YOLO
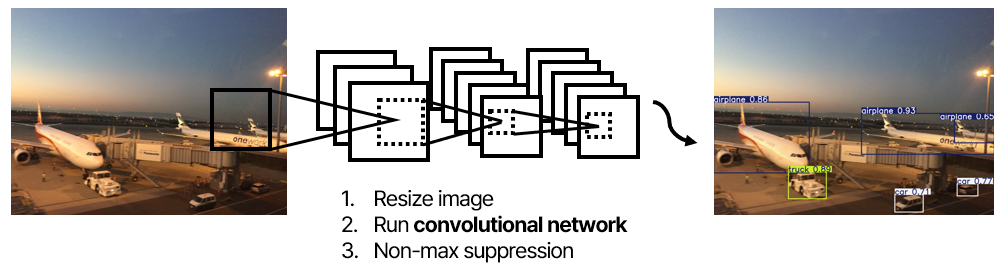
YOLO 이전 모델들은 이미지를 여러 번에 걸쳐 확인해서 이미지를 처리할 때 많은 시간이 걸렸다. 하지만 YOLO는 이미지를 한번 보고도 바로 객체를 검출할 수 있어서 실시간으로 빠르게 객체를 탐지할 수 있다.
YOLOv4
https://velog.io/@chehun1216/YOLOv4-Optimal-Speed-and-Accuracy-of-Object-Detection
YOLOv5
2020년 6월에 발표되었고 paper 없이 코드만 공개되었다. backbone을 depth multiple과 width multiple을 기준으로 하여 크기별로 s, m, l, x로 나누어져 있다.
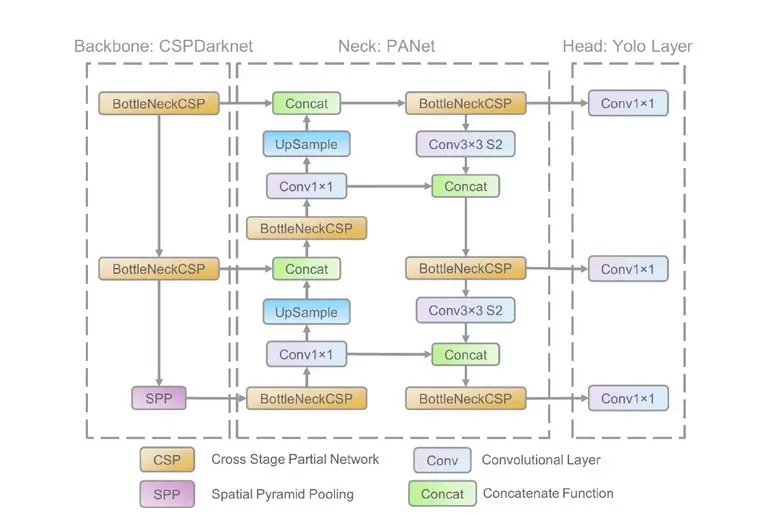
- Backbone: CSPDarknet53 (New)
- Neck: SPPF, PANet
- Head: YOLOv4
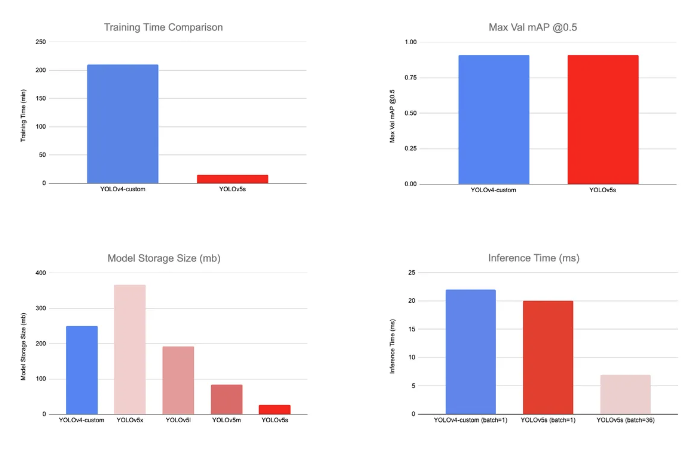
V4 vs. V5 성능 비교
YOLOv8
2023년 1월에 발표되었고 paper 없이 코드만 공개되었다.
