승하기도 하고 하락하기도 했지만, 현재 시점에서는 심층 모델 훈련을 가장 지배하고 있는 알고리즘이다.
- Long short-term memory (LSTM) :
- 90년대 신경망을 활용한 시퀀스 모델링이 발전했다. 호흐라이터와 벤지오는 긴 시퀀스를 모델링할 때 수학적인 어려움 몇 가지를 확인했으며(섹션 10.7), 호흐라이터와 슈미트후버는 LSTM 네트워크를 제시하여 이러한 문제를 풀고자 했다. 오늘날의 LSTM은 자연어처리와 같은 많은 문제에 활용되고 있다.
- 두 번째 물결은 90년대 중반까지 지속되며 이 분야에 대한 벤처 투자가 활발히 이루어졌지만 기대를 충족시키지 못하였고, 동시에 머신러닝이 발전되면서 2007년까지 신경망의 인기가 감소하였다.
- 이 기간 동안 신경망은 계속해서 발전해왔으며 (LeCun et al., 1998b; Bengio et al., 2001), CIFAR (Canadian Institute for Advanced Research)은 NCAP (Neural Computation and Adaptive Perception) 연구 이니셔티브를 통해 신경망 연구를 유지하였다.
- 이 프로그램은 토론토 대학의 제프리 힌튼, 몬트리올 대학의 조슈아 벤지오, 뉴욕 대학의 얀 르쿤이 이끄는 머신러닝 연구 그룹을 통합하였으며, CIFAR NCAP 연구 이니셔티브는 인간 및 컴퓨터 비전 분야의 전문가와 신경과학자를 포함하는 다학제적 성격을 가졌다.
- 지금에서야 80년대 이후의 알고리즘이 잘 작동된다는 것을 알지만 2006년까지만 하더라도 당시의 하드웨어로는 deep network를 일반적으로 훈련하기가 매우 어렵다고 여겨졌다.
The third wave
- 세번째 물결은 2006년의 연구로 시작되었다.
- 힌튼은 심층망의 일종인 deep belief network가 greedy layer-wise pre-training이라는 방법을 통해 효과적으로 학습될 수 있다는 것을 보였다(섹션 15.1).
- 다른 CIFAR 연구 그룹은 동일한 방법이 다른 많은 deep network에도 사용될 수 있다는 것을 보여 빠르게 일반화를 진행할 수 있었다.
- 이러한 흐름 속에서 다음과 같은 이유를 강조하기 위해 "딥러닝"이라는 용어를 대중화하였다.
(1) 이전보다 더 깊은 신경망을 훈련시킬 수 있다는 것
(2) Depth의 이론적인 중요성 - 당시 심층신경망의 성능은 다른 머신러닝 기법에 기반한 AI 시스템을 뛰어넘었고, 신경망의 대중화는 지금까지도 계속되고 있다.
- 딥러닝 연구의 포커스는 이 기간동안 급격하게 변화하였다. 사실 세 번째 물결은 새로운 비지도 학습기술과 작은 데이터셋에서 잘 일반화할 수 있는 심층모델에 초점을 맞추면서 시작이 되었지만, 오늘날에는 훨씬 오래된 지도학습 알고리즘과 대규모 레이블된 데이터를 활용하는 것에 더 많은 관심을 받고 있다.
Historical Trends: Growing Datasets
Increasing dataset sizes
- 이미 50년대에 인공신경망에 대해서 실험이 시작되었지만 왜 최근에서야 중요한 기술로 여겨지는지 궁금할 것이다. 딥러닝은 90년대부터 상업적인 응용에 성공적으로 사용되었지만 기술보다는 예술로 여겨지고 전문가만이 사용할 수 있는 것으로 여겨졌다.