YOLOv8은 pip 패키지로 새로운 인터페이스를 제공하였다. Object detection과 Instance segmentation 위주로 새로운 기술들이 업데이트 되었다.
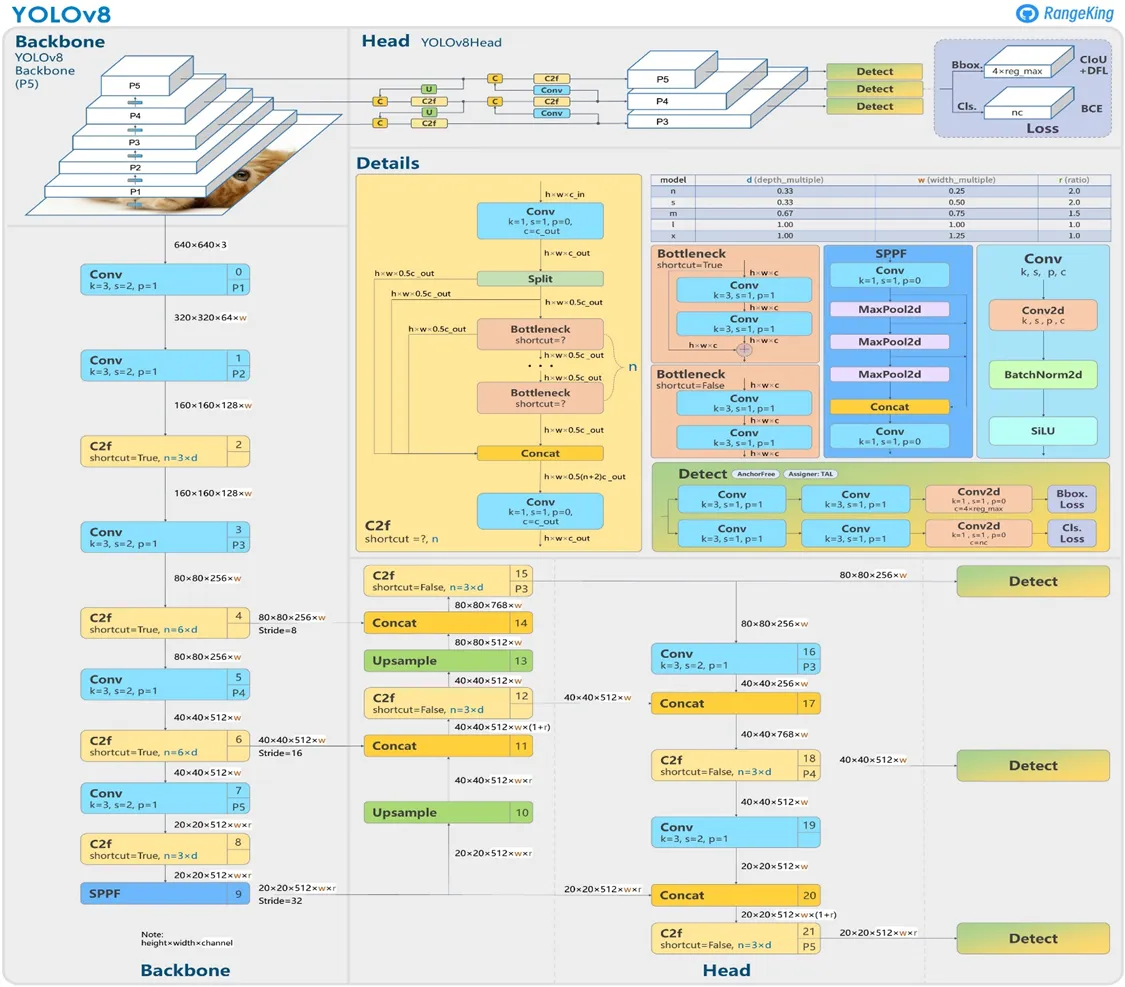
Anchor Free Detection이 사용되었다. Anchor 박스의 offset 대신에 객체의 중심을 직접 예측하였다. 이로 인해 NMS의 속도가 빨라졌다.