- 딥러닝 알고리즘에서 좋은 성능을 내기 위해서는 기술이 필요한 것은 사실이지만 학습 데이터셋이 많아질수록 요구되는 기술의 양이 줄어든다. 오늘날 복잡한 문제에서 인간의 성능에 도달하는 학습 알고리즘은 사실 80년대에 toy problem를 해결하기 위해 고군분투했던 것과 거의 동일하다 (매우 깊은 심층 아키텍쳐 학습을 단순화하는 변경을 거치긴 했지만).
- 가장 중요한 새로운 발전은 성공적으로 알고리즘을 활용하는데 필요한 리소스가 충족된다는 것이다. 벤치마크 데이터셋의 크기가 사회의 디지털화에 따라 얼마나 크게 증가했는지 아래 그림을 통해 확인할 수 있다.
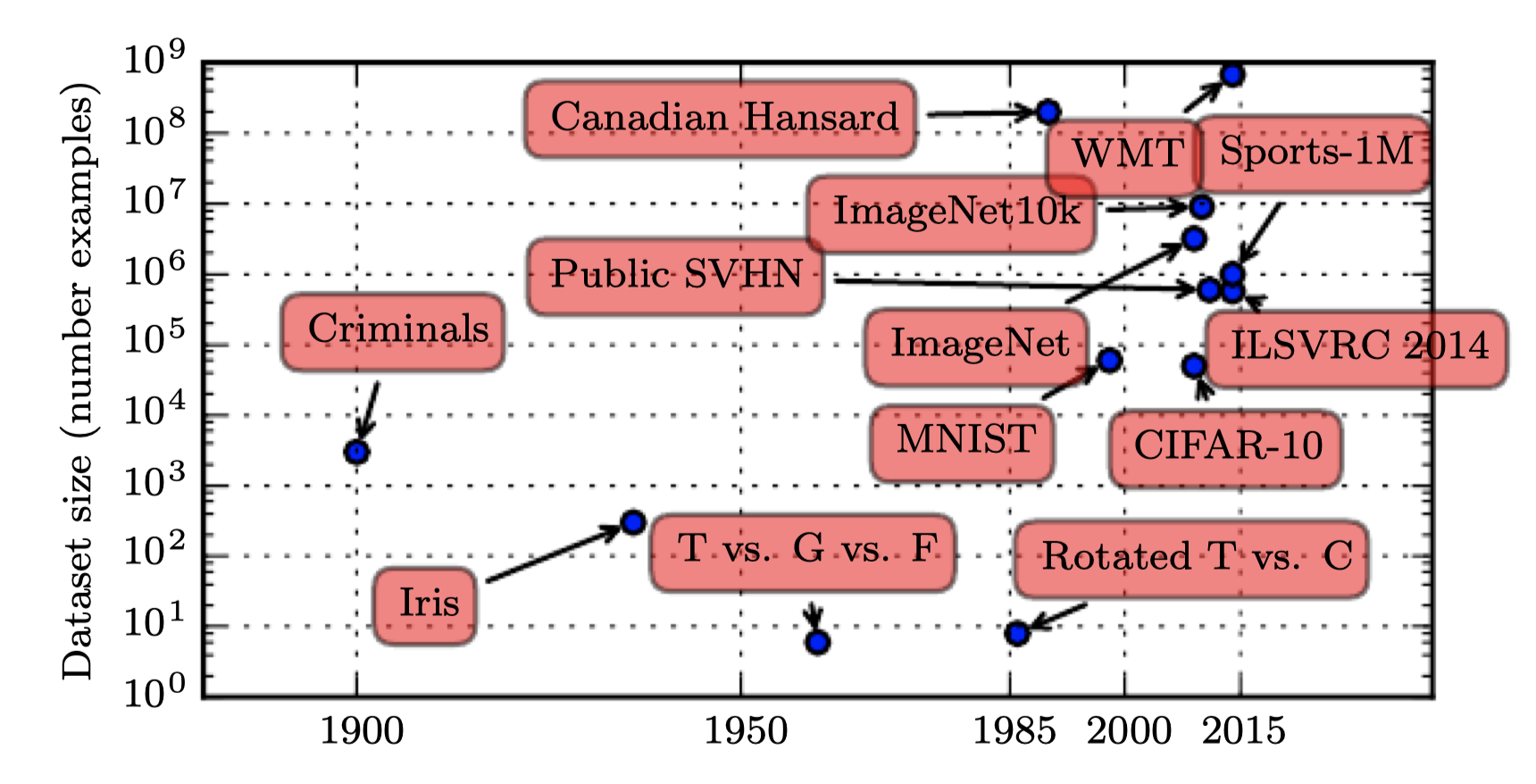
- 점차 더 많은 활동이 컴퓨터에서 이뤄짐에 따라 우리가 하는 것들이 더 많이 기록될 수 있다. 컴퓨터가 점차 네트워크로 연결됨에 따라 이러한 기록을 중앙 집중화하고 머신러닝 응용에 적합한 데이터셋으로 큐레이팅하는 것이 쉬워졌다.