YOLOv8-seg, YOLOv8-pose, YOLOv8-obb, YOLOv8-cls 의 모델들이 있어 추론, 검증, 탐지, 분류 등 다양한 운영 모드와 호환되었다.
YOLOv5 → YOLOv8 변화
Anchor-based ➡️ Anchor-free
다른 모델들은 Bounding box의 꼭짓점을 라벨링하는데, YOLO는 anchor box가 있어서 중심점으로부터의 aspect ratio와 scale을 라벨링했었다.
Anchor-based
기존 object detection 아키텍처들은 정확도를 높이기 위해 사전에 anchor를 생성하였다. 전제 조건이 없는 상태에서 물체의 위치와 크기를 학습하기 보다는, 대부분 물체들은 어느정도 일반적인 형태를 가지고 있으므로 anchor를 미리 정의한 후 그로부터 regression을 하면, 빠르게 학습하면서 정확하게 물체를 탐지할 수 있다.
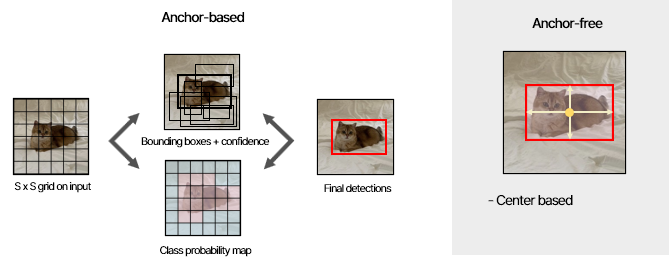
Anchor는 특정 aspect ratio를 가진 객체를 탐지하기 위해 다양한 크기와 비율로 미리 정의해놓은 bounding box이다.
이미지 전체를 SxS grid로 나누고, 각 grid에서 디자인한 B개의 anchor box에 해당하는 feature를 뽑아 network에 input으로 넣어준다. 이후 모델이 각 anchor box마다 객체일 확률, 배경일 확률, 위치 (class probability, bounding box offsets) 등을 예측하고 각 anchor box의 모양과 위치를 세부적으로 조절한다.
Anchor-based의 한계
하지만 Anchor-based detection에서는 inductive bias가 낮다는 한계점이 있었다. 학습 데이터 안에 포함되지 않은 특징을 가진 새로운 데이터를 예측할 때, 해당 데이터는 미리 설계한 anchor box로 예측을 하면 성능이 매우 떨어지게 된다.
또한 computation cost가 높다. 다양한 크기와 비율을 가진 객체를 탐지하기 위해 보통 2개 이상의 anchor를 사용하는데, anchor가 늘어날 수록 anchor가 만들어내는 feature가 많아져서 cost가 커진다. 또한 GT와 prediction을 비교하는 IoU computation도 크게 늘어난다. 그리고 하나의 target에 대해 여러 개의 anchor가 positive sample로 매칭되는데, inference할 때도 마찬가지로 하나의 object에 대해 여러 개의 prediction을 수행하므로 중복된 box를 제거하는 Non-maximum Suppression (NMS) 수행을 필요로 한다.
Anchor-free
따라서 Anchor를 사용하지 않고 객체를 탐지하는 방법이 제안되었다.
Keypoint-based method와 Center-based method가 있다.