- 빅데이터 시대의 머신러닝은 더욱 쉬워진다. 통계적 추정의 주요 과제(작은 수의 데이터만을 보고 새로운 데이터에 일반화하는 것)의 부담이 적어졌기 때문이다.
- 2016년 기준으로 대략적인 경험의 법칙에 의하면 지도학습형 딥러닝 알고리즘이 일반적으로 (1) 5000개 근처의 데이터라면 괜찮은 성능(acceptable)을 달성하고, (2) 1000만개 이상이라면 사람의 성능에 도달하거나 그 이상이라는 것이다.
- 이보다 더 작은 데이터셋으로도 성공적으로 학습하는 것은 중요한 연구 영역이며, 특히 비지도/준지도 학습을 통해 레이블되지 않은 데이터를 활용할 수 있는 방법에 초점을 맞추고 있다.
The MNIST Dataset

- NIST란 National Institute of Standards and Technology의 약자로, 이 데이터를 모은 곳이다. M은 'modified'로, 머신러닝 알고리즘에 손쉽게 사용하기 위해서 전처리된 데이터이다.
- MNIST는 손글씨 숫자로 이루어져있으며, 제프리 힌튼은 "the drosophila of machine learning"이라고 묘사했다.
Connections per Neuron
Increasing model sizes
- 80년대 이후의 작은 성공 이후에 오늘날 신경망이 크게 성공한 또 다른 이유는 현대의 컴퓨팅 리소스를 통해 더 큰 모델을 실행할 수 있기 때문이다.
- Connectionism에서 중요한 것 중 하나는 지능적인 동물이 되기 위해서는 많은 뉴런이 함께 작동되어야 한다는 것이다. 개별 뉴런이나 작은 뉴런의 모음은 딱히 유용하지는 않다.
- 생물학적 뉴런은 특별히 조밀하게 연결되어 있지는 않다. 아래 그림처럼, 머신러닝 모델의 뉴런은 수십 년동안 표유류 뇌의 크기에 해당하는 정도의 다수의 연결을 가지고 있다.
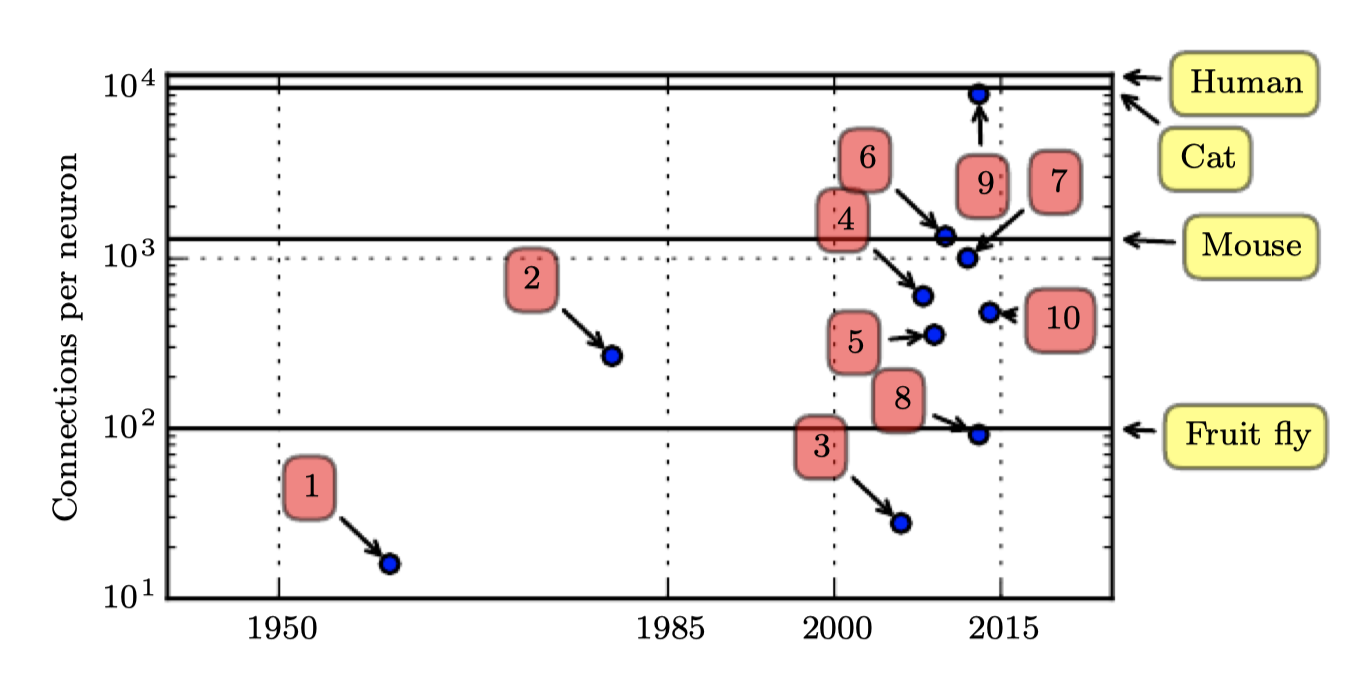
Number of Neurons
- 뉴런의 총 갯수 측면에서 신경망은 아래 그림과 같이 최근까지도 놀라울 정도로 적었다. 은닉층의 도입으로, 인공신경망은 2.4년마다 두배씩 사이즈가 증가했다. 이러한 성장은 메모리의 증가에 의한 더 빠른 컴퓨터와 더 큰 데이터셋에 의한 것으로, 더 큰 네트워크를 통해서 복잡한 문제에서 높은 정확도를 달성할 수 있다. 이러한 트렌드는 수십 년동안 계속될 것이며, 새로운 기술이 더 빠르게 확장하지 않는 한, 적어도 2050년대까지 인공신경망은 사람 뇌와 같은 숫자의 뉴런을 가지지는 못할 것이다.