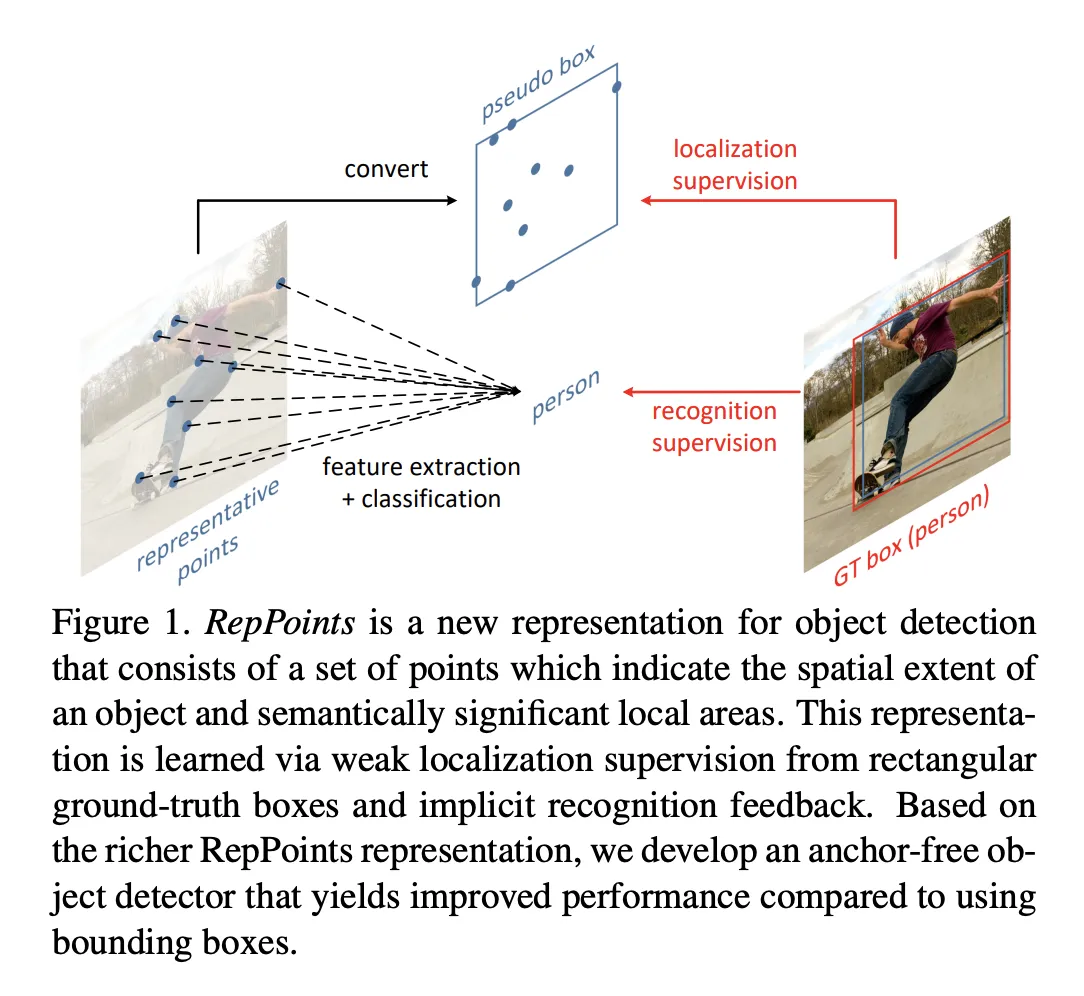
Keypoint-based method는 먼저 여러 개의 점이 미리 정의되거나 자체 학습된 keypoint를 찾은 다음 객체의 공간 범위를 제한하는 방법이다.

Center-based method는 객체의 중심점 또는 영역을 사용하여 야의 값을 정의한 다음, 양의 값에서 객체 경계까지의 네 가지 거리를 예측하는 방법이다.
YOLOv8은 anchor box를 사용하지 않아서 일반적인 좌표값만 넣으면 인스턴스의 중심을 직접 예측하여 aspect ratio와 scale을 구할 수 있게 되었다.
모델의 아키텍처와 computational overhead를 줄여서 inference time이 빨라진다. 또한 물체가 작은 경우나 물체가 많이 밀집된 경우를 잘 탐지할 수 있다.
Mosaic augmentation 삭제
Mosaic는 YOLOv4에서 처음 제안되었던 데이터 증강 방법인데, 이미지 4장을 합쳐서 4장을 한 번에 보는 효과가 있었다. Memory를 절약하는 장점이 있었지만, YOLOv8에서는 오히려 제한 없이 증강을 하면 학습 성능이 저하된다는 것을 발견하였다.