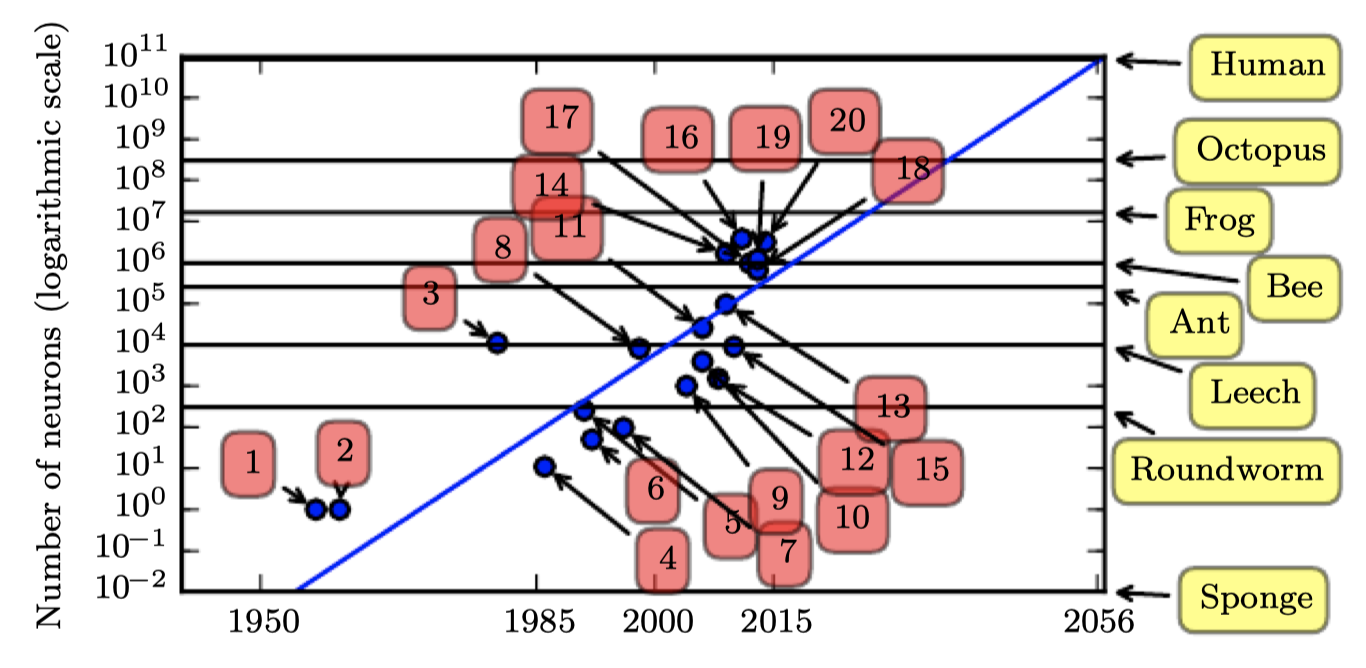
- 돌이켜 보면, 거머리보다 더 적은 수의 뉴런을 가지는 신경망이 복잡한 AI 문제를 풀 수 없었던 것은 당연하다. 오늘날까지도 현재의 네트워크는 개구리와 같은 동물의 신경계보다 작다.
- 시간에 따라 모델의 크기가 증가하는 것은 딥러닝 역사에서 다음과 같은 이유들로 가장 중요한 트렌드 중에 하나이며, 계속해서 이러한 추세가 진행될 것이다.
- 더 빠른 CPUs의 사용
- 일반적인 용도의 GPU 출현
- 더 빠른 네트워크 연결성
- 분산컴퓨팅을 위한 소프트웨어 인프라
Solving Object Recognition
Increasing accuracy, complexity, and real-world impact
- 80년대부터 딥러닝은 물체 인식이나 예측에서 계속해서 정확도 향상을 해왔으며, 더 많은 문제에 응용되고 있다.
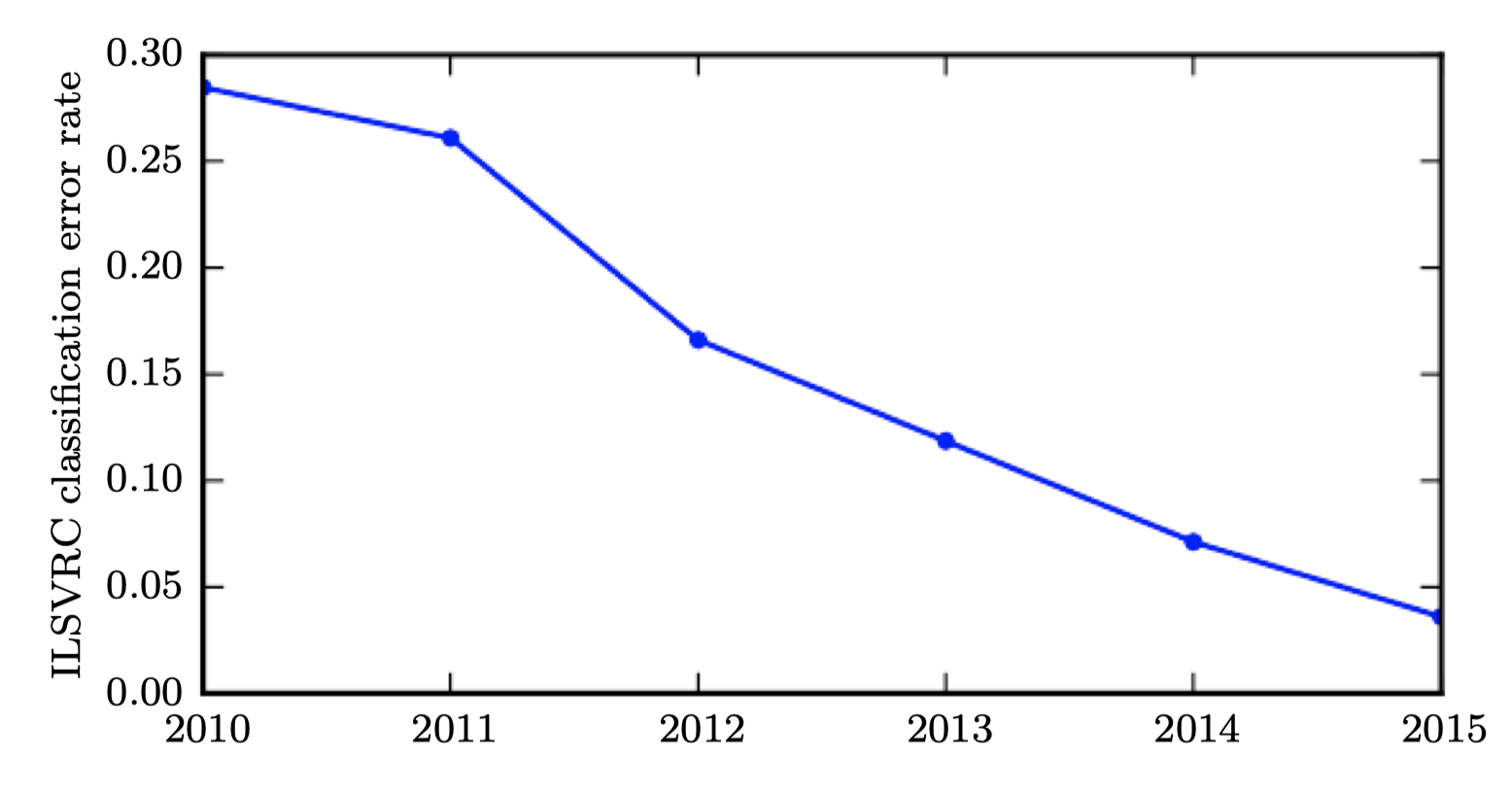
- 가장 초기의 심층모델은 작은 이미지에서 개별 물체를 인지하는 것이었다. 그 이후로 신경망이 처리할 수 있는 이미지의 크기가 커져왔다. 현대의 물체인식 네트워크는 고해상도의 사진을 처리하고 이를 위해서 자르는 등의 과정이 필요하지 않다.
- 이와 비슷하게 가장 초기의 네트워크는 두 가지 종류의 물체를 인식할 수 있었지만, 현대의 네트워크는 최소 1000개의 각기 다른 카테고리를 인식할 수 있다. 물체인식에서 가장 큰 대회는 매년 열리는 ImageNet Larget Scale Visual Recognition Challenge (ILSVRC)이다. 딥러닝의 폭발적인 증가의 순간은 컨볼루션 네트워크가 이 대회에서 처음으로 우승했을 때이다. top-5 error rate이 26.1%에서 15.3%으로 감소하였고, 15.3% 외에도 모든 테스트셋에서 가능한 상위 5가지의 카테고리에 정답이 존재했다. 그 이후로 이러한 대회에서는 계속해서 딥컨볼루션 네트워크가 우승하였으며 top-5 error rate은 책 저술 기준으로 3.6%까지 감소했다.
- 딥러닝은 음성 인식에도 큰 영향을 미쳤다. 90년대동안의 발전 이후 error rate가 개선되지 않는 듯했지만, 딥러닝의 적용으로 절반까지로 낮추는 등 획기적으로 성능을 개선했다(섹션 12.3).
- 심층 네트워크는 보행자 감지와 이미지 분할에도 성공적으로 신호 분류에서는 인간을 넘어선 수준의 성능을 보인다.
- 심층 네트워크의 규모와 정확도가 증가함과 동시에, 점차 더 많은 복잡한 문제를 풀 수 있게 되었다. 2014년 굿펠로우는 단순히 단일 물체를 인지하는 것이 아니라 이미지로부터 전체 문자열을 내뱉도록 학습시킬 수 있음을 보였다(이전에는 이러한 종류의 학습을 위해서는 시퀀스의 개별 요소를 라벨링해야한다고 생각했다). 위의 언급된 LSTM 시퀀스 모델 같은 순환신경망은 단순히 고정된 인풋 외에도 시퀀스와 다른 시퀀스 간의 관계를 모델링 하는데 사용된다. 이와 같은 시퀀스-시퀀스 학습은 다른 응용에 혁신을 가져오는 첨단 기술으로 보인다(기계 번역)
- 이러한 복잡성 증가 추세는 메모리 셀에서 읽고 임의의 내용을 메모리 셀에 쓰는 법을 배우는 신경 튜링 머신의 도입으로 논리적 결론으로 밀려났다. 이러한 신경망은 원하는 행동의 예들로부터 간단한 프로그램을 학습 할 수 있다.
- 예를 들어, 시퀀스의 예시(섞인 형태, 정렬된 상태)를 통해 숫자 목록을 정렬하는 방법을 배울 수 있다. 이렇게 self-programming 기술은 초기 단계이지만, 미래에는 거의 모든 작업에 원칙적으로는 적용될 수 있다.
- 또 다른 딥러닝의 성과는 강화학습으로 확장되었다는 점이다. 강화학습의 측면에서는 사람의 가이드 없이 시행착오를 통해 해당 작업을 수행하는 방법을 학습하게 된다. 딥마인드는 비디오게임을 학습하고 많은 문제에서 사람 수준의 성능을 보이는 딥러닝 기반의 강화학습 시스템을 선보였다. 또한 딥러닝은 로보틱스에도 강화학습 성능을 증가시켰다.
- 딥러닝의 응용은 상당히 수익성이 높다. 현재 구글, 마이크로소프트, 페이스북, IBM, 바이두, 애플, 어도비, 넷플릭스, 엔비디아, NEC와 같은 기업들은 딥러닝을 사용하고 있다. 딥러닝의 발전은 소프트웨어 인프라 발전으로부터 많은 영향을 받는다. Theano, PyLearn2, Torch, DistBelief, Caffe, MXNet, Tensorflow와 같은 라이브러리는 중요한 연구 프로젝트나 상업적인 제품에 사용된다. 딥러닝은 또한 다른 과학 분야에도 기여하고 있다. 물체인식을 위한 현대 컨볼루션 네트워크는 신경과학자들이 연구할 수 있는 시각처리 모델을 제공한다. 딥러닝은 또한 엄청난 양의 데이터를 처리하고 의미있는 예측을 하는데 유용하다(어떻게 분자들이 서로 상호작용하는지 예측하는 것을 통해 제약회사가 신약을 디자인하는데 도움을 주는 등).
요악을 하자면 딥러닝은 머신러닝 중 한 분야로, 최근 몇 년동안 더 강력한 컴퓨터, 큰 데이터셋, 그리고 더 깊은 네트워크를 학습하기 위한 기술들의 발전으로 인해서 대중성과 유용성이 커졌다.
